Echo state network
An echo state network (ESN)[1][2] is a type of reservoir computer that uses a recurrent neural network with a sparsely connected hidden layer (with typically 1% connectivity). The connectivity and weights of hidden neurons are fixed and randomly assigned. The weights of output neurons can be learned so that the network can produce or reproduce specific temporal patterns. The main interest of this network is that although its behaviour is non-linear, the only weights that are modified during training are for the synapses that connect the hidden neurons to output neurons. Thus, the error function is quadratic with respect to the parameter vector and can be differentiated easily to a linear system.
Alternatively, one may consider a nonparametric Bayesian formulation of the output layer, under which: (i) a prior distribution is imposed over the output weights; and (ii) the output weights are marginalized out in the context of prediction generation, given the training data. This idea has been demonstrated in[3] by using Gaussian priors, whereby a Gaussian process model with ESN-driven kernel function is obtained. Such a solution was shown to outperform ESNs with trainable (finite) sets of weights in several benchmarks.
Some publicly available implementations of ESNs are: (i) aureservoir: an efficient C++ library for various kinds of echo state networks with python/numpy bindings; (ii) Matlab code: an efficient matlab for an echo state network; (iii) ReservoirComputing.jl: an efficient Julia-based implementation of various types of echo state networks; and (iv) pyESN: simple echo state networks in Python.
Background
The Echo State Network (ESN)[4] belongs to the Recurrent Neural Network (RNN) family and provide their architecture and supervised learning principle. Unlike Feedforward Neural Networks, Recurrent Neural Networks are dynamic systems and not functions. Recurrent Neural Networks are typically used for: Learn dynamical process: signal treatment in engineering and telecommunications, vibration analysis, seismology, control of engines and generators. Signal forecasting and generation: text, music, electric signals, chaotic signals.[5] Modeling of biological systems, neurosciences (cognitive neurodynamics), memory modeling, brain-computer Interfaces (BCIs), filtering and Kalman processes, military applications, volatility modeling etc.
For the training of RNN a number of learning algorithms are available: backpropagation through time, real-time recurrent learning. Convergence is not guaranteed due to instability and bifurcation phenomena.[4]
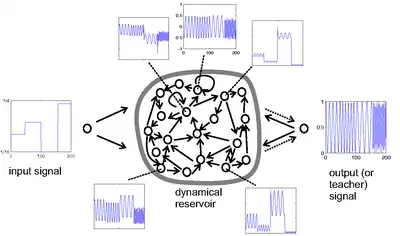
The main approach of the ESN is firstly to operate a random, large, fixed, recurring neural network with the input signal, which induces a nonlinear response signal in each neuron within this "reservoir" network, and secondly connect a desired output signal by a trainable linear combination of all these response signals.[2]
Another feature of the ESN is the autonomous operation in prediction: if the Echo State Network is trained with an input that is a backshifted version of the output, then it can be used for signal generation/prediction by using the previous output as input.[4][5]
The main idea of ESNs is tied to Liquid State Machines (LSM), which were independently and simultaneously developed with ESNs by Wolfgang Maass.[6] LSMs, ESNs and the newly researched Backpropagation Decorrelation learning rule for RNNs[7] are more and more summarized under the name Reservoir Computing.
Schiller and Steil[7] also demonstrated that in conventional training approaches for RNNs, in which all weights (not only output weights) are adapted, the dominant changes are in output weights. In cognitive neuroscience, Peter F. Dominey analysed a related process related to the modelling of sequence processing in the mammalian brain, in particular speech recognition in the human brain.[8] The basic idea also included a model of temporal input discrimination in biological neuronal networks.[9] An early clear formulation of the reservoir computing idea is due to K. Kirby, who disclosed this concept in a largely forgotten conference contribution.[10] The first formulation of the reservoir computing idea known today stems from L. Schomaker,[11] who described how a desired target output can be obtained from an RNN by learning to combine signals from a randomly configured ensemble of spiking neural oscillators.[2]
Variants
Echo state networks can be built in different ways. They can be set up with or without directly trainable input-to-output connections, with or without output reservation feedback, with different neurotypes, different reservoir internal connectivity patterns etc. The output weight can be calculated for linear regression with all algorithms whether they are online or offline. In addition to the solutions for errors with smallest squares, margin maximization criteria, so-called training support vector machines, are used to determine the output values.[12] Other variants of echo state networks seek to change the formulation to better match common models of physical systems, such as those typically those defined by differential equations. Work in this direction includes echo state networks which partially include physical models,[13] hybrid echo state networks,[14] and continuous-time echo state networks.[15]
The fixed RNN acts as a random, nonlinear medium whose dynamic response, the "echo", is used as a signal base. The linear combination of this base can be trained to reconstruct the desired output by minimizing some error criteria.[2]
Significance
RNNs were rarely used in practice before the introduction of the ESN, because of the complexity involved in adjusting their connections (e.g., lack of autodifferentiation, susceptibility to vanishing/exploding gradients, etc.). RNN training algorithms were slow and often vulnerable to issues, such as branching errors.[16] Convergence could therefore not be guaranteed. On the other hand, ESN training does not have the problem with branching and is easy to implement. In early studies, ESNs were shown to perform well on time series prediction tasks from synthetic datasets.[1][17]
However, today many of the problems that made RNNs slow and error-prone have been addressed with the advent of autodifferentiation (deep learning) libraries, as well as more stable architectures such as LSTM and GRU—thus, the unique selling point of ESNs has been lost. In addition, RNNs have proven themselves in several practical areas such as language processing. To cope with tasks of similar complexity using reservoir calculation methods, it would require memory of excessive size.
