Harvard architecture
The Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data. It is often contrasted with the von Neumann architecture, where program instructions and data share the same memory and pathways.
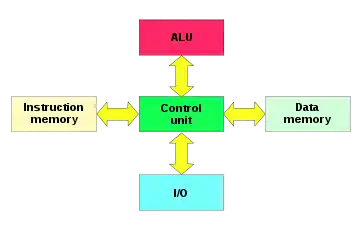
The term is often stated as having originated from the Harvard Mark I relay-based computer, which stored instructions on punched tape (24 bits wide) and data in electro-mechanical counters. These early machines had data storage entirely contained within the central processing unit, and provided no access to the instruction storage as data. Programs needed to be loaded by an operator; the processor could not initialize itself. However, in the only peer-reviewed published paper on the topic - The Myth of the Harvard Architecture published in the IEEE Annals of the History of Computing[1] - the author demonstrates that:
- 'The term “Harvard architecture” was coined decades later, in the context of microcontroller design' and only 'retrospectively applied to the Harvard machines and subsequently applied to RISC microprocessors with separated caches'
- 'The so-called “Harvard” and “von Neumann” architectures are often portrayed as a dichotomy, but the various devices labeled as the former have far more in common with the latter than they do with each other.'
- 'In short [the Harvard architecture] isn't an architecture and didn't derive from work at Harvard.'
Modern processors appear to the user to be systems with von Neumann architectures, with the program code stored in the same main memory as the data. For performance reasons, internally and largely invisible to the user, most designs have separate processor caches for the instructions and data, with separate pathways into the processor for each. This is one form of what is known as the modified Harvard architecture.
Harvard architecture is historically, and traditionally, split into two address spaces, but having three, i.e. two extra (and all accessed in each cycle) is also done,[2] while rare.
Memory details
In a Harvard architecture, there is no need to make the two memories share characteristics. In particular, the word width, timing, implementation technology, and memory address structure can differ. In some systems, instructions for pre-programmed tasks can be stored in read-only memory while data memory generally requires read-write memory. In some systems, there is much more instruction memory than data memory so instruction addresses are wider than data addresses.
Contrast with von Neumann architectures
In a system with a pure von Neumann architecture, instructions and data are stored in the same memory, so instructions are fetched over the same data path used to fetch data. This means that a CPU cannot simultaneously read an instruction and read or write data from or to the memory. In a computer using the Harvard architecture, the CPU can both read an instruction and perform a data memory access at the same time,[3] even without a cache. A Harvard architecture computer can thus be faster for a given circuit complexity because instruction fetches and data access do not contend for a single memory pathway.
Also, a Harvard architecture machine has distinct code and data address spaces: instruction address zero is not the same as data address zero. Instruction address zero might identify a twenty-four-bit value, while data address zero might indicate an eight-bit byte that is not part of that twenty-four-bit value.
Contrast with modified Harvard architecture
A modified Harvard architecture machine is very much like a Harvard architecture machine, but it relaxes the strict separation between instruction and data while still letting the CPU concurrently access two (or more) memory buses. The most common modification includes separate instruction and data caches backed by a common address space. While the CPU executes from cache, it acts as a pure Harvard machine. When accessing backing memory, it acts like a von Neumann machine (where code can be moved around like data, which is a powerful technique). This modification is widespread in modern processors, such as the ARM architecture, Power ISA and x86 processors. It is sometimes loosely called a Harvard architecture, overlooking the fact that it is actually "modified".
Another modification provides a pathway between the instruction memory (such as ROM or flash memory) and the CPU to allow words from the instruction memory to be treated as read-only data. This technique is used in some microcontrollers, including the Atmel AVR. This allows constant data, such as text strings or function tables, to be accessed without first having to be copied into data memory, preserving scarce (and power-hungry) data memory for read/write variables. Special machine language instructions are provided to read data from the instruction memory, or the instruction memory can be accessed using a peripheral interface.[lower-alpha 1] (This is distinct from instructions which themselves embed constant data, although for individual constants the two mechanisms can substitute for each other.)
