Cache prefetching
Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed (hence the term 'prefetch').[1][2] Most modern computer processors have fast and local cache memory in which prefetched data is held until it is required. The source for the prefetch operation is usually main memory although it can also be from disk storage. Because of their design, accessing cache memories is typically much faster than accessing main memory, so prefetching data and then accessing it from caches is usually many orders of magnitude faster than accessing it directly from main memory. Prefetching can be done with non-blocking cache control instructions.
Data vs. instruction cache prefetching
Cache prefetching can either fetch data or instructions into cache.
- Data prefetching fetches data before it is needed. Because data access patterns show less regularity than instruction patterns, accurate data prefetching is generally more challenging than instruction prefetching.
- Instruction prefetching fetches instructions before they need to be executed. The first mainstream microprocessors to use some form of instruction prefetch were the Intel 8086 (six bytes) and the Motorola 68000 (four bytes). In recent years, all high-performance processors use prefetching techniques.
Hardware vs. software cache prefetching
Cache prefetching can be accomplished either by hardware or by software.[3]
- Hardware based prefetching is typically accomplished by having a dedicated hardware mechanism in the processor that watches the stream of instructions or data being requested by the executing program, recognizes the next few elements that the program might need based on this stream and prefetches into the processor's cache.[4]
- Software based prefetching is typically accomplished by having the compiler analyze the code and insert additional "prefetch" instructions in the program during compilation itself.[5]
Methods of hardware prefetching
Stream buffers
- Stream buffers were developed based on the concept of "one block lookahead (OBL) scheme" proposed by Alan Jay Smith.[1]
- Stream buffers are one of the most common hardware based prefetching techniques in use. This technique was originally proposed by Norman Jouppi in 1990[6] and many variations of this method have been developed since.[7][8][9] The basic idea is that the cache miss address (and subsequent addresses) are fetched into a separate buffer of depth . This buffer is called a stream buffer and is separate from cache. The processor then consumes data/instructions from the stream buffer if the address associated with the prefetched blocks match the requested address generated by the program executing on the processor. The figure below illustrates this setup:

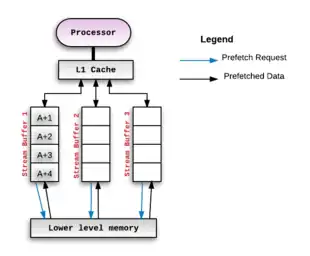
- Whenever the prefetch mechanism detects a miss on a memory block, say A, it allocates a stream to begin prefetching successive blocks from the missed block onward. If the stream buffer can hold 4 blocks, then we would prefetch A+1, A+2, A+3, A+4 and hold those in the allocated stream buffer. If the processor consumes A+1 next, then it shall be moved "up" from the stream buffer to the processor's cache. The first entry of the stream buffer would now be A+2 and so on. This pattern of prefetching successive blocks is called Sequential Prefetching. It is mainly used when contiguous locations are to be prefetched. For example, it is used when prefetching instructions.
- This mechanism can be scaled up by adding multiple such 'stream buffers' - each of which would maintain a separate prefetch stream.[10] For each new miss, there would be a new stream buffer allocated and it would operate in a similar way as described above.
- The ideal depth of the stream buffer is something that is subject to experimentation against various benchmarks[6] and depends on the rest of the microarchitecture involved.[11]
Strided prefetching
This type of prefetching monitors the delta between the addresses of the memory accesses and looks for patterns within it.
Regular strides
In this pattern, consecutive memory accesses are made to blocks that are addresses apart.[3][12] In this case, the prefetcher calculates the and uses it to compute the memory address for prefetching. E.g.: If the is 4, the address to be prefetched would A+4.

Irregular strides
In this case, the delta between the addresses of consecutive memory accesses is variable but still follows a pattern. Some prefetchers designs[9][13][14] exploit this property to predict and prefetch for future accesses.
Temporal prefetching
This class of prefetchers look for memory access streams that repeat over time.[15][16] E.g. In this stream of memory accesses: N, A, B, C, E, G, H, A, B, C, I, J, K, A, B, C, L, M, N, O, A, B, C, ...; the stream A,B,C is repeating over time. Other design variation have tried to provide more efficient, performant implementations.[17][18]
Collaborative prefetching
Computer applications generate a variety of access patterns. The processor and memory subsystem architectures used to execute these applications further disambiguate the memory access patterns they generate. Hence, the effectiveness and efficiency of prefetching schemes often depend on the application and the architectures used to execute them.[19] Recent research[20][21] has focused on building collaborative mechanisms to synergistically use multiple prefetching schemes for better prefetching coverage and accuracy.
Methods of software prefetching
Compiler directed prefetching
Compiler directed prefetching is widely used within loops with a large number of iterations. In this technique, the compiler predicts future cache misses and inserts a prefetch instruction based on the miss penalty and execution time of the instructions.
These prefetches are non-blocking memory operations, i.e. these memory accesses do not interfere with actual memory accesses. They do not change the state of the processor or cause page faults.
One main advantage of software prefetching is that it reduces the number of compulsory cache misses.[3]
The following example shows how a prefetch instruction would be added into code to improve cache performance.
Consider a for loop as shown below:
for (int i=0; i<1024; i++) {
array1[i] = 2 * array1[i];
}
At each iteration, the ith element of the array "array1" is accessed. Therefore, we can prefetch the elements that are going to be accessed in future iterations by inserting a "prefetch" instruction as shown below:
for (int i=0; i<1024; i++) {
prefetch (array1 [i + k]);
array1[i] = 2 * array1[i];
}
Here, the prefetch stride, depends on two factors, the cache miss penalty and the time it takes to execute a single iteration of the for loop. For instance, if one iteration of the loop takes 7 cycles to execute, and the cache miss penalty is 49 cycles then we should have - which means that we prefetch 7 elements ahead. With the first iteration, i will be 0, so we prefetch the 7th element. Now, with this arrangement, the first 7 accesses (i=0->6) will still be misses (under the simplifying assumption that each element of array1 is in a separate cache line of its own).

