Stack-oriented programming
Stack-oriented programming is a programming paradigm that relies on a stack machine model for passing parameters. Stack-oriented programming languages operate on one or more stacks, each of which may serve a different purpose. Programming constructs in other programming languages need to be modified for use in a stack-oriented system.[1] Most stack-oriented languages operate in postfix or Reverse Polish notation. Any arguments or parameters for a command are stated before that command. For example, postfix notation would be written 2, 3, multiply instead of multiply, 2, 3 (prefix or Polish notation), or 2 multiply 3 (infix notation). The programming languages Forth, Factor, RPL, PostScript, BibTeX style design language[2] and many assembly languages fit this paradigm.
Stack-based algorithms consider data, by utilising one piece of data from atop the stack, and returning data back atop the stack. The need for stack manipulation operators, allow for the stack to manipulate data. To emphasise the effect of a statement, a comment is used showing the top of the stack before and after the statement. This is known as the stack effect diagram. Postscript stacks consider separate stacks for additional purposes. This considers variables, dictionaries, procedures, anatomy of some typical procedures, control and flow. The analysis of the language model allows expressions and programs to be interpreted simply and theoretically.
Stack-based algorithms
PostScript is an example of a postfix stack-based language. An expression example in this language is 2 3 mul. Calculating the expression involves understanding how stack-orientation works.
Stack-orientation can be presented as the following conveyor belt analogy. at the end of a conveyor belt (the input), plates marked 2, 3, and mul are placed in sequence. The plate at the end of the conveyor (2) can be taken, however other plates cannot be accessed until the plate at the end is removed. The plates can only be stored in a stack, and can only be added or removed from atop the stack, not from the middle or bottom. Blank plates (and a marker) can be supplied and plates can be permanently discarded.
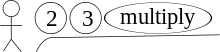
Take plate 2 and put it on the stack, then take plate 3 and put it on the stack. Next, take the mul plate. This is an instruction to perform. Then, take the top two plates off the stack, multiply their labels (2 and 3), and write the result (6) on a new plate. Discard the two old plates (2 and 3) and the plate mul, and put the new plate on the stack. With no more plates remaining on the conveyor, the result of the calculation (6) is shown on the plate atop the stack.
This is a very simple calculation. What if a more complex calculation is needed, such as (2 + 3) × 11 + 1? If it is first written in postfix form, that is, 2 3 add 11 mul 1 add,
the calculation can be performed in exactly the same manner and achieve the correct result. The steps of the calculation are shown in the table below. Each column shows an input element (the plate at the end of the conveyor), and the contents of the stack after processing that input.
| Input | 2 | 3 | add | 11 | mul | 1 | add |
|---|---|---|---|---|---|---|---|
| Stack | 2 | 3 2 |
5 | 11 5 |
55 | 1 55 |
56 |
After processing all the input, the stack contains 56, which is the answer.
From this, the following can be concluded: a stack-based programming language has only one way to handle data, by taking one piece of data from atop the stack, termed popping, and putting data back atop the stack, termed pushing. Any expression that can be written conventionally, or in another programming language, can be written in postfix (or prefix) form and thus be amenable to being interpreted by a stack-oriented language.
Stack manipulation
Since the stack is the key means to manipulate data in a stack-oriented language, such languages often provide some sort of stack manipulation operators. Commonly provided are dup, to duplicate the element atop the stack, exch (or swap), to exchange elements atop the stack (the first becomes second and the second becomes first), roll, to cyclically permute elements in the stack or on part of the stack, pop (or drop), to discard the element atop the stack (push is implicit), and others. These become key in studying procedures.
Stack effect diagrams
As an aid to understanding the effect of statement, a short comment is used showing the top of the stack before and after the statement. The top of the stack is rightmost if there are multiple items. This notation is commonly used in the Forth language, where comments are enclosed in parentheses.
( before -- after )
For example, the basic Forth stack operators are described:
dup ( a -- a a )
drop ( a -- )
swap ( a b -- b a )
over ( a b -- a b a )
rot ( a b c -- b c a )
And the fib function below is described:
fib ( n -- n' )
It is equivalent to preconditions and postconditions in Hoare logic. Both comments may also be referenced as assertions, though not necessarily in context of Stack-based languages.
PostScript stacks
PostScript and some other stack languages have other separate stacks for other purposes.
Variables and dictionaries
The evaluation of different expressions has already been analysed. The implementation of variables is important for any programming language, but for stack-oriented languages it is of special concern, as there is only one way to interact with data.
The way variables are implemented in stack-oriented languages such as PostScript usually involves a separate, specialized stack which holds dictionaries of key–value pairs. To create a variable, a key (the variable name) must be created first, with which a value is then associated. In PostScript, a name data object is prefixed with a /, so /x is a name data object which can be associated with, for example, the number 42. The define command is def, so
/x 42 def
associates with the name x with the number 42 in the dictionary atop the stack. A difference exists between /x and x – the former is a data object representing a name, x stands for what is defined under /x.
Procedures
A procedure in a stack-based programming language is treated as a data object in its own right. In PostScript, procedures are denoted between { and }.
For example, in PostScript syntax,
{ dup mul }
represents an anonymous procedure to duplicate what is on the top of the stack and then multiply the result – a squaring procedure.
Since procedures are treated as simple data objects, names with procedures can be defined. When they are retrieved, they are executed directly.
Dictionaries provide a means of controlling scoping, as well as storing of definitions.
Since data objects are stored in the top-most dictionary, an unexpected ability arises naturally: when looking up a definition from a dictionary, the topmost dictionary is checked, then the next, and so on. If a procedure is defined that has the same name as another already defined in a different dictionary, the local one will be called.
Anatomy of some typical procedures
Procedures often take arguments. They are handled by the procedure in a very specific way, different from that of other programming languages.
To examine a Fibonacci number program in PostScript:
/fib
{
dup dup 1 eq exch 0 eq or not
{
dup 1 sub fib
exch 2 sub fib
add
} if
} def
A recursive definition is used on the stack. The Fibonacci number function takes one argument. First, it is tested for being 1 or 0.
Decomposing each of the program's key steps, reflecting the stack, assuming calculation of fib(4) :
stack: 4
dup
stack: 4 4
dup
stack: 4 4 4
1 eq
stack: 4 4 false
exch
stack: 4 false 4
0 eq
stack: 4 false false
or
stack: 4 false
not
stack: 4 true
Since the expression evaluates to true, the inner procedure is evaluated.
stack: 4
dup
stack: 4 4
1 sub
stack: 4 3
fib
- (recursive call here)
stack: 4 F(3)
exch
stack: F(3) 4
2 sub
stack: F(3) 2
fib
- (recursive call here)
stack: F(3) F(2)
add
stack: F(3)+F(2)
which is the expected result.
This procedure does not use named variables, purely the stack. Named variables can be created by using the /a exch def construct. For example, {/n exch def n n mul}
is a squaring procedure with a named variable n. Assuming that /sq {/n exch def n n mul} def and 3 sq is called, the procedure sq is analysed in the following way:
stack: 3 /n
exch
stack: /n 3
def
stack: empty (it has been defined)
n
stack: 3
n
stack: 3 3
mul
stack: 9
which is the expected result.
Control and flow
As there exist anonymous procedures, flow control can arise naturally. Three pieces of data are required for an if-then-else statement: a condition, a procedure to be done if the condition is true, and one to be done if the condition is false. In PostScript for example,
2 3 gt { (2 is greater than three) = } { (2 is not greater than three) = } ifelse
performs the near equivalent in C:
if (2 > 3) { printf("2 is greater than three\n"); } else { printf("2 is not greater than three\n"); }
Looping and other constructs are similar.
Analysis of the language model
The simple model provided in a stack-oriented language allows expressions and programs to be interpreted simply and theoretically evaluated much faster, since no syntax analysis need be done, only lexical analysis. The way such programs are written facilitates being interpreted by machines, which is why PostScript suits printers well for its use. However, the slightly artificial way of writing PostScript programs can form an initial barrier to understanding stack-oriented languages such as PostScript.
While the ability to shadow by overriding inbuilt and other definitions can make programs hard to debug, and irresponsible use of this feature can cause unpredictable behaviour, it can simplify some functions greatly. For example, in PostScript use, the showpage operator can be overridden with a custom one that applies a certain style to the page, instead of having to define a custom operator or to repeat code to generate the style.
See also
References
- Luerweg, T. (2015). Stack based programming paradigms. Concepts of Programming Languages–CoPL’15, 33.
- Oren Patashnik, Designing BibTeX styles (PDF)