Bibliometrics
Bibliometrics is the use of statistical methods to analyse books, articles and other publications, especially in scientific contents. Bibliometric methods are frequently used in the field of library and information science. Bibliometrics is closely associated with scientometrics, the analysis of scientific metrics and indicators, to the point that both fields largely overlap.

| Information science |
|---|
| General aspects |
| Related fields and subfields |
| Part of a series on |
| Research |
|---|
 |
| Philosophy portal |
Bibliometrics studies first appeared in the late 19th century. They have known a significant development after the Second World War in a context of "periodical crisis" and new technical opportunities offered by computing tools. In the early 1960s, the Science Citation Index of Eugene Garfield and the citation network analysis of Derek John de Solla Price laid the fundamental basis of a structured research program on bibliometrics.
Citation analysis is a commonly used bibliometric method which is based on constructing the citation graph,[1] a network or graph representation of the citations shared by documents. Many research fields use bibliometric methods to explore the impact of their field, the impact of a set of researchers, the impact of a particular paper, or to identify particularly impactful papers within a specific field of research. Bibliometrics tools have been commonly integrated in descriptive linguistics, the development of thesauri, and evaluation of reader usage. Beyond specialized scientific use, popular web search engines, such as the pagerank algorithm implemented by Google have been largely shaped by bibliometrics methods and concepts.
The emergence of the Web and the open science movement has gradually transformed the definition and the purpose of "bibliometrics." In the 2010s historical proprietary infrastructures for citation data such as the Web of Science or Scopus have been challenged by new initiatives in favor of open citation data. The Leiden Manifesto for Research Metrics (2015) opened a wide debate on the use and transparency of metrics.
Definition
The term bibliométrie was first used by Paul Otlet in 1934,[2] and defined as "the measurement of all aspects related to the publication and reading of books and documents."[3] The anglicized version bibliometrics was first used by Alan Pritchard in a paper published in 1969, titled "Statistical Bibliography or Bibliometrics?"[4] He defined the term as "the application of mathematics and statistical methods to books and other media of communication." Bibliometrics was conceived as a replacement for statistical bibliography, the main label used by publications in the field until then: for Pritchard, statistical bibliography was too "clumsy" and did not make it very clear what was the main object of study.[5]
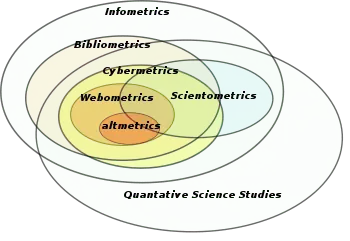
The concept of bibliometrics "stresses the material aspect of the undertaking: counting books, articles, publications, citations"[6] In theory, bibliometrics is a distinct field from scientometrics (from the Russian naukometriya)[7] which relies on the analysis of non-bibliographic indicators of scientific activity. In practice, bibliometrics and scientometrics studies tend to use similar data sources and methods, as citation data has become the leading standard of quantitative scientific evaluation during the mid-20th century: "insofar as bibliometric techniques are applied to scientific and technical literature, the two areas of scientometrics and bibliometrics overlap to a considerable degree."[6] The development of the web and the expansion of bibliometrics approach to non-scientific production has entailed the introduction of broader labels in the 1990s and the 2000s: infometrics, webometrics or cybermetrics.[8] These terms have not been extensively adopted, as they partly overlap with pre-existing research practices, such as information retrieval.
History
Scientific works, studies and researches that have a bibliometric character can be identified, depending on the definition, already for the 12th century in the form of Jewish indexes.[9]
Early experiments (1880–1914)
Bibliometric analysis appeared at the turn of the 19th and the 20th century.[10][11][12][13] These developments predate the first occurrence of the concept of bibiometrics by several decades. Alternative label were commonly used: bibliography statistics became especially prevalent after 1920 and continued to remain in use until the end of the 1960s.[13] Early statistical studies of scientific metadata were motivated by the significant expansion of scientific output and the parallel development of indexing services of databases that made this information more accessible in the first place.[14] Citation index were first applied to case law in the 1860s and their most famous example, Shepard's Citations (first published in 1873) will serve as a direct inspiration for the Science Citation Index one century later.[15]
The emergence of social sciences inspired new speculative research on the science of science and the possibility of studying science itself as a scientific object: "The belief that social activities, including science, could be reduced to quantitative laws, just as the trajectory of a cannonball and the revolutions of the heavenly bodies, traces back to the positivist sociology of Auguste Comte, William Ogburn, and Herbert Spencer."[16] Bibliometric analysis was not conceived as a separate body studies but one of the available methods for the quantitative analysis of scientific activity in different fields of research: science history (Histoire des sciences et des savants depuis deux siècles of Alphonse de Candolle in 1885, The history of comparative anatomy, a statistical analysis of the literature by Francis Joseph Cole and Nellie B. Eales in 1917), bibliography (The Theory of National and International Bibliography of Francis Burburry Campbell in 1896) or sociology of science (Statistics of American Psychologists of James McKeen Cattell in 1903).
Early bibliometrics and scientometrics work were not simply descriptive but expressed normative views of what science should be and how it could progress. The measurement of the performance of individual researchers, scientific institutions or entire countries was a major objective.[14] The statistical analysis of James McKeen Cattell acted as a preparatory work for a large scale evaluation of American researchers with eugenicists undertones: American Men of Science (1906), "with its astoundingly simplistic rating system of asterisks attached to individual entries in proportion to the estimated eminence of the starred scholar."[10]
Development of bibliography statistics (1910–1945)
After 1910, bibliometrics approach increasingly became the main focus in several study of scientific performance rather than one quantitative method among others.[17] In 1917, Francis Joseph Cole and Nellie B. Eales argued in favor of the primary statistical value of publications as a publication "is an isolated and definite piece of work, it is permanent, accessible, and may be judged, and in most cases it is not difficult to ascertain when, where, and by whom it was done, and to plot the results on squared paper."[18] Five years later, Edward Wyndham Hulme expanded this argument to the point that publications could be considered as the standard measure of an entire civilization: "If civilization is but the product of the human mind operating upon a shifting platform of its environment, we may claim for bibliography that it is not only a pillar in the structure of the edifice, but that it can function as a measure of the varying forces to which this structure is continuously subjected."[19] This shift toward publication had a limited impact: well until the 1970s, national and international evaluation of scientific activities "disdained bibliometric indicators" which were deemed too simplistic, in favor of socological and economic measures.[20]
Both the enhanced value attached to scientific publications as a measure of knowledge and the difficulties met by libraries to manage the growing flow of academic periodicals entailed the development of the first citation indexes.[21] In 1927, P. Gross and E. M. Gross compiled the 3,633 references quoted by the Journal of the American Chemical Society during the year 1926 and ranked journals depending on their level of citation. The two authors created a set of tools and methods still commonly used by academic search engines, including attributing a bonus to recent citations since "the present trend rather than the past performance of a journal should be considered first."[22] Yet the academic environment measured was markedly different: German rather than English ranked by far the main language of science of chemistry with more than 50% of all references.[23]
In the same period, fundamental algorithms, metrics and methods of bibliometrics were first identified in several unrelated projects,[24] most of them being related to the structural inequalities of scientific production. In Alfred Lotka introduced its law of productivity from an analysis of the authored publications in the Chemical Abstracts and the Geschichtstafeln der Physik: the number of authors producing an n number of contributions is equal to the 1/n^2 number of authors that only produced one publication.[25] In, the chief librarian of the London Science Museum, Samuel Bradford derived a law of scattering from his experience in bibliographic indexing: there are exponentially diminishing returns of searching for references in science journals, as more and more work need to be consulted to find relevant work. Both the Lotka and Bradford law have been criticized as they are far from universal and rather uncovers a rough power law relationship rendered by deceivingly precise equations.[26]
Periodical crisis, digitization and citation index (1945–1960)
After the Second World War, the growing challenge in managing and accessing scientific publications turned into a full-fledged "periodical crisis": existing journals could not keep up with the rapidly increasing scientific output spurred by the big science projects.[27][7] The issue became politically relevant after the successful launch of Sputnik in 1957: "The Sputnik crisis turned the librarians' problem of bibliographic control into a national information crisis.."[28] In a context of rapid and dramatic change, the emerging field of bibliometrics was linked to large scale reforms of academic publishing and nearly utopian visions of the future of science. In 1934, Paul Otlet introduced under the concept of bibliométrie or bibliology an ambitious project of measuring the impact of texts on society. In contrast with the bounded definition of bibliometrics that will become prevalent after the 1960s, the vision of Otlet was not limited to scientific publication nor in fact to publication as a fundamental unit: it aimed for "by the resolution of texts into atomic elements, or ideas, which he located in the single paragraphs (alinéa, verset, articulet) composing a book."[29] In 1939 John Desmond Bernal envisioned a network of scientific archives, which was briefly considered by the Royal Society in 1948: "The scientific paper sent to the central publication office, upon approval by an editorial board of referees, would be microfilmed, and a sort of print-on-demand system set in action thereafter."[30] While not using the concept of bibliometrics, Bernal had a formative influence of leading figures of the field such as Derek John de Solla Price.
