TRIPS architecture
TRIPS was a microprocessor architecture designed by a team at the University of Texas at Austin in conjunction with IBM, Intel, and Sun Microsystems. TRIPS uses an instruction set architecture designed to be easily broken down into large groups of instructions (Graphs) that can be run on independent processing elements. The design collects related data into the graphs, attempting to avoid expensive data reads and writes and keeping the data in high speed memory close to the processing elements. The prototype TRIPS processor contains 16 such elements. TRIPS hoped to reach 1 TFLOP on a single processor, as papers were published from 2003 to 2006.[1]
Background
Computer programs consist of a series of instructions stored in memory. A processor runs a program by fetching these instructions from memory, examining them, and performing the actions the instruction calls for.
In early machines, the speed of main memory was generally in the same order of time as a basic operation within the processor. For instance, an instruction that adds two numbers might take three or four instruction cycles, while fetching the numbers from memory might take one or two cycles. In these machines, there was no penalty for data being in main memory, and the instruction set architectures were generally designed to allow direct access, for instance, an add instruction might take a value from one location in memory, add it to the value from another, and then store the result in a third location.
The introduction of increasingly fast microprocessors and cheap-but-slower dynamic RAM changed this equation dramatically. In modern machines, fetching a value from main memory might take the equivalent of thousands of cycles. One of the key advances in the RISC concept was to include more processor registers than earlier designs, typically several dozen rather than two or three. Instructions that formerly were provided memory locations were eliminated, replaced by ones that worked only on registers. Loading that data into the register was explicit; a separate load action had to be performed, and the results were explicitly saved back. One could improve performance by eliminating as many of these memory instructions as possible. This technique quickly reached its limits, and since the 1990s modern CPUs have added increasing amounts of CPU cache to increase local storage, although cache is slower than registers.
Since the late 1990s, the performance gains have mostly been made through the use of additional "functional units", which allow some instructions to run in parallel. For instance, two additional instructions working on different data can be run at the same time, effectively doubling the speed of the program. Modern CPUs generally have dozens of such units, some for integer math and boolean logic, some for floating point math, some for long-data words and others for dealing with memory and other housekeeping chores. However, most programs do not work on independent data but instead use the outputs of one calculation as the input to another. This limits the set of instructions that can be run in parallel to some factor based on how many instructions the processor is able to examine on-the-fly. The level of instruction parallelism quickly plateaued by the mid-2000s.
One attempt to break out of this limit is the very long instruction word (VLIW) concept. VLIW hands the task of looking for instruction parallelism to the compiler, removing it from the processor itself. In theory this allows the entire program to be examined for independent instructions, which can then be sent to the processor in the order that will make maximal use of the functional units. However, this has proven difficult in practice, and VLIW processors have not become widely popular.
Even in the case of VLIW, another problem has grown to become an issue. In all traditional designs the data and instructions are handled by different parts of the CPU. When processing speeds were low this did not cause problems, but as performance increased, the communication times from one side of the chip (the registers) to the other (the functional units) grew to become a significant fraction of overall processing time. For further gains in performance, the registers should be distributed closer to their functional units.
EDGE
TRIPS is a processor based on the Explicit Data Graph Execution (EDGE) concept. EDGE attempts to bypass certain performance bottlenecks that have come to dominate modern systems.[2]
EDGE is based on the processor being able to better understand the instruction stream being sent to it, not seeing it as a linear stream of individual instructions, but rather blocks of instructions related to a single task using isolated data. EDGE attempts to run all of these instructions as a block, distributing them internally along with any data they need to process.[3] The compilers examine the code and find blocks of code that share information in a specific way. These are then assembled into compiled "hyper-blocks" and fed into the CPU. Since the compiler is guaranteeing that these blocks have specific inter-dependencies between them, the processor can isolate the code in a single functional unit with its own local memory.
Consider a simple example that adds two numbers from memory, then adds that result to another value in memory. In this case a traditional processor would have to notice the dependency and schedule the instructions to run one after the other, storing the intermediate results in the registers. In an EDGE processor, the inter-dependencies between the data in the code would be noticed by the compiler, which would compile these instructions into a single block. That block would then be fed, along with all the data it needed to complete, into a single functional unit and its own private set of registers. This ensures that no additional memory fetching is required, as well as keeping the registers physically close to the functional unit that needs those values.