Comparison of hardware and software prefetching
- While software prefetching requires programmer or compiler intervention, hardware prefetching requires special hardware mechanisms.[3]
- Software prefetching works well only with loops where there is regular array access as the programmer has to hand code the prefetch instructions, whereas hardware prefetchers work dynamically based on the program's behavior at runtime.[3]
- Hardware prefetching also has less CPU overhead when compared to software prefetching.[22]
Metrics of cache prefetching
There are three main metrics to judge cache prefetching[3]
Coverage
Coverage is the fraction of total misses that are eliminated because of prefetching, i.e.
,

where,

Accuracy
Accuracy is the fraction of total prefetches that were useful - i.e. the ratio of the number of memory addresses prefetched were actually referenced by the program to the total prefetches done.

While it appears that having perfect accuracy might imply that there are no misses, this is not the case. The prefetches themselves might result in new misses if the prefetched blocks are placed directly into the cache. Although these may be a small fraction of the total number of misses we might see without any prefetching, this is a non-zero number of misses.
Timeliness
The qualitative definition of timeliness is how early a block is prefetched versus when it is actually referenced. An example to further explain timeliness is as follows:
Consider a for loop where each iteration takes 3 cycles to execute and the 'prefetch' operation takes 12 cycles. This implies that for the prefetched data to be useful, we must start the prefetch iterations prior to its usage to maintain timeliness.

