GPT-1
Generative Pre-trained Transformer 1 (GPT-1) was the first of OpenAI's large language models following Google's invention of the transformer architecture in 2017.[2] In June 2018, OpenAI released a paper entitled "Improving Language Understanding by Generative Pre-Training",[3] in which they introduced that initial model along with the general concept of a generative pre-trained transformer.[4]
| Original author(s) | OpenAI |
|---|---|
| Initial release | June 2018 |
| Repository | |
| Successor | GPT-2 |
| Type | |
| License | MIT[1] |
| Website | openai |
| Part of a series on |
| Machine learning and data mining |
|---|
 |
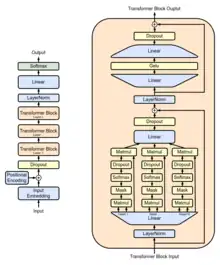
Up to that point, the best-performing neural NLP models primarily employed supervised learning from large amounts of manually labeled data. This reliance on supervised learning limited their use of datasets that were not well-annotated, in addition to making it prohibitively expensive and time-consuming to train extremely large models;[3][5] many languages (such as Swahili or Haitian Creole) are difficult to translate and interpret using such models due to a lack of available text for corpus-building.[5] In contrast, a GPT's "semi-supervised" approach involved two stages: an unsupervised generative "pre-training" stage in which a language modeling objective was used to set initial parameters, and a supervised discriminative "fine-tuning" stage in which these parameters were adapted to a target task.[3]
The use of a transformer architecture, as opposed to previous techniques involving attention-augmented RNNs, provided GPT models with a more structured memory than could be achieved through recurrent mechanisms; this resulted in "robust transfer performance across diverse tasks".[3]
Reason for choosing BookCorpus
BookCorpus was chosen as a training dataset partly because the long passages of continuous text helped the model learn to handle long-range information.[6] It contained over 7,000 unpublished fiction books from various genres. The rest of the datasets available at the time, while being larger, lacked this long-range structure (being "shuffled" at a sentence level).[3]
The BookCorpus text was cleaned by the ftfy library to standardized punctuation and whitespace and then tokenized by spaCy.[3]
Architecture
The GPT-1 architecture was a twelve-layer decoder-only transformer, using twelve masked self-attention heads, with 64-dimensional states each (for a total of 768). Rather than simple stochastic gradient descent, the Adam optimization algorithm was used; the learning rate was increased linearly from zero over the first 2,000 updates to a maximum of 2.5×10−4, and annealed to 0 using a cosine schedule.[3]
While the fine-tuning was adapted to specific tasks, its pre-training was not; to perform the various tasks, minimal changes were performed to its underlying task-agnostic model architecture.[3] Despite this, GPT-1 still improved on previous benchmarks in several language processing tasks, outperforming discriminatively-trained models with task-oriented architectures on several diverse tasks.[3]
Performance and evaluation
GPT-1 achieved a 5.8% and 1.5% improvement over previous best results[3] on natural language inference (also known as textual entailment) tasks, evaluating the ability to interpret pairs of sentences from various datasets and classify the relationship between them as "entailment", "contradiction" or "neutral".[3] Examples of such datasets include QNLI (Wikipedia articles) and MultiNLI (transcribed speech, popular fiction, and government reports, among other sources);[7] It similarly outperformed previous models on two tasks related to question answering and commonsense reasoning—by 5.7% on RACE,[8] a dataset of written question-answer pairs from middle and high school exams, and by 8.9% on the Story Cloze Test.[9]
GPT-1 improved on previous best-performing models by 4.2% on semantic similarity (or paraphrase detection), evaluating the ability to predict whether two sentences are paraphrases of one another, using the Quora Question Pairs (QQP) dataset.[3]
GPT-1 achieved a score of 45.4, versus a previous best of 35.0[3] in a text classification task using the Corpus of Linguistic Acceptability (CoLA). Finally, GPT-1 achieved an overall score of 72.8 (compared to a previous record of 68.9) on GLUE, a multi-task test.[10]
References
- "gpt-2". GitHub. Archived from the original on 11 March 2023. Retrieved 13 March 2023.
- Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia (2017-06-12). "Attention Is All You Need". arXiv:1706.03762 [cs.CL].
- Radford, Alec; Narasimhan, Karthik; Salimans, Tim; Sutskever, Ilya (11 June 2018). "Improving Language Understanding by Generative Pre-Training" (PDF). OpenAI. p. 12. Archived (PDF) from the original on 26 January 2021. Retrieved 23 January 2021.
- "Archived copy". Archived from the original on 2023-04-15. Retrieved 2023-04-29.
{{cite web}}: CS1 maint: archived copy as title (link) - Tsvetkov, Yulia (22 June 2017). "Opportunities and Challenges in Working with Low-Resource Languages" (PDF). Carnegie Mellon University. Archived (PDF) from the original on 31 March 2020. Retrieved 23 January 2021.
- Zhu, Yukun; Kiros, Ryan; Zemel, Richard; Salakhutdinov, Ruslan; Urtasun, Raquel; Torralba, Antonio; Fidler, Sanja (22 June 2015). "Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books". arXiv:1506.06724 [cs.CV].
# of books: 11,038 / # of sentences: 74,004,228 / # of words: 984,846,357 / mean # of words per sentence: 13 / median # of words per sentence: 11
- Williams, Adina; Nangia, Nikita; Bowman, Samuel (1 June 2018). "A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference" (PDF). Association for Computational Linguistics. Archived (PDF) from the original on 11 February 2020. Retrieved 23 January 2021.
At 433k examples, this resource is one of the largest corpora available for natural language inference (a.k.a. recognizing textual entailment), [...] offering data from ten distinct genres of written and spoken English [...] while supplying an explicit setting for evaluating cross-genre domain adaptation.
- Lai, Guokun; Xie, Qizhe; Hanxiao, Liu; Yang, Yiming; Hovy, Eduard (15 April 2017). "RACE: Large-scale ReAding Comprehension Dataset From Examinations". arXiv:1704.04683 [cs.CL].
- Mostafazadeh, Nasrin; Roth, Michael; Louis, Annie; Chambers, Nathanael; Allen, James F. (3 April 2017). "LSDSem 2017 Shared Task: The Story Cloze Test" (PDF). Association for Computational Linguistics. Archived (PDF) from the original on 22 November 2020. Retrieved 23 January 2021.
The LSDSem'17 shared task is the Story Cloze Test, a new evaluation for story understanding and script learning. This test provides a system with a four-sentence story and two possible endings, and the system must choose the correct ending. Successful narrative understanding (getting closer to human performance of 100%) requires systems to link various levels of semantics to commonsense knowledge.
- Wang, Alex; Singh, Amanpreet; Michael, Julian; Hill, Felix; Levy, Omar; Bowman, Samuel R. (20 April 2018). "GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding". arXiv:1804.07461 [cs.CL].
| Products | |
|---|---|
| Foundation models | |
| People | |
| Related | |
| |
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General | |||||||
| Concepts | |||||||
| Applications | |||||||
| Hardware | |||||||
| Software libraries | |||||||
| Implementations |
| ||||||
| People | |||||||
| Organizations | |||||||
| Architectures |
| ||||||
| |||||||