However, ESNs are used in some areas such as many signal processing applications. In particular, they have been widely used as a computing principle that mixes well with non-digital computer substrates. Since ESNs do not need to modify the parameters of the RNN, they make it possible to use many different objects as their nonlinear "reservoir″. For example: optical microchips, mechanical nanooscillators, polymer mixtures, or even artificial soft limbs.[2]
See also
- Liquid-state machine: a similar concept with generalized signal and network.
- Reservoir computing
References
- Jaeger, H.; Haas, H. (2004). "Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication" (PDF). Science. 304 (5667): 78–80. Bibcode:2004Sci...304...78J. doi:10.1126/science.1091277. PMID 15064413. S2CID 2184251.
- Jaeger, Herbert (2007). "Echo state network". Scholarpedia. 2 (9): 2330. Bibcode:2007SchpJ...2.2330J. doi:10.4249/scholarpedia.2330.
- Chatzis, S. P.; Demiris, Y. (2011). "Echo State Gaussian Process". IEEE Transactions on Neural Networks. 22 (9): 1435–1445. doi:10.1109/TNN.2011.2162109. PMID 21803684. S2CID 8553623.
- Jaeger, Herbert (2002). A tutorial on training recurrent neural networks, covering BPPT, RTRL, EKF and the "echo state network" approach. Germany: German National Research Center for Information Technology. pp. 1–45.
- Antonik, Piotr; Gulina, Marvyn; Pauwels, Jaël; Massar, Serge (2018). "Using a reservoir computer to learn chaotic attractors, with applications to chaos synchronization and cryptography". Phys. Rev. E. 98 (1): 012215. arXiv:1802.02844. Bibcode:2018PhRvE..98a2215A. doi:10.1103/PhysRevE.98.012215. PMID 30110744. S2CID 3616565.
- Maass W., Natschlaeger T., and Markram H. (2002). "Real-time computing without stable states: A new framework for neural computation based on perturbations". Neural Computation. 14 (11): 2531–2560. doi:10.1162/089976602760407955. PMID 12433288. S2CID 1045112.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Schiller U.D. and Steil J. J. (2005). "Analyzing the weight dynamics of recurrent learning algorithms". Neurocomputing. 63: 5–23. doi:10.1016/j.neucom.2004.04.006.
- Dominey P.F. (1995). "Complex sensory-motor sequence learning based on recurrent state representation and reinforcement learning". Biol. Cybernetics. 73 (3): 265–274. doi:10.1007/BF00201428. PMID 7548314. S2CID 1603500.
- Buonomano, D.V. and Merzenich, M.M. (1995). "Temporal Information Transformed into a Spatial Code by a Neural Network with Realistic Properties". Science. 267 (5200): 1028–1030. Bibcode:1995Sci...267.1028B. doi:10.1126/science.7863330. PMID 7863330. S2CID 12880807.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Kirby, K. (1991). "Context dynamics in neural sequential learning. Proc". Florida AI Research Symposium: 66–70.
- Schomaker, L. (1992). "A neural oscillator-network model of temporal pattern generation". Human Movement Science. 11 (1–2): 181–192. doi:10.1016/0167-9457(92)90059-K.
- Schmidhuber J., Gomez F., Wierstra D., and Gagliolo M. (2007). "Training recurrent networks by evolino". Neural Computation. 19 (3): 757–779. doi:10.1162/neco.2007.19.3.757. PMID 17298232. S2CID 11745761.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Doan N, Polifke W, Magri L (2020). "Physics-Informed Echo State Networks". Journal of Computational Science. 47: 101237. arXiv:2011.02280. doi:10.1016/j.jocs.2020.101237. S2CID 226246385.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Pathak J, Wikner A, Russel R, Chandra S, Hunt B, Girvan M, Ott E (2018). "Hybrid Forecasting of Chaotic Processes: Using Machine Learning in Conjunction with a Knowledge-Based Model". Chaos. 28 (4): 041101. arXiv:1803.04779. Bibcode:2018Chaos..28d1101P. doi:10.1063/1.5028373. PMID 31906641. S2CID 3883587.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Anantharaman, Ranjan; Ma, Yingbo; Gowda, Shashi; Laughman, Chris; Shah, Viral; Edelman, Alan; Rackauckas, Chris (2020). "Accelerating Simulation of Stiff Nonlinear Systems using Continuous-Time Echo State Networks". arXiv:2010.04004 [cs.LG].
- Doya K. (1992). "Bifurcations in the learning of recurrent neural networks". [Proceedings] 1992 IEEE International Symposium on Circuits and Systems. Vol. 6. pp. 2777–2780. doi:10.1109/ISCAS.1992.230622. ISBN 0-7803-0593-0. S2CID 15069221.
- Jaeger H. (2007). "Discovering multiscale dynamical features with hierarchical echo state networks". Technical Report 10, School of Engineering and Science, Jacobs University.
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General | |||||||
| Concepts | |||||||
| Applications | |||||||
| Hardware | |||||||
| Software libraries | |||||||
| Implementations |
| ||||||
| People | |||||||
| Organizations | |||||||
| Architectures |
| ||||||
| |||||||