The emerging computing technologies were immediately considered as a potential solution to make a larger amount of scientific output readable and searchable. During the 1950s and 1960s, an uncoordinated wave of experiments in indexing technologies resulted in the rapid development of key concepts of computing research retrieval.[31] In 1957, IBM engineer Hans Peter Luhn introduced an influential paradigm of statistical-based analysis of word frequencies, as "communication of ideas by means of words is carried out on the basis of statistical probability."[32] Automated translation of non-English scientific work has also significantly contributed to fundamental research on natural language processing of bibliographic references, as in this period a significant amount of scientific publications were not still available in English, especially the one coming from the Soviet block. Influent members of the National Science Foundation like Joshua Ledeberg advocated for the creation of a "centralized information system", SCITEL, partly influenced by the ideas of John Desmond Bernal. This system would at first coexist with printed journals and gradually replace them altogether on account of its efficiency.[33] In the plan laid out by Ledeberg to Eugen Garfield in November 1961, a centralized deposit would index as much as 1,000,000 scientific articles per year. Beyond full-text searching, the infrastructure would also ensure the indexation of citation and other metadata, as well as the automated translation of foreign language articles.[34]
The first working prototype on an online retrieval system developed in 1963 by Doug Engelbart and Charles Bourne at the Stanford Research Institute proved the feasibility of these theoretical assumptions, although it was heavily constrained by memory issues: no more than 10,000 words of a few documents could be indexed.[35] The early scientific computing infrastructures were focused on more specific research areas, such as MEDLINE for medicine, NASA/RECON for space engineering or OCLC Worldcat for library search: "most of the earliest online retrieval system provided access to a bibliographic database and the rest used a file containing another sort of information—encyclopedia articles, inventory data, or chemical compounds."[36] Exclusive focus on text analysis proved limitative as the digitized collections expanded: a query could yield a large number results and it was difficult to evaluate the relevancy and the accuracy of the results.[37]
The periodical crisis and the limitations of index retrieval technologies motivated the development of bibliometric tools and large citation index like the Science Citation Index of Eugene Garfield. Garfield's work was initially primarily concerned with the automated analysis of text work. In contrast with ongoing work largely focused on internal semantic relationship, Garfield highlighted "the importance of metatext in discourse analysis", such as introductory sentences and bibliographic references.[38] Secondary forms of scientific production like literature reviews and bibliographic notes became central to Garfield's vision as they have already been to John Desmond Bernal's vision of scientific archives.[39] By 1953, Garfield's attention was permanently shifted to citation analysis: in a private letter to William C. Adair, the vice-president of the publisher of the Shepard's Citation index, "he suggested a well tried solution to the problem of automatic indexing, namely to "shepardize" biomedical literature, to untangle the skein of its content by following the thread of citation links in the same way the legal citator did with court sentences."[40] In 1955, Garfield published his seminal article "Citation Indexes for Science", that both laid out the outline of the Science Citation Index and had a large influence on the future development of bibliometrics.[40] The general citation index envisioned by Garfield was originally one of the building block of the ambitious plan of Joshua Lederberg to computerize scientific literature.[41] Due to lack of funding, the plan was never realized.[42] In 1963, Eugene Garfield created the Institute for Scientific Information that aimed to transform the projects initially envisioned with Lederberg into a profitable business.
Bibliometric reductionism, metrics, and structuration of a research field (1960–1990)
The field of bibliometrics coalesced in parallel to the development of the Science Citation Index, that was to become its fundamental infrastructure and data resource:[43] "while the early twentieth century contributed methods that were necessary for measuring research, the mid-twentieth century was characterized by the development of institutions that motivated and facilitated research measurement."[44] Significant influences of the nascent field included along with John Desmond Bernal, Paul Otlet the sociology of science of Robert K. Merton, that was re-interpreted in a non-ethic manner: the Matthew Effect, that is the increasing concentration of attention given to researchers that were already notable, was no longer considered as a derive(?) but a feature of normal science.[45]
A follower of Bernal, the British historian of science Derek John de Solla Price has had a major impact on the disciplinary formation of bibliometrics: with "the publication of Science Since Babylon (1961), Little Science, Big Science (1963), and Networks of Scientific Papers (1965) by Derek Price, scientometrics already had a sound empirical and conceptual toolkit available."[43] Price was a proponent of bibliometric reductionism.[46] As Francis Joseph Cole and Nellie B. Eales in 1917, he argued that a publication is the best possible standard to lay out a quantitative study of science: they "resemble a pile of bricks (…) to remain in perpetuity as an intellectual edifice built by skill and artifice, resting on primitive foundation."[47] Price doubled down on this reductionist approach by limiting in turn the large set of existing bibliographic data to citation data.
Price's framework, like Garfield's, takes for granted the structural inequality of science production, as a minority of researchers creates a large share of publication and an even smaller share have a real measurable impact on subsequent research (with as few as 2% of papers having 4 citations or more at the time).[48] Despite the unprecedented growth of post-war science, Price claimed for the continued existence of an invisible college of elite scientists that, as in the time of Robert Boyle undertook the most valuable work.[49] While Price was aware of the power relationships that ensured the domination of such an elite, there was a fundamental ambiguity in the bibliometrics studies, that highlighted the concentration of academic publishing and prestige but also created tools, models and metrics that normalized pre-existing inequalities.[49] The central position of the Scientific Citation Index amplified this performative effect. In the end of the 1960s Eugene Garfield formulated a law of concentration that was formally a reinterpretation of the Samuel Bradford's law of scattering, with a major difference: while Bradford talked for the perspective of a specific research project, Garfield drew a generalization of the law to the entire set of scientific publishing: "the core literature for all scientific disciplines involves a group of no more than 1000 journals, and may involve as few as 500." Such law was also a justification of the practical limitation of the citation index to a limited subset of core journals, with the underlying assumption that any expansion into second-tier journals would yield diminishing returns.[50] Rather than simply observing structural trends and patterns, bibliometrics tend to amplify and stratify them even further: "Garfield's citation indexes would have brought to a logical completion, the story of a stratified scientific literature produced by (…) a few, high-quality, "must-buy" international journals owned by a decreasing number of multinational corporations ruling the roost in the global information market."[51]
Under the impulsion of Garfield and Price, bibliometrics became both a research field and a testing ground for quantitative policy evaluation of research. This second aspect was not a major focus of the Science Citation Index has been a progressive development: the famous Impact Factor was originally devised in the 1960s by Garfield and Irving Sher to select the core group of journals that were to be featured in Current Contents and the Science Citation Index and was only regularly published after 1975.[52] The metric itself is a very simple ratio between the total count of citation received by the journal on the past year and its productivity on the past two years, to ponderate the prolificity of some publications.[53] For example, Nature had an impact factor of 41.577 in 2017:[54]

The simplicity of the impact factor has likely been a major factor in its wide adoption by scientific institutions, journals, funders or evaluators: "none of the revised versions or substitutes of ISI IF has gained general acceptance beyond its proponents, probably because the alleged alternatives lack the degree of interpretability of the original measure."[55]
Alongside these simplified measurements, Garfield continued to support and fund fundamental research in science history and sociology of science. First published 1964, The Use of Citation Data in Writing the History of Science compiles several experimental case studies relying on the citation network of the Science Citation Index, including a quantitative reconstruction of the discovery of the DNA.[56] Interest in this area persisted well after the sell of the Index to Thomson Reuters: as late as 2001, Garfield unveiled HistCite, a software for "algorithmic historiography" created in collaboration with Alexander Pudovkin, and Vladimir S. Istomin.[57]
The Web turn (1990–…)
The development of the World Wide Web and the Digital Revolution had a complex impact on bibliometrics.
