Retrieval Data Structure
In computer science, a retrieval data structure, also known as static function, is a space-efficient dictionary-like data type composed of a collection of (key, value) pairs that allows the following operations:[1]
- Construction from a collection of (key, value) pairs
- Retrieve the value associated with the given key or anything if the key is not contained in the collection
- Update the value associated with a key (optional)
They can also be thought of as a function for a universe and the set of keys where retrieve has to return for any value and an arbitrary value from otherwise.






In contrast to static functions, AMQ-filters support (probabilistic) membership queries and dictionaries additionally allow operations like listing keys or looking up the value associated with a key and returning some other symbol if the key is not contained.
As can be derived from the operations, this data structure does not need to store the keys at all and may actually use less space than would be needed for a simple list of the key value pairs. This makes it attractive in situations where the associated data is small (e.g. a few bits) compared to the keys because we can save a lot by reducing the space used by keys.
To give a simple example suppose video game names annotated with a boolean indicating whether the game contains a dog that can be petted are given. A static function built from this database can reproduce the associated flag for all names contained in the original set and an arbitrary one for other names. The size of this static function can be made to be only bits for a small which is obviously much less than any pair based representation.[1]



Examples
A trivial example of a static function is a sorted list of the keys and values which implements all the above operations and many more. However, the retrieve on a list is slow and we implement many unneeded operations that can be removed to allow optimizations. Furthermore, we are even allowed to return junk if the queried key is not contained which we did not use at all.
Perfect hash functions
Another simple example to build a static function is using a perfect hash function: After building the PHF for our keys, store the corresponding values at the correct position for the key. As can be seen, this approach also allows updating the associated values, the keys have to be static. The correctness follows from the correctness of the perfect hash function. Using a minimum perfect hash function gives a big space improvement if the associated values are relatively small.
XOR-retrieval
Hashed filters can be categorized by their queries into OR, AND and XOR-filters. For example, the bloom filter is an AND-filter since it returns true for a membership query if all probed locations match. XOR filters work only for static retrievals and are the most promising for building them space efficiently.[2] They are built by solving a linear system which ensures that a query for every key returns true.
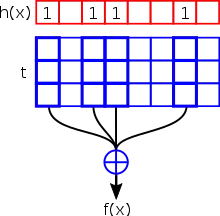
Construction
Given a hash function that maps each key to a bitvector of length where all are linearly independent the following system of linear equations has a solution :





Therefore, the static function is given by and and the space usage is dominated by which is roughly bits per key for , the hash function is assumed to be small.


A retrieval for can be expressed as the bitwise XOR of the rows for all set bits of . Furthermore, fast queries require sparse , thus the problems that need to be solved for this method are finding a suitable hash function and still being able to solve the system of linear equations efficiently.




Ribbon retrieval
Using a sparse random matrix makes retrievals cache inefficient because they access most of in a random non local pattern. Ribbon retrieval improves on this by giving each a consecutive "ribbon" of width in which bits are set at random.[2]

Using the properties of the matrix can be computed in expected time: Ribbon solving works by first sorting the rows by their starting position (e.g. counting sort). Then, a REM form can be constructed iteratively by performing row operations on rows strictly below the current row, eliminating all 1-entries in all columns below the first 1-entry of this row. Row operations do not produce any values outside of the ribbon and are very cheap since they only require an XOR of bits which can be done in time on a RAM. It can be shown that the expected amount of row operations is . Finally, the solution is obtained by backsubstitution.[3]




Applications

Approximate membership
To build an approximate membership data structure use a fingerprinting function . Then build a static function on restricted to the domain of our keys .




Checking the membership of an element is done by evaluating with and returning true if the returned value equals .

- If , returns the correct value and we return true.
- Otherwise, returns a random value and we might give a wrong answer. The length of the hash allows controlling the false positive rate.


The performance of this data structure is exactly the performance of the underlying static function.[4]
Perfect hash functions
A retrieval data structure can be used to construct a perfect hash function: First insert the keys into a cuckoo hash table with hash functions and buckets of size 1