Code that did not rely on this intermediate data would be compiled into separate hyper-blocks. Of course its possible that an entire program would use the same data, so the compilers also look for instances where data is handed off to other code and then effectively abandoned by the original block, which is a common access pattern. In this case the compiler will still produce two separate hyper-blocks, but explicitly encode the hand-off of the data rather than simply leaving it stored in some shared memory location. In doing so, the processor can "see" these communications events and schedule them to run in proper order. Blocks that have considerable inter-dependencies are re-arranged by the compiler to spread out the communications in order to avoid bottle-necking the transport.
The effect of this change is to greatly increase the isolation of the individual functional units. EDGE processors are limited in parallelism by the capabilities of the compiler, not the on-chip systems. Whereas modern processors are reaching a plateau at four-wide parallelism, EDGE designs can scale out much wider. They can also scale "deeper" as well, handing off blocks from one unit to another in a chain that is scheduled to reduce the contention due to shared values.
TRIPS
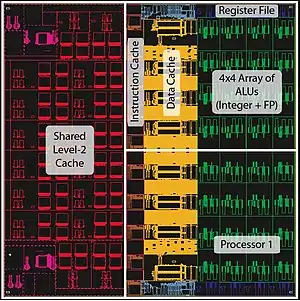
University of Texas at Austin's implementation of the EDGE concept is the TRIPS processor, the Tera-op, Reliable, Intelligently adaptive Processing System. A TRIPS CPU is built by repeating a single basic functional unit as many times as needed. The TRIPS design's use of hyper-blocks that are loaded en-masse allows for dramatic gains in speculative execution. Whereas a traditional design might have a few hundred instructions to examine for possible scheduling into the functional units, the TRIPS design has thousands, hundreds of instructions per hyper-block, and hundreds of hyper-blocks being examined. This leads to greatly improved functional unit utilization; scaling its performance to a typical four-issue superscalar design, TRIPS can process about three times as many instructions per cycle.
In traditional designs there are a variety of different types of units, integer, floating point, etc., allowing more parallelism than the four-wide schedulers would otherwise allow. However, in order to keep all of the units active the instruction stream has to include all of these different types of instruction. As this is often not the case in practice, traditional CPUs often have many idle functional units. In TRIPS, the individual units are general purpose, allowing any instruction to run on any core. Not only does this avoid the need to carefully balance the number of different kinds of cores, but it also means that a TRIPS design can be built with any number of cores needed to reach a particular performance requirement. A single-core TRIPS CPU, with a simplified (or eliminated) scheduler will run a set of hyperblocks exactly like one with hundreds of cores, only slower.
Better yet, the performance is not dependent on the types of data being fed in, meaning that a TRIPS CPU will run a much wider variety of tasks at the same level performance. For instance, if a traditional CPU is fed a math-heavy workload, it will bog as soon as all the floating point units are busy, with the integer units lying idle. If it is fed a data intensive program like a database job, the floating point units will lie idle while the integer units bog. In a TRIPS CPU every functional unit will add to the performance of every task, because every task can run on every unit. The designers refer to as a "polymorphic processor".
TRIPS is so flexible in this regard that the developers have suggested it would even replace some custom high-speed designs like DSPs. Like TRIPS, DSPs gain additional performance by limiting data inter-dependencies, but unlike TRIPS they do so by allowing only a very limited workflow to run on them. TRIPS would be just as fast as a custom DSP on these workloads, but equally able to run other workloads at the same time. As the designers have noted, it is unlikely a TRIPS processor could be used to replace highly customized designs like GPUs in modern graphics cards, but they may be able to replace or outperform many lower-performance chips like those used for media processing.
The reduction of the global register file also results in non-obvious gains. The addition of new circuitry to modern processors has meant that their overall size has remained about the same even as they move to smaller process sizes. As a result, the relative distance to the register file has grown, and this limits the possible cycle speed due to communications delays. In EDGE the data is generally more local or isolated in well defined inter-core links, eliminating large "cross-chip" delays. This means the individual cores can be run at higher speeds, limited by the signaling time of the much shorter data paths.
The combination of these two design changes effects greatly improves system performance. The goal is to produce a single-processor system with 1 TFLOPs performance by 2012. However, as of 2008, GPUs from ATI and NVIDIA have already exceeded the 1 teraflop barrier (albeit for specialized applications). As for traditional CPUs, a contemporary (2007) Mac Pro using a 2-core Intel Xeon can only perform about 5 GFLOPs on single applications.[4]
In 2003, the TRIPS team started implementing a prototype chip. Each chip has two complete cores, each one with 16 functional units in a four-wide, four-deep arrangement. In the current implementation, the compiler constructs "hyperblocks" of 128 instructions each, and allows the system to keep eight blocks "in flight" at the same time, for a total of 1,024 instructions per core. The basic design can include up to 32 chips interconnected, approaching 500 GFLOPS.[5]