The web itself and some of its key components (such as search engines) were partly a product of bibliometrics theory. In its original form, it was derived from a bibliographic scientific infrastructure commissioned to Tim Berners-Lee by the CERN for the specific needs of high energy physics, ENQUIRE. The structure of ENQUIRE was closer to an internal web of data: it connected "nodes" that "could refer to a person, a software module, etc. and that could be interlined with various relations such as made, include, describes and so forth."[58] Sharing of data and data documentation was a major focus in the initial communication of the World Wide Web when the project was first unveiled in August 1991 : "The WWW project was started to allow high energy physicists to share data, news, and documentation. We are very interested in spreading the web to other areas, and having gateway servers for other data."[59] The web rapidly superseded pre-existing online infrastructure, even when they included more advanced computing features.[60] The core value attached to hyperlinking in the design of the web seem to validate the intuitions of the funding figures of bibliometrics: "The onset of the World Wide Web in the mid-1990s made Garfield's citationist dream more likely to come true. In the world network of hypertexts, not only is the bibliographic reference one of the possible forms taken by a hyperlink inside the electronic version of a scientific article, but the Web itself also exhibits a citation structure, links between web pages being formally similar to bibliographic citations."[61] Consequently, bibliometrics concepts have been incorporated in major communication technologies the search algorithm of Google: "the citation-driven concept of relevance applied to the network of hyperlinks between web pages would revolutionize the way Web search engines let users quickly pick useful materials out of the anarchical universe of digital information."[62]
While the web expanded the intellectual influence of bibliometrics way beyond specialized scientific research, it also shattered the core tenets of the field. In contrast with the wide utopian visions of Bernal and Otlet that partly inspired it, the Science Citation Index was always conceived as a closed infrastructure, not only from the perspective of their users but also from the perspective of the collection index: the logical conclusion of Price's theory of invisible college and Garfield's law of concentration was to focus exclusively on a limited set of core scientific journals. With the rapid expansion of the Web, numerous forms of publications (notably preprints), scientific activities and communities suddenly became visible and highlighted by contrast the limitations of applied bibliometrics.[63] The other fundamental aspect of bibliometric reductionism, the exclusive focus on citation, has also been increasingly fragilized by the multiplication of alternative data sources and the unprecedented access to full text corpus that made it possible to revive the large scale semantic analysis first envisioned by Garfield in the early 1950s: "Links alone, then, just like bibliographic citations alone, do not seem sufficient to pin down critical communication patterns on the Web, and their statistical analysis will probably follow, in the years to come, the same path of citation analysis, establishing fruitful alliances with other emerging qualitative and quantitative outlooks over the web landscape."[64]
The close relationship between bibliometrics and commercial vendors of citation data and indicators has become more strained since the 1990s. Leading scientific publishers have diversified their activities beyond publishing and moved "from a content-provision to a data analytics business."[65] By 2019, Elsevier has either acquired or built a large portofolio platforms, tools, databases and indicators covering all aspects and stages of scientific research: "the largest supplier of academic journals is also in charge of evaluating and validating research quality and impact (e.g., Pure, Plum Analytics, Sci Val), identifying academic experts for potential employers (e.g., Expert Lookup5), managing the research networking platforms through which to collaborate (e.g., SSRN, Hivebench, Mendeley), managing the tools through which to find funding (e.g., Plum X, Mendeley, Sci Val), and controlling the platforms through which to analyze and store researchers' data (e.g., Hivebench, Mendeley)."[66] Metrics and indicators are key components of this vertical integration: "Elsevier's further move to offering metrics-based decision making is simultaneously a move to gain further influence in the entirety of the knowledge production process, as well as to further monetize its disproportionate ownership of content."[67] The new market for scientific publication and scientific data has been compared with the business models of social networks, search engines and other forms of platform capitalism[68][69][70] While content access is free, it is indirectly paid through data extraction and surveillance.[71] In 2020, Rafael Ball envisioned a bleak future for bibliometricians where their research contribute to the emerge of a highly invasive form of "surveillance capitalism":scientists "be given a whole series of scores which not only provide a more comprehensive picture of the academic performance, but also the perception, behaviour, demeanour, appearance and (subjective) credibility (…) In China, this kind of personal data analysis is already being implemented and used simultaneously as an incentive and penalty system."[72]
The Leiden manifesto for research metrics (2015) highlighted the growing rift between the commercial providers of scientific metrics and bibliometric communities. The signatories stressed the potential social damage of uncontrolled metric-based evaluation and surveillance: "as scientometricians, social scientists and research administrators, we have watched with increasing alarm the pervasive misapplication of indicators to the evaluation of scientific performance."[73] Several structural reforms of bibliometric research and research evaluation are proposed, including a stronger reliance on qualitative assessment and the reliance on "open, transparent and simple" data collection.[73] The Leiden Manifesto has stirred an important debate in bibliometrics/scientometrics/infometrics with some critics arguing that the elaboration of quantitative metrics bears no responsibility on their misuse in commercial platforms and research evaluation.[74]
Usage
Historically, bibliometric methods have been used to trace relationships amongst academic journal citations. Citation analysis, which involves examining an item's referring documents, is used in searching for materials and analyzing their merit.[75] Citation indices, such as Institute for Scientific Information's Web of Science, allow users to search forward in time from a known article to more recent publications which cite the known item.
Data from citation indexes can be analyzed to determine the popularity and impact of specific articles, authors, and publications.[76][77] Using citation analysis to gauge the importance of one's work, for example, has been common in hiring practices of the late 20th century.[78][79] Information scientists also use citation analysis to quantitatively assess the core journal titles and watershed publications in particular disciplines; interrelationships between authors from different institutions and schools of thought; and related data about the sociology of academia. Some more pragmatic applications of this information includes the planning of retrospective bibliographies, "giving some indication both of the age of material used in a discipline, and of the extent to which more recent publications supersede the older ones"; indicating through high frequency of citation which documents should be archived; comparing the coverage of secondary services which can help publishers gauge their achievements and competition, and can aid librarians in evaluating "the effectiveness of their stock."[80] There are also some limitations to the value of citation data. They are often incomplete or biased; data has been largely collected by hand (which is expensive), though citation indexes can also be used; incorrect citing of sources occurs continually; thus, further investigation is required to truly understand the rationale behind citing to allow it to be confidently applied.[81]
Bibliometrics are now used in quantitative research assessment exercises of academic output which is starting to threaten practice based research.[82] The UK government has considered using bibliometrics as a possible auxiliary tool in its Research Excellence Framework, a process which will assess the quality of the research output of UK universities and on the basis of the assessment results, allocate research funding.[83] This has met with significant skepticism and, after a pilot study, looks unlikely to replace the current peer review process.[84] Furthermore, excessive usage of bibliometrics in assessment of value of academic research encourages gaming the system in various ways including publishing large quantity of works with low new content (see least publishable unit), publishing premature research to satisfy the numbers, focusing on popularity of the topic rather than scientific value and author's interest, often with detrimental role to research.[85] Some of these phenomena are addressed in a number of recent initiatives, including the San Francisco Declaration on Research Assessment.
Guidelines have been written on the using of bibliometrics in academic research, in disciplines such as Management,[86] Education,[87] and Information Science.[88] Other bibliometrics applications include: creating thesauri; measuring term frequencies; as metrics in scientometric analysis, exploring grammatical and syntactical structures of texts; measuring usage by readers; quantifying value of online media of communication; in the context of technological trend analyses;[89] measuring Jaccard distance cluster analysis and text mining based on binary logistic regression.[90][91]
In the context of the big deal cancellations by several library systems in the world,[92] data analysis tools like Unpaywall Journals are used by libraries to assist with big deal cancellations: libraries can avoid subscriptions for materials already served by instant open access via open archives like PubMed Central.[93]
Bibliometrics and open science

The open science movement has been acknowledged as the most important transformation faced by bibliometrics since the emergence of the field in the 1960s.[94][95] The free sharing of a wide variety of scientific outputs on the web affected the practice of bibliometrics at all levels: the definition and the collection of the data, infrastructure, and metrics.
Before the crystallization of the field around the Science Citation Index and the reductionist theories of Derek de Solla Price, bibliometrics has been largely influenced by utopian projects of enhanced knowledge sharing beyond specialized academic communities. The scientific networks envisioned by Paul Otlet or John Desmond Bernal have gained a new relevancy with the development of the Web: "The philosophical inspiration of the pioneers in pursuing the above lines of inquiry, however, faded gradually into the background (…) Whereas Bernal's input would eventually find an ideal continuation in the open access movement, the citation machine set into motion by Garfield and Small led to the proliferation of sectorial studies of a fundamentally empirical nature."[96]
From altmetrics to open metrics
In the early developments, the open science movement partly co-opted the standard tools of bibliometrics and quantitative evaluation: "the fact that no reference was made to metadata in the main OA declarations (Budapest, Berlin, Bethesda) has led to a paradoxical situation (…) it was through the use of the Web of Science that OA advocates were eager to show how much accessibility led to a citation advantage compared to paywalled articles."[97] After 2000, an important bibliometric literature was devoted to the citation advantage of open access publications.[98]
By the end of the 2000s, the impact factor and other metrics have increasingly held responsible a systemic locked-in of prestigious non-accessible sources. Key figures of the open science movement like Stevan Harnad called for the creation of "open access scientometrics" that would take "advantage of the wealth of usage and impact metrics enabled by the multiplication of online, full-text, open access digital archives."[99] As the public of open science expanded beyond academic circles, new metrics should aim for "measuring the broader societal impacts of scientific research."[100]
The concept of alt-metrics was introduced in 2009 by Cameron Neylon and Shirly Wu as article-level metrics.[101] In contrast with the focus of leading metrics on journals (impact factor) or, more recently, on individual researchers (h-index), the article-level metrics makes it possible to track the circulation of individual publications: "(an) article that used to live on a shelf now lives in Mendeley, CiteULike, or Zotero – where we can see and count it"[102] As such they are more compatible with the diversity of publication strategies that has characterized open science: preprints, reports or even non-textual outputs like dataset or software may also have associated metrics.[100] In their original research proposition, Neylon and Wu favored the use of data from reference management software like Zotero or Mendeley.[101] The concept of altmetrics evolved and came to encover data extracted "from social media applications, like blogs, Twitter, ResearchGate and Mendeley.".[100] Social media sources proved especially to be more reliable on a long-term basis, as specialized academic tools like Mendeley came to be integrated into a proprietary ecosystem developed by leading scientific publishers. Major altmetrics indicators that emerged in the 2010s include Altmetric.com, PLUMx and ImpactStory.
As the meaning of altmetrics shifted, the debate over the positive impact of the metrics evolved toward their redefinition in an open science ecosystem: "Discussions on the misuse of metrics and their interpretation put metrics themselves in the center of open science practices."[103] While altmetrics were initially conceived for open science publications and their expanded circulation beyond academic circles, their compatibility with the emerging requirements for open metrics has been brought into question: social network data, in particular, is far from transparent and readily accessible.[104][105] In 2016, Ulrich Herb published a systematic assessment of the leading publications' metrics in regard to open science principles and concluded that "neither citation-based impact metrics nor alternative metrics can be labeled open metrics. They all lack scientific foundation, transparency and verifiability."[106]
| Metric | Provider | Sources | Free access |
Data access |
Open Data |
Open Software |
|---|---|---|---|---|---|---|
| Journal Impact Factor | Clarivate | Citations (Web of Science) | No | No | No | No |
| SCImago Journal Rank | Elsevier | Citations (Scopus) | Yes | Yes | No | No |
| SNIP | Elsevier | Citations (Scopus) | Yes | Yes | No | No |
| Eigenfactor | Clarivate | Citations (Web of Science) | Yes | No | No | No |
| Google Journal Ranking | Google Scholar | Citations (Google) | Yes | No | No | No |
| h-index | Clarivate | Citations (Web of Science) | No | No | No | No |
| h-index | Elsevier | Citations (Scopus) | No | No | No | No |
| h-index | Google Scholar | Citations (Google) | Yes | No | No | No |
| Altmetrics | PLUM Analytics | Varied sources | No | No | No | No |
| Altmetrics | Altmetric (Macmillan) | Varied sources | Partial | No | No | No |
| Altmetrics | PLOS | Varied sources | Yes | Yes | Partial (include proprietary data) | Yes |
| Altmetrics | ImpactStory | Varied sources | Yes | Yes | Partial (include proprietary data) | Yes |
| Open Citation Data | OpenCitations Corpus | Varied sources | Yes | Yes | Yes | Yes |
Herb laid an alternative program for open metrics that have yet to be developed.[108][109] The main criteria included:
- A large selection of publication items (journal articles, books, dataset, software) that agree with the writing and reading practices of scientific communities.[109]
- Fully documented data sources.[109]
- Transparent and reproducible process for the calculation of the metrics and other indices.[109]
- Open software.[109]
- Promotion of reflexive and interpretive uses of the metrics, to prevent their misuse in quantitative assessments.[109]
This definition has been implemented in research programs, like ROSI (Reference implementation for open scientometric indicators).[110] In 2017, the European Commission Expert Group on Altmetrics expanded the open metrics program of Ulrich Herb under a new concept, the Next-generation metrics. These metrics should be managed by "open, transparent and linked data infrastructure".[111] The expert group underline that not everything should be measured and not all metrics are relevants: "Measure what matters: the next generation of metrics should begin with those qualities and impacts that European societies most value and need indices for, rather than those which are most easily collected and measure".[111]
Infrastructure for open citation data
Until the 2010s, the impact of open science movement was largely limited to scientific publications: it "has tended to overlook the importance of social structures and systemic constraints in the design of new forms of knowledge infrastructures."[112] In 1997, Robert D. Cameron called for the development of an open databases of citation that would completely alter the condition of science communication: "Imagine a universal bibliographic and citation database linking every scholarly work ever written—no matter how published—to every work that cites and every work that cites it. Imagine that such a citation database was freely available over the Internet and was updated every day with all the new works published that day, including papers in traditional and electronic journals, conference papers, theses, technical reports, working papers, and preprints."[113] Despite the development of specific indexes focused on open access works like CiteSeer, a large open alternative to the Science Citation Index failed to materialize. The collection of citation data, remained dominated by large commercial structure such as the direct descendant of the Scientific Citation Index, the Web of Science. This had the effect of maintaining the emerging ecosystem of open resources at the periphery of academic networks: "common pool of resources is not governed or managed by the current scholarly commons initiative. There is no dedicated hard infrastructure and though there may be a nascent community, there is no formal membership."[114]
Since 2015, open science infrastructures, platforms and journals have converged to the creation of digital academic commons, increasingly structured around a shared ecosystem of services and standards has emerged through the network of dependencies from one infrastructure to another. This movement stem from an increasingly critical stance toward leading proprietary databases. In 2012, the San Francisco Declaration on Research Assessment (DORA) called for "ending the use of journal impact factors in funding, hiring and promotion decisions."[115] The Leiden Manifesto for research metrics (2015) encouraged the development of "open, transparent and simple" data collection.[73]
Collaborations between academic and non-academic actors collectively committed in the creation and maintenance of knowledge commons has been a determining factor in the creation of new infrastructure for open citation data. Since 2010, a dataset of open citation data, the Open Citation Corpus, has been collected by several researchers from a variety of open access sources (including PLOS and Pubmed).[116] This collection was the initial kernel of the Initiative for OpenCitations, incepted in 2017 in response to issues of data accessibility faced by a Wikimedia project, Wikidata. A conference, given by Dario Taraborelli, head of research at the Wikimedia Foundation showed that only 1% of papers in Crossref had citations metadata that were freely available and references stored on Wikidata were unable to include the very large segment of non-free data. This coverage expanded to more than half of the recorded papers, when Elsevier finally joined the initiative in January 2021.[117]
Since 2021, OpenAlex has become a major open infrastructure for scientific metadata. Initially created as a replacement for the discontinued Microsoft Academic Graph, OpenAlex indexed in 2022 209 millions of scholarly works from 213 millions authors as well as their associated institutions, venues and concepts in a knowledge graph integrated into the semantic web (and Wikidata).[118]. Due to its large coverage and large amount of data properly migrated from the Microsoft Academic Graph (MAG), OpenAlex "seems to be at least as suited for bibliometric analyses as MAG for publication years before 2021."[119] In 2023, a study on the coverage of data journals in scientific indexes found that OpenAlex, along with Dimensions, "enjoy a strong advantage over the two more traditional databases, WoS and Scopus" [120] and is overall especially suited for the indexation of non-journal publications like books[121] or from researchers in non-western countries[122]
The opening of science data has been a major topic of debate in the bibliometrics and scientometrics community and had wide range social and intellectual consequences. In 2019, the entire scientific board of the Journal of Infometrics resigned and created a new open access journals, Quantitative Science Studies. The journal was published by Elsevier since 2007 and the members of the board were increasingly critical of the lack of progress in the open sharing of open citation data: "Our field depends on high-quality scientific metadata. To make our science more robust and reproducible, these data must be as open as possible. Therefore, our editorial board was deeply concerned with the refusal of Elsevier to participate in the Initiative for Open Citations (I4OC)."[123]
Bibliometrics without evaluation: the shift to quantitative science studies
The unprecedented availability of a wide range of scientific productions (publications, data, software, conference, reviews...) has entailed a more dramatic redefinition of the bibliometrics project. For new alternative works anchored in the open science landscape, the principles of bibliometrics as defined by Garfield and Price in the 1960s need to be rethought. The pre-selection of a limited corpus of important journals seem neither necessary nor appropriate. In 2019, the proponents of the Matilda project, "do not want to just "open" the existing closed information, but wish to give back a fair place to the whole academic content that has been excluded from such tools, in a "all texts are born equal" fashion."[124] They aim to "redefine bibliometrics tools as a technology" by focusing on the exploration and mapping of scientific corpus.[125]
Issues of inclusivity and more critical approach of structural inequalities in science have become more prevalent in scientometrics and bibliometrics, especially in relation to gender imbalance.[126][127][128] After 2020, one of the most heated debate in the field[129] revolved around the reception of a study on the gender imbalance in fundamental physics.[130]
The structural shift in the definition of bibliometrics, scientometrics or infometrics has entailed the need for alternative labels. The concept of Quantitative Science Studies was originally introduced in the late 2000s in the context of a renewed critical assessment of classic bibliometric findings.[131] It has become more prevalent in the late 2010s. After leaving Elsevier, the editors of the Journal of Infometrics opted for this new label and created a journal for Quantitative Science Studies. The first editorial removed all references to metric and aimed for a wider inclusion of quantitative and qualitative research on the science of science:
We hope that those who identify under labels such as scientometrics, science of science, and metascience will all find a home in QSS. We also recognize the diverse range of disciplines for whom science is an object of study: We welcome historians of science, philosophers of science, and sociologists of science to our journal. While we bear the moniker of quantitative, we are inclusive of a breadth of epistemological perspectives. Quantitative science studies cannot operate in isolation: Robust empirical work requires the integration of theories and insights from all metasciences.[132]
See also
References
- Hutchins et al. 2019.
- Otlet 1934.
- Rousseau 2014.
- Pritchard 1969.
- Hertzel 2003, p. 288.
- Bellis 2009, p. 3.
- Bellis 2009, p. 12.
- Bellis 2009, p. 4.
- Jovanovic 2012.
- Bellis 2009, p. 2.
- Godin 2006.
- Danesh & Mardani-Nejad 2020.
- Hertzel 2003, p. 292.
- Bellis 2009, p. 6.
- Bellis 2009, p. 23.
- Bellis 2009, p. 1.
- Bellis 2009, p. 7.
- Cole & Eales 1917, p. 578.
- Hulme 1923, p. 43.
- Bellis 2009, p. 14.
- Bellis 2009, p. 9.
- Gross & Gross 1927, p. 387.
- Gross & Gross 1927, p. 388.
- Bellis 2009, p. 75.
- Bellis 2009, p. 92.
- Bellis 2009, p. 99.
- Wouters 1999, p. 61.
- Wouters 1999, p. 62.
- Bellis 2009, p. 10.
- Bellis 2009, p. 52.
- Bellis 2009, p. 27.
- Luhn 1957.
- Wouters 1999, p. 60.
- Wouters 1999, p. 64.
- Bourne & Hahn 2003, p. 16.
- Bourne & Hahn 2003, p. 12.
- Bellis 2009, p. 30.
- Bellis 2009, p. 34.
- Bellis 2009, p. 53.
- Bellis 2009, p. 35.
- Bellis 2009, p. 36.
- Bellis 2009, p. 37.
- Bellis 2009, p. 49.
- Sugimoto & Larivière 2018, p. 8.
- Bellis 2009, p. 57.
- Bellis 2009, p. 62.
- Price 1975, p. 162.
- Bellis 2009, p. 65.
- Bellis 2009, p. 67.
- Bellis 2009, p. 103.
- Bellis 2009, p. 104.
- Bellis 2009, p. 187.
- Bellis 2009, p. 186.
- "Nature". 2017 Journal Citation Reports (PDF) (Report). Web of Science (Science ed.). Thomson Reuters. 2018.
- Bellis 2009, p. 194.
- Bellis 2009, p. 153.
- Bellis 2009, p. 173.
- Hogan 2014, p. 20.
- Tim Berners-Lee, "Qualifiers on Hypertext Links", mail sent on 6 August 1991 to the alt.hypertext
- Star & Ruhleder 1996, p. 131.
- Bellis 2009, p. 285.
- Bellis 2009, pp. 31–32.
- Bellis 2009, p. 289.
- Bellis 2009, p. 322.
- Aspesi et al. 2019, p. 5.
- Chen et al. 2019, par. 25.
- Chen et al. 2019, par. 29.
- Moore 2019, p. 156.
- Chen et al. 2019.
- Wainwright & Bervejillo 2021.
- Wainwright & Bervejillo 2021, p. 211.
- Ball 2020, p. 504.
- Hicks et al. 2015, p. 430.
- David & Frangopol 2015.
- Schaer 2013.
- "Library Guides: Citation & Research Management: Best Practice: Bibliometrics, Citation Analysis". Berkeley Libraries. Archived from the original on 27 July 2020. Retrieved 30 May 2020.
- "Bibliometrics and Citation Analysis: Home". Research Guides. University 0f Wisconsin-Madison Libraries. Retrieved 30 May 2020.
- Steve Kolowich (15 December 2009). "Tenure-o-meter". Inside Higher Ed. This article refers to the bibliometrics tool now known as Scholarometer.
- Hoang, Kaur & Menczer 2010.
- Nicholas & Ritchie 1978, pp. 12–28.
- Nicholas & Ritchie 1978, pp. 28–29.
- Henderson, Shurville & Fernstrom 2009.
- Higher Education Funding Council for England (3 July 2009). "Research Excellence Framework". www.hefce.ac.uk. Archived from the original on 4 July 2009. Retrieved 20 July 2009.
- Higher Education Funding Council for England (8 July 2015). "Metrics cannot replace peer review in the next REF". www.hefce.ac.uk. Archived from the original on 19 July 2018. Retrieved 20 March 2016.
- Biagioli 2020, p. 18.
- Linnenluecke, Marrone & Singh 2020.
- Diem & Wolter 2012.
- Kurtz & Bollen 2010.
- Jovanovic 2020.
- Hovden 2013.
- Aristovnik, Ravšelj & Umek 2020.
- Fernández-Ramos et al. 2019.
- Denise Wolfe (7 April 2020). "SUNY Negotiates New, Modified Agreement with Elsevier". Libraries News Center. University at Buffalo Libraries. Retrieved 18 April 2020.
- Bellis 2009, p. 288 sq..
- Heck 2020.
- Bellis 2009, p. 336.
- Torny, Capelli & Danjean 2019, p. 1.
- Sugimoto & Larivière 2018, p. 70.
- Bellis 2009, p. 300.
- Wilsdon et al. 2017, p. 9.
- Neylon & Wu 2009.
- Priem et al. 2011, p. 3.
- Heck 2020, p. 513.
- Bornmann & Haunschild 2016.
- Tunger & Meier 2020.
- Herb 2016, p. 60.
- Herb 2016.
- Herb 2012, p. 29.
- Herb 2016, p. 70.
- Hauschke et al. 2018.
- Wilsdon et al. 2017, p. 15.
- Okune et al. 2018, p. 13.
- Cameron 1997.
- Bosman et al. 2018, p. 19.
- Wilsdon et al. 2017, p. 7.
- Peroni et al. 2015.
- Waltman, Ludo (22 December 2020). "Q&A about Elsevier's decision to open its citations". Leiden Madtrics. Universiteit Leiden. Retrieved 11 June 2021.
- Priem, Piwowar & Orr 2022, p. 1-2.
- Scheidsteger & Haunschild 2022, p. 10.
- Jiao, Li & Fang 2023, p. 14.
- Laakso 2023, p. 166.
- Akbaritabar, Theile & Zagheni 2023.
- Waltman et al. 2020, p. 1.
- Torny, Capelli & Danjean 2019, p. 2.
- Torny, Capelli & Danjean 2019, p. 7.
- Larivière et al. 2013.
- Torny, Capelli & Danjean 2019.
- Chary et al. 2021.
- Gingras 2022.
- Strumia 2021.
- Glänzel 2008.
- Waltman et al. 2020.
Bibliography
Books & thesis
- Bourne, Charles P.; Hahn, Trudi Bellardo (1 August 2003). A History of Online Information Services, 1963–1976. MIT Press. ISBN 978-0-262-26175-3.
- Candolle, Alphonse de (1885). "Histoire des sciences et des savants depuis deux siècles". Lilliad Université de Lille – Sciences et Technologies. Genève: M. Georg. Retrieved 16 March 2022.
- Campbell, Francis Bunbury Fitzgerald; Campbell, Frank (1896). The Theory of National and International Bibliography: With Special Reference to the Introduction of System in the Record of Modern Literature. Library Bureau.
- Hulme, Edward Wyndham (1923). Statistical bibliography in relation to the growth of modern civilization : two lectures delivered in the University of Cambridge in May, 1922. London : Hulme. Retrieved 16 March 2022.
- Otlet, Paul (1934). Traité de Documentation: Le Livre sur le Livre. Théorie et Pratique. Bruxelles: Editiones Mundaneum.
- Price, Derek John de Solla (1975). Science Since Babylon. Yale University Press. ISBN 978-0-300-01798-4.
- Nicholas, David; Ritchie, Maureen (1978). Literature and Bibliometrics. London: Clive Bingley.
- Wouters, P. F. (1999). The citation culture (Thesis). Retrieved 9 September 2018.
- Godin, Benoît (2009). The Making of science, technology and innovation policy: conceptual frameworks as narratives, 1945–2005. Montréal: Institut national de la recherche scientifique, Centre Urbanisation Culture Société. Retrieved 16 March 2022.
- Bellis, Nicola De (9 March 2009). Bibliometrics and Citation Analysis: From the Science Citation Index to Cybermetrics. Scarecrow Press. ISBN 978-0-8108-6714-7.
- Cronin, Blaise; Sugimoto, Cassidy R. (16 May 2014). Beyond Bibliometrics: Harnessing Multidimensional Indicators of Scholarly Impact. MIT Press. ISBN 978-0-262-32329-1.
- Hogan, A. (9 April 2014). Reasoning Techniques for the Web of Data. IOS Press. ISBN 978-1-61499-383-4.
- Gingras, Yves (30 September 2016). Bibliometrics and Research Evaluation: Uses and Abuses. MIT Press. ISBN 978-0-262-33766-3.
- Ball, Rafael (18 September 2017). An Introduction to Bibliometrics: New Development and Trends. Chandos Publishing. ISBN 978-0-08-102151-4.
- Sugimoto, Cassidy R.; Larivière, Vincent (2018). Measuring Research: What Everyone Needs to Know. Oxford University Press. ISBN 978-0-19-064011-8.
- Moore, Samuel (2019). Common Struggles: Policy-based vs. scholar-led approaches to open access in the humanities (thesis deposit) (Thesis). King's College London. Retrieved 11 December 2021.
- Biagioli, Mario (2020). Gaming the metrics: misconduct and manipulation in academic research. Cambridge, Massachusetts: The MIT Press. ISBN 978-0-262-53793-3. OCLC 1130310967.
- Gozlan, Clémentine (6 April 2021). Les valeurs de la science: Enquête sur les réformes de l'évaluation de la recherche en France. ENS Éditions. ISBN 979-10-362-0262-9.
Journal articles
- Cattell, J. McKeen (1903). "Statistics of American Psychologists". The American Journal of Psychology. 14 (3/4): 310–328. doi:10.2307/1412321. ISSN 0002-9556. JSTOR 1412321.
- Cole, F. J.; Eales, Nellie B. (1917). "The history of comparative anatomy – A statistical analysis of the literature". Science Progress. 11 (44): 578–596. ISSN 2059-495X. JSTOR 43426882.
- Lotka, Alfred J. (1926). "The frequency distribution of scientific productivity". Journal of the Washington Academy of Sciences. 16 (12): 8.
- Gross, P. L. K.; Gross, E. M. (28 October 1927). "College Libraries and Chemical Education". Science. 66 (1713): 385–389. Bibcode:1927Sci....66..385G. doi:10.1126/science.66.1713.385. PMID 17782476.
- Luhn, H. P. (October 1957). "A Statistical Approach to Mechanized Encoding and Searching of Literary Information". IBM Journal of Research and Development. 1 (4): 309–317. doi:10.1147/rd.14.0309. ISSN 0018-8646. S2CID 15879823.
- Pritchard, Alan (1969). "Statistical Bibliography or Bibliometrics?". Journal of Documentation. 25: 348–349. Retrieved 6 January 2015.
- Star, Susan Leigh; Ruhleder, Karen (1 March 1996). "Steps Toward an Ecology of Infrastructure: Design and Access for Large Information Spaces". Information Systems Research. 7 (1): 111–134. doi:10.1287/isre.7.1.111. ISSN 1047-7047. S2CID 10520480. Retrieved 22 December 2021.
- Cameron, Robert D. (7 April 1997). "A Universal Citation Database". First Monday. doi:10.5210/fm.v2i4.522. ISSN 1396-0466. Retrieved 21 March 2022.
- Godin, Benoît (26 July 2006). "On the origins of bibliometrics". Scientometrics. 68 (1): 109–133. doi:10.1007/s11192-006-0086-0. ISSN 0138-9130. S2CID 32674188. Retrieved 16 March 2022.
- Godin, Benoît (1 October 2007). "From Eugenics to Scientometrics: Galton, Cattell and Men of Science". Social Science Information. 37 (5): 691–728. doi:10.1177/0306312706075338. JSTOR 25474544. PMID 18348397. S2CID 13166578. "Original" (PDF). 2006. Retrieved 26 March 2022.
- Godin, Benoît (17 November 2009). "The Value of Science: Changing Conceptions of Scientific Productivity, 1869-circa 1970". Social Science Information. 48 (4): 547–586. doi:10.1177/0539018409344475. S2CID 145245489. "Original" (PDF). 2006. Retrieved 26 March 2022.
- Glänzel, Wolfgang (1 June 2008). "Seven Myths in Bibliometrics About facts and fiction in quantitative science studies". COLLNET Journal of Scientometrics and Information Management. 2 (1): 9–17. doi:10.1080/09737766.2008.10700836. ISSN 0973-7766. S2CID 44206336.
- Henderson, Michael; Shurville, Simon; Fernstrom, Ken (2009). "The quantitative crunch". Campus-Wide Information Systems. 26 (3): 149–167. doi:10.1108/10650740910967348.
- Neylon, Cameron; Wu, Shirley (17 November 2009). "Article-Level Metrics and the Evolution of Scientific Impact". PLOS Biology. 7 (11): –1000242. doi:10.1371/journal.pbio.1000242. ISSN 1545-7885. PMC 2768794. PMID 19918558.
- Kurtz, Michael J.; Bollen, Johan (2010). "Usage bibliometrics". Annual Review of Information Science and Technology. 44 (1): 3. arXiv:1102.2891. Bibcode:2010ARIST..44....3K. doi:10.1002/aris.2010.1440440108. ISSN 1550-8382. S2CID 484831.
- Hoang D, Kaur J, Menczer F (26–27 April 2010). "Crowdsourcing Scholarly Data" (PDF). Proceedings of the WebSci10: Extending the Frontiers of Society On-Line. Raleigh, NC. Archived from the original (PDF) on 8 April 2015. Retrieved 25 May 2010.
- Priem, Jason; Taraborelli, Dario; Groth, Paul; Neylon, Cameron (2011). "altmetrics: a manifesto". Lincoln: University of Nebraska. p. 5.
- Jovanovic, Milos (5 April 2012). "Eine kleine Frühgeschichte der Bibliometrie" [A short history of early bibliometrics]. Information – Wissenschaft & Praxis (in German). 63 (2): 71–80. doi:10.1515/iwp-2012-0017. S2CID 32450731.
- Diem, Andrea; Wolter, Stefan C. (6 June 2012). "The Use of Bibliometrics to Measure Research Performance in Education Sciences" (PDF). Research in Higher Education. 54 (1): 86–114. doi:10.1007/s11162-012-9264-5. ISSN 0361-0365. S2CID 144986574.
- Hovden, R. (2013). "Bibliometrics for Internet media: Applying the h-index to YouTube". Journal of the American Society for Information Science and Technology. 64 (11): 2326–2331. arXiv:1303.0766. doi:10.1002/asi.22936. S2CID 38708903.
- Schaer, Philipp (2013). "Applied Informetrics for Digital Libraries: An Overview of Foundations, Problems and Current Approaches". Historical Social Research. 38 (3): 267–281. doi:10.12759/hsr.38.2013.3.267-281.
- Larivière, Vincent; Ni, Chaoqun; Gingras, Yves; Cronin, Blaise; Sugimoto, Cassidy R. (December 2013). "Bibliometrics: Global gender disparities in science". Nature. 504 (7479): 211–213. doi:10.1038/504211a. ISSN 1476-4687. PMID 24350369. S2CID 38026327. Retrieved 21 March 2022.
- Rousseau, Ronald (2014). "Library Science: Forgotten Founder of Bibliometrics". Nature. 510 (7504): 218. Bibcode:2014Natur.510..218R. doi:10.1038/510218e. PMID 24919911.
- Thompson, Dennis F.; Walker, Cheri K. (2015). "A Descriptive and Historical Review of Bibliometrics with Applications to Medical Sciences". Pharmacotherapy. 35 (6): 551–559. doi:10.1002/phar.1586. ISSN 1875-9114. PMID 25940769. S2CID 206358632.
- Peroni, Silvio; Dutton, Alexander; Gray, Tanya; Shotton, David (2015). "Setting our bibliographic references free: towards open citation data". Journal of Documentation. 71 (2): 253–277. doi:10.1108/JD-12-2013-0166. ISSN 0022-0418.
- Hicks, Diana; Wouters, Paul; Waltman, Ludo; de Rijcke, Sarah; Rafols, Ismael (April 2015). "Bibliometrics: The Leiden Manifesto for research metrics". Nature. 520 (7548): 429–431. Bibcode:2015Natur.520..429H. doi:10.1038/520429a. ISSN 1476-4687. PMID 25903611. S2CID 4462115. Retrieved 22 March 2022.
- David, Daniel; Frangopol, Petre (1 December 2015). "The lost paradise, the original sin, and the Dodo bird: a scientometrics Sapere Aude manifesto as a reply to the Leiden manifesto on scientometrics". Scientometrics. 105 (3): 2255–2257. doi:10.1007/s11192-015-1634-2. ISSN 1588-2861. S2CID 28104352.
- Herb, Ulrich (1 January 2016). "Impactmessung, Transparenz & Open Science". Young Information Scientist. 1: 59–79. doi:10.5281/zenodo.153831.
- Bornmann, Lutz; Haunschild, Robin (2016). "To what extent does the Leiden manifesto also apply to altmetrics? A discussion of the manifesto against the background of research into altmetrics". Online Information Review. 40 (4): 529–543. doi:10.1108/OIR-09-2015-0314. ISSN 1468-4527.
- Csiszar, Alex (March 2017). "How lives became lists and scientific papers became data: cataloguing authorship during the nineteenth century". The British Journal for the History of Science. 50 (1): 23–60. doi:10.1017/S0007087417000012. ISSN 0007-0874. PMID 28202102. S2CID 41853820. Retrieved 16 March 2022.
- Chan, Leslie; Posada, Alejandro; Albornoz, Denisse; Hillyer, Rebecca; Okune, Angela (June 2018). "Whose Infrastructure? Towards Inclusive and Collaborative Knowledge Infrastructures in Open Science". ELectronic PUBlishing. doi:10.4000/proceedings.elpub.2018.31. S2CID 65726844. Retrieved 22 December 2021.
- Bosman, Jeroen; Bruno, Ian; Chapman, Chris; Tzovaras, Bastian Greshake; Jacobs, Nate; Kramer, Bianca; Martone, Maryann Elizabeth; Murphy, Fiona; O'Donnell, Daniel Paul; Bar-Sinai, Michael; Hagstrom, Stephanie; Utley, Josh; Veksler, Lusia Ludmila (15 September 2017). "The Scholarly Commons – principles and practices to guide research communication". OSF Preprints. Retrieved 7 January 2022.
- Hauschke, Christian; Cartellieri, Simone; Heller, Lambert (15 November 2018). "Reference implementation for open scientometric indicators (ROSI)". Research Ideas and Outcomes. 4: 31656. doi:10.3897/rio.4.e31656. ISSN 2367-7163. S2CID 70336574. Retrieved 24 April 2022.
- Torny, Didier; Capelli, Laurent; Danjean, Lydie (14 June 2019). "ELPUB 2019 23d International Conference on Electronic Publishing". ELPUB 2019 23d International Conference on Electronic Publishing. ELPUB 2019 23d International Conference on Electronic Publishing. OpenEdition Press. doi:10.4000/proceedings.elpub.2019.22.
- Hutchins BI, Baker KL, Davis MT, Diwersy MA, Haque E, Harriman RM, Hoppe TA, Leicht SA, Meyer P, Santangelo GM (October 2019). "The NIH Open Citation Collection: A public access, broad coverage resource". PLOS Biology. 17 (10). e3000385. doi:10.1371/journal.pbio.3000385. PMC 6786512. PMID 31600197.
- Fernández-Ramos, Andrés; Rodríguez Bravo, María Blanca; Alvite Díez, María Luisa; Santos de Paz, Lourdes; Morán Suárez, María Antonia; Gallego Lorenzo, Josefa; Olea Merino, Isabel (2019). "Evolución del uso de los big deals en las universidades públicas de Castilla y León" [Evolution of the big deals use in the public universities of the Castile and Leon region, Spain]. El Profesional de la Información (in Spanish). 28 (6). doi:10.3145/epi.2019.nov.19.
- Waltman, Ludo; Larivière, Vincent; Milojević, Staša; Sugimoto, Cassidy R. (1 February 2020). "Opening science: The rebirth of a scholarly journal". Quantitative Science Studies. 1 (1): 1–3. doi:10.1162/qss_e_00025. ISSN 2641-3337. S2CID 211212402.
- Linnenluecke, Martina K.; Marrone, Mauricio; Singh, Abhay K. (May 2020). "Conducting systematic literature reviews and bibliometric analyses". Australian Journal of Management. 45 (2): 175–194. doi:10.1177/0312896219877678. ISSN 0312-8962. S2CID 211378937.
- Aristovnik A, Ravšelj D, Umek L (November 2020). "A Bibliometric Analysis of COVID-19 across Science and Social Science Research Landscape". Sustainability. 12 (21). 9132. doi:10.3390/su12219132.
- Wainwright, Joel; Bervejillo, Guillermo (January 2021). "Leveraging monopoly power up the value chain: Academic publishing in an era of surveillance capitalism". Geoforum. 118: 210–212. doi:10.1016/j.geoforum.2020.04.012. ISSN 0016-7185. S2CID 234328559.
- Strumia, Alessandro (8 April 2021). "Gender issues in fundamental physics: A bibliometric analysis". Quantitative Science Studies. 2 (1): 225–253. doi:10.1162/qss_a_00114. ISSN 2641-3337. S2CID 233874607.
- Chary, Sowmya; Amrein, Karin; Soeteman, Djøra I.; Mehta, Sangeeta; Christopher, Kenneth B. (2 July 2021). "Gender disparity in critical care publications: a novel Female First Author Index". Annals of Intensive Care. 11 (1): 103. doi:10.1186/s13613-021-00889-3. ISSN 2110-5820. PMC 8253865. PMID 34213685.
- Gingras, Yves (12 April 2022). "Towards a moralization of bibliometrics? A response to Kyle Siler". Quantitative Science Studies. 3 (1): 315–318. doi:10.1162/qss_c_00178. ISSN 2641-3337. S2CID 248102517.
- Akbaritabar, Aliakbar; Theile, Tom; Zagheni, Emilio (2023). "Global flows and rates of international migration of scholars". MPIDR Working Papers. Retrieved 7 September 2023.
- Jiao, Chenyue; Li, Kai; Fang, Zhichao (18 July 2023). "How are exclusively data journals indexed in major scholarly databases? An examination of the Web of Science, Scopus, Dimensions, and OpenAlex". arXiv:2307.09704.
{{cite journal}}: Cite journal requires|journal=(help) - Laakso, Mikael (1 January 2023). "Open access books through open data sources: assessing prevalence, providers, and preservation". Journal of Documentation. 79 (7): 157–177. doi:10.1108/JD-02-2023-0016. ISSN 0022-0418. S2CID 259300771. Retrieved 7 September 2023.
Book sections
- Hertzel, Dorothy H. (20 May 2003). "Bibliometrics history". Encyclopedia of Library and Information Science (2nd ed.). CRC Press. ISBN 978-0-8247-2077-3.
- Raan, Ton (2004). "Measuring Science Capita Selecta of current main issues.". Handbook of quantitative science and technology research: the use of publication and patent statistics in studies of S&T systems. Dordrecht: Kluwer. pp. 19–50. ISBN 978-1-4020-2702-4.
- Herb, Ulrich (2012), "Offenheit und wissenschaftliche Werke: Open Access, Open Review, Open Metrics, Open Science & Open Knowledge", in Ulrich Herb (ed.), Open Initiatives : Offenheit in der digitalen Welt und Wissenschaft, Saarbrücker Schriften zur Informationswissenschaft, Saarbrücken: universaar, pp. 11–44, ISBN 978-3-86223-061-7
- Chen, George; Posada, Alejandro; Chan, Leslie (2 June 2019). "Vertical Integration in Academic Publishing : Implications for Knowledge Inequality". In Pierre Mounier (ed.). Connecting the Knowledge Commons – From Projects to Sustainable Infrastructure : The 22nd International Conference on Electronic Publishing – Revised Selected Papers. Laboratoire d'idées. Marseille: OpenEdition Press. ISBN 979-10-365-3802-5. Retrieved 26 February 2022.
- Ball, Rafael, ed. (7 December 2020). Handbook Bibliometrics. De Gruyter Saur. doi:10.1515/9783110646610. ISBN 978-3-11-064661-0. S2CID 243656614.
- Danesh, Farshid; Mardani-Nejad, Ali (7 December 2020). "1.1 A Historical Overview of Bibliometrics". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 7–18. doi:10.1515/9783110646610-003. ISBN 978-3-11-064661-0. S2CID 235861940.
- Taubert, Niels (7 December 2020). "1.2 Institutionalization and Professionalization of Bibliometrics". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 19–26. doi:10.1515/9783110646610-004. ISBN 978-3-11-064661-0. S2CID 235860965.
- Pendlebury, David A. (7 December 2020). "1.3 Eugene Garfield and the Institute for Scientific Information". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 27–40. doi:10.1515/9783110646610-005. ISBN 978-3-11-064661-0. S2CID 235861751.
- Danesh, Farshid; Mardani-Nejad, Ali (7 December 2020). "1.4 Derek De Solla Price: The Father of Scientometrics". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 41–52. doi:10.1515/9783110646610-006. ISBN 978-3-11-064661-0. S2CID 235871925.
- Tunger, Dirk; Meier, Andreas (7 December 2020). "4.1 The Future Has Already Begun: Origin, Classification, and Applications of Altmetrics in Scholarly Communication". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 181–190. doi:10.1515/9783110646610-019. ISBN 978-3-11-064661-0. S2CID 235879114.
- Ball, Rafael (7 December 2020). "8.1 The Future of Bibliometrics: Where is Bibliometrics Heading?". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 499–506. doi:10.1515/9783110646610-045. ISBN 978-3-11-064661-0. S2CID 235878741.
- Heck, Tamara (7 December 2020). "8.2 Open Science and the Future of Metrics". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 507–516. doi:10.1515/9783110646610-046. ISBN 978-3-11-064661-0. S2CID 235861958.
- Jovanovic, Milos (7 December 2020). "5.3 Technological Trend Analysis". In Ball, Rafael (ed.). Handbook Bibliometrics. De Gruyter Saur. pp. 311–318. doi:10.1515/9783110646610-031. ISBN 978-3-11-064661-0. S2CID 242988619.
Reports
- Wilsdon, James; Allen, Liz; Belfiore, Eleonora; Campbell, Philip; Curry, Stephen; Hill, Steven; Jones, Richard; Kain, Roger; Kerridge, Simon; Thelwall, Mike; Tinkler, Jane; Viney, Ian; Wouters, Paul; Hill, Jude; Johnson, Ben (9 July 2015). The Metric Tide: Report of the Independent Review of the Role of Metrics in Research Assessment and Management (Report).
- Wilsdon, James; Bar Ilan, Judit; Frodeman, Robert; Lex, Elisabeth; Peters; Wouters., Paul (2017). Next-generation metrics: responsible metrics and evaluation for open science (Report). LU: European Commission Publications Office. doi:10.2777/337729. Retrieved 24 April 2022.
- European Commission. Directorate General for Research and Innovation. (2017). Evaluation of research careers fully acknowledging Open Science practices: rewards, incentives and/or recognition for researchers practicing Open Science (Report). LU: Publications Office. doi:10.2777/75255. Retrieved 24 April 2022.
- Aspesi, Claudio; Allen, Nicole Starr; Crow, Raym; Daugherty, Shawn; Joseph, Heather; McArthur, Joseph; Shockey, Nick (3 April 2019). SPARC Landscape Analysis: The Changing Academic Publishing Industry – Implications for Academic Institutions (Report). LIS Scholarship Archive. Retrieved 5 January 2022.
- Bauer, Ingrid; Bohmert, David; Czernecka, Alexandra; Eichenberger, Thomas; Garbajosa, Juan; Iovu, Horia; Kinnaird, Yvonne; Madeira, Ana Carla; Nygard, Mads; Per-Anders Östling; Räder, Susanne; Ravera, Mario; Per-Eric Thörnström; Wit, Kurt De (10 June 2020). Next Generation Metrics (Report). Retrieved 24 April 2022.
Conferences
- Priem, Jason; Piwowar, Heather; Orr, Richard (16 June 2022). OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. STI 2022. arXiv:2205.01833.
- Scheidsteger, Thomas; Haunschild, Robin (2022). Comparison of metadata with relevance for bibliometrics between Microsoft Academic Graph and OpenAlex until 2020. STI 2022. arXiv:2206.14168. doi:10.5281/zenodo.6975102.
External links
- The Research HUB published a full-length freely accessible Bibliometric Analysis video tutorial playlist.