Speed
In recent years, the speed of the CPU has grown many times in comparison to the access speed of the main memory. Care needs to be taken to reduce the number of times main memory is accessed in order to maintain performance. If, for instance, every instruction run in the CPU requires an access to memory, the computer gains nothing for increased CPU speed—a problem referred to as being memory bound.
It is possible to make extremely fast memory, but this is only practical for small amounts of memory for cost, power and signal routing reasons. The solution is to provide a small amount of very fast memory known as a CPU cache which holds recently accessed data. As long as the data that the CPU needs is in the cache, the performance is much higher than it is when the CPU has to get the data from the main memory. On the other side, however, it may still be limited to storing repetitive programs or data and still has a storage size limitation, and other potential problems associated with it.[lower-alpha 2]
Internal vs. external design
Modern high performance CPU chip designs incorporate aspects of both Harvard and von Neumann architecture. In particular, the "split cache" version of the modified Harvard architecture is very common. CPU cache memory is divided into an instruction cache and a data cache. Harvard architecture is used as the CPU accesses the cache. In the case of a cache miss, however, the data is retrieved from the main memory, which is not formally divided into separate instruction and data sections, although it may well have separate memory controllers used for concurrent access to RAM, ROM and (NOR) flash memory.
Thus, while a von Neumann architecture is visible in some contexts, such as when data and code come through the same memory controller, the hardware implementation gains the efficiencies of the Harvard architecture for cache accesses and at least some main memory accesses.
In addition, CPUs often have write buffers which let CPUs proceed after writes to non-cached regions. The von Neumann nature of memory is then visible when instructions are written as data by the CPU and software must ensure that the caches (data and instruction) and write buffer are synchronized before trying to execute those just-written instructions.
Modern uses of the Harvard architecture
The principal advantage of the pure Harvard architecture—simultaneous access to more than one memory system—has been reduced by modified Harvard processors using modern CPU cache systems. Relatively pure Harvard architecture machines are used mostly in applications where trade-offs, like the cost and power savings from omitting caches, outweigh the programming penalties from featuring distinct code and data address spaces.
- Digital signal processors (DSPs) generally execute small, highly optimized audio or video processing algorithms. They avoid caches because their behavior must be extremely reproducible. The difficulties of coping with multiple address spaces are of secondary concern to speed of execution. Consequently, some DSPs feature multiple data memories in distinct address spaces to facilitate SIMD and VLIW processing. Texas Instruments TMS320 C55x processors, for one example, feature multiple parallel data buses (two write, three read) and one instruction bus.
- Microcontrollers are characterized by having small amounts of program (flash memory) and data (SRAM) memory, and take advantage of the Harvard architecture to speed processing by concurrent instruction and data access. The separate storage means the program and data memories may feature different bit widths, for example using 16-bit-wide instructions and 8-bit-wide data. They also mean that instruction prefetch can be performed in parallel with other activities. Examples include the PIC by Microchip Technology, Inc. and the AVR by Atmel Corp (now part of Microchip Technology).
Even in these cases, it is common to employ special instructions in order to access program memory as though it were data for read-only tables, or for reprogramming; those processors are modified Harvard architecture processors.
Notes
- The IAP lines of 8051-compatible microcontrollers from STC have dual ported Flash memory, with one of the two ports hooked to the instruction bus of the processor core, and the other port made available in the special function register region.
- As in a well described case of Intel 80486.[4]: 26–34 [5]
References
- Pawson, Richard (30 September 2022). "The Myth of the Harvard Architecture". IEEE Annals of the History of Computing. 44 (3): 59–69. doi:10.1109/MAHC.2022.3175612. S2CID 252018052.
- "Kalimba DSP: User guide" (PDF). July 2006. p. 18. Retrieved 2022-09-23.
this is a three-bank Harvard architecture.
- "386 vs. 030: the Crowded Fast Lane". Dr. Dobb's Journal, January 1988.
- Brown, John Forrest (1994). Embedded systems programming in C and Assembly. New York: Van Nostrand Reinhold. ISBN 0-442-01817-7. OCLC 28966593.
- "Embedded Systems Programming: Perils of the PC Cache". users.ece.cmu.edu. Archived from the original on January 15, 2020. Retrieved 2022-05-26.