References
- Smith, Alan Jay (1982-09-01). "Cache Memories". ACM Comput. Surv. 14 (3): 473–530. doi:10.1145/356887.356892. ISSN 0360-0300. S2CID 6023466.
- Li, Chunlin; Song, Mingyang; Du, Shaofeng; Wang, Xiaohai; Zhang, Min; Luo, Youlong (2020-09-01). "Adaptive priority-based cache replacement and prediction-based cache prefetching in edge computing environment". Journal of Network and Computer Applications. 165: 102715. doi:10.1016/j.jnca.2020.102715. S2CID 219506427.
- Solihin, Yan (2016). Fundamentals of parallel multicore architecture. Boca Raton, Florida: CRC Press, Taylor & Francis Group. p. 163. ISBN 978-1482211184.
- Baer, Jean-Loup; Chen, Tien-Fu (1991-01-01). An Effective On-chip Preloading Scheme to Reduce Data Access Penalty. 1991 ACM/IEEE Conference on Supercomputing. Albuquerque, New Mexico, USA: Association for Computing Machinery. pp. 176–186. CiteSeerX 10.1.1.642.703. doi:10.1145/125826.125932. ISBN 978-0897914598.
- Kennedy, Porterfield, Allan (1989-01-01). Software methods for improvement of cache performance on supercomputer applications (Thesis). Rice University. hdl:1911/19069.
{{cite thesis}}: CS1 maint: multiple names: authors list (link) - Jouppi, Norman P. (1990). "Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers". Proceedings of the 17th annual international symposium on Computer Architecture – ISCA 1990. 17th annual international symposium on Computer Architecture – ISCA 1990. New York, New York, USA: Association for Computing Machinery Press. pp. 364–373. CiteSeerX 10.1.1.37.6114. doi:10.1145/325164.325162. ISBN 0-89791-366-3.
- Chen, Tien-Fu; Baer, Jean-Loup (1995-05-01). "Effective hardware-based data prefetching for high-performance processors". IEEE Transactions on Computers. 44 (5): 609–623. doi:10.1109/12.381947. ISSN 0018-9340. S2CID 1450745.
- Palacharla, S.; Kessler, R. E. (1994-01-01). Evaluating Stream Buffers As a Secondary Cache Replacement. 21st Annual International Symposium on Computer Architecture. Chicago, Illinois, USA: IEEE Computer Society Press. pp. 24–33. CiteSeerX 10.1.1.92.3031. doi:10.1109/ISCA.1994.288164. ISBN 978-0818655104.
- Grannaes, Marius; Jahre, Magnus; Natvig, Lasse (2011). "Storage Efficient Hardware Prefetching using Delta-Correlating Prediction Tables". Journal of Instruction-Level Parallelism (13): 1–16. CiteSeerX 10.1.1.229.3483.
- Ishii, Yasuo; Inaba, Mary; Hiraki, Kei (2009-06-08). "Access map pattern matching for data cache prefetch". Proceedings of the 23rd International Conference on Supercomputing. ICS 2009. New York, New York, USA: Association for Computing Machinery. pp. 499–500. doi:10.1145/1542275.1542349. ISBN 978-1-60558-498-0. S2CID 37841036.
- Srinath, Santhosh; Mutlu, Onur; Kim, Hyesoon; Patt, Yale N. (February 2007). Feedback Directed Prefetching: Improving the Performance and Bandwidth-Efficiency of Hardware Prefetchers. 2007 IEEE 13th International Symposium on High Performance Computer Architecture. pp. 63–74. doi:10.1109/HPCA.2007.346185. ISBN 978-1-4244-0804-7. S2CID 6909725.
- Kondguli, Sushant; Huang, Michael (November 2017). T2: A Highly Accurate and Energy Efficient Stride Prefetcher. 2017 IEEE International Conference on Computer Design (ICCD). pp. 373–376. doi:10.1109/ICCD.2017.64. ISBN 978-1-5386-2254-4. S2CID 11055312.
- Shevgoor, Manjunath; Koladiya, Sahil; Balasubramonian, Rajeev; Wilkerson, Chris; Pugsley, Seth H.; Chishti, Zeshan (December 2015). Efficiently prefetching complex address patterns. 2015 48th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). pp. 141–152. doi:10.1145/2830772.2830793. ISBN 9781450340342. S2CID 15294463.
- Kim, Jinchun; Pugsley, Seth H.; Gratz, Paul V.; Reddy, A.L. Narasimha; Wilkerson, Chris; Chishti, Zeshan (October 2016). Path confidence based lookahead prefetching. 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). pp. 1–12. doi:10.1109/MICRO.2016.7783763. ISBN 978-1-5090-3508-3. S2CID 1097472.
- Joseph, Doug; Grunwald, Dirk (1997-05-01). "Prefetching using Markov predictors". Proceedings of the 24th Annual International Symposium on Computer Architecture. ISCA 1997. ISCA 1997. New York, New York, USA: Association for Computing Machinery. pp. 252–263. doi:10.1145/264107.264207. ISBN 978-0-89791-901-2. S2CID 434419.
- Collins, J.; Sair, S.; Calder, B.; Tullsen, D.M. (November 2002). Pointer cache assisted prefetching. 35th Annual IEEE/ACM International Symposium on Microarchitecture, 2002. (MICRO-35). Proceedings. pp. 62–73. doi:10.1109/MICRO.2002.1176239. ISBN 0-7695-1859-1. S2CID 5608519.
- Jain, Akanksha; Lin, Calvin (2013-12-07). "Linearizing irregular memory accesses for improved correlated prefetching". Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture. MICRO-46. New York, New York, USA: Association for Computing Machinery. pp. 247–259. doi:10.1145/2540708.2540730. ISBN 978-1-4503-2638-4. S2CID 196831.
- "Making Temporal Prefetchers Practical: The MISB Prefetcher – Research Articles – Arm Research – Arm Community". community.arm.com. 24 June 2019. Retrieved 2022-03-16.
- Kim, Jinchun; Teran, Elvira; Gratz, Paul V.; Jiménez, Daniel A.; Pugsley, Seth H.; Wilkerson, Chris (2017-05-12). "Kill the Program Counter: Reconstructing Program Behavior in the Processor Cache Hierarchy". ACM SIGPLAN Notices. 52 (4): 737–749. doi:10.1145/3093336.3037701. ISSN 0362-1340.
- Kondguli, Sushant; Huang, Michael (2018-06-02). "Division of labor: a more effective approach to prefetching". Proceedings of the 45th Annual International Symposium on Computer Architecture. ISCA '18. Los Angeles, California: IEEE Press. pp. 83–95. doi:10.1109/ISCA.2018.00018. ISBN 978-1-5386-5984-7. S2CID 50777324.
- Pakalapati, Samuel; Panda, Biswabandan (May 2020). Bouquet of Instruction Pointers: Instruction Pointer Classifier-based Spatial Hardware Prefetching. 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). pp. 118–131. doi:10.1109/ISCA45697.2020.00021. ISBN 978-1-7281-4661-4. S2CID 218683672.
- Callahan, David; Kennedy, Ken; Porterfield, Allan (1991-01-01). Software Prefetching. Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. Santa Clara, California, USA: Association for Computing Machinery. pp. 40–52. doi:10.1145/106972.106979. ISBN 978-0897913805.