Hashed array tree
In computer science, a hashed array tree (HAT) is a dynamic array data-structure published by Edward Sitarski in 1996,[1] maintaining an array of separate memory fragments (or "leaves") to store the data elements, unlike simple dynamic arrays which maintain their data in one contiguous memory area. Its primary objective is to reduce the amount of element copying due to automatic array resizing operations, and to improve memory usage patterns.
Whereas simple dynamic arrays based on geometric expansion waste linear (Ω(n)) space, where n is the number of elements in the array, hashed array trees waste only order O(√n) storage space. An optimization of the algorithm allows elimination of data copying completely, at a cost of increasing the wasted space.
It can perform access in constant (O(1)) time, though slightly slower than simple dynamic arrays. The algorithm has O(1) amortized performance when appending a series of objects to the end of a hashed array tree. Contrary to its name, it does not use hash functions.
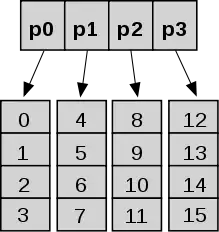
Definitions
As defined by Sitarski, a hashed array tree has a top-level directory containing a power of two number of leaf arrays. All leaf arrays are the same size as the top-level directory. This structure superficially resembles a hash table with array-based collision chains, which is the basis for the name hashed array tree. A full hashed array tree can hold m2 elements, where m is the size of the top-level directory.[1] The use of powers of two enables faster physical addressing through bit operations instead of arithmetic operations of quotient and remainder[1] and ensures the O(1) amortized performance of append operation in the presence of occasional global array copy while expanding.
Expansions and size reductions
In a usual dynamic array geometric expansion scheme, the array is reallocated as a whole sequential chunk of memory with the new size a double of its current size (and the whole data is then moved to the new location). This ensures O(1) amortized operations at a cost of O(n) wasted space, as the enlarged array is filled to the half of its new capacity.
When a hashed array tree is full, its directory and leaves must be restructured to twice their prior size to accommodate additional append operations. The data held in old structure is then moved into the new locations. Only one new leaf is then allocated and added into the top array which thus becomes filled only to a quarter of its new capacity. All the extra leaves are not allocated yet, and will only be allocated when needed, thus wasting only O(√n) of storage.[2]
There are multiple alternatives for reducing size: when a hashed array tree is one eighth full, it can be restructured to a smaller, half-full hashed array tree; another option is only freeing unused leaf arrays, without resizing the leaves. Further optimizations include adding new leaves without resizing while growing the directory array as needed, possibly through geometric expansion. This will eliminate the need for data copying completely at the cost of making the wasted space be O(n), with a small constant, and only performing restructuring when a set threshold overhead is reached.[1]
Related data structures
| Peek (index) |
Mutate (insert or delete) at … | Excess space, average | |||
|---|---|---|---|---|---|
| Beginning | End | Middle | |||
| Linked list | Θ(n) | Θ(1) | Θ(1), known end element; Θ(n), unknown end element |
Peek time + Θ(1)[3][4] |
Θ(n) |
| Array | Θ(1) | — | — | — | 0 |
| Dynamic array | Θ(1) | Θ(n) | Θ(1) amortized | Θ(n) | Θ(n)[5] |
| Balanced tree | Θ(log n) | Θ(log n) | Θ(log n) | Θ(log n) | Θ(n) |
| Random-access list | Θ(log n)[6] | Θ(1) | —[6] | —[6] | Θ(n) |
| Hashed array tree | Θ(1) | Θ(n) | Θ(1) amortized | Θ(n) | Θ(√n) |
Brodnik et al.[7] presented a dynamic array algorithm with a similar space wastage profile to hashed array trees. Brodnik's implementation retains previously allocated leaf arrays, with a more complicated address calculation function as compared to hashed array trees.
See also
References
- Sitarski, Edward (September 1996). "Algorithm Alley -- HATs: Hashed array trees". Dr. Dobb's Journal. Vol. 21, no. 11.
- Katajainen, Jyrki (June 5–8, 2016). "Worst-Case-Efficient Dynamic Arrays in Practice". In Kulikov, Alexander S.; Goldberg, Andrew V. (eds.). Experimental Algorithms. 15th International Symposium on Experimental Algorithms, SEA 2016. Lecture Notes in Computer Science. Vol. 9685. St. Petersburg, Russia: Springer Science+Business Media. p. 173. doi:10.1007/978-3-319-38851-9_12. ISBN 978-3-319-38851-9.
- Day 1 Keynote - Bjarne Stroustrup: C++11 Style at GoingNative 2012 on channel9.msdn.com from minute 45 or foil 44
- Number crunching: Why you should never, ever, EVER use linked-list in your code again at kjellkod.wordpress.com
- Brodnik, Andrej; Carlsson, Svante; Sedgewick, Robert; Munro, JI; Demaine, ED (1999), Resizable Arrays in Optimal Time and Space (Technical Report CS-99-09) (PDF), Department of Computer Science, University of Waterloo
- Chris Okasaki (1995). "Purely Functional Random-Access Lists". Proceedings of the Seventh International Conference on Functional Programming Languages and Computer Architecture: 86–95. doi:10.1145/224164.224187.
- Brodnik, Andrej; Carlsson, Svante; Sedgewick, Robert; Munro, JI; Demaine, ED (1999), "Resizable Arrays in Optimal Time and Space" (PDF), Technical Report CS-99-09, Department of Computer Science, University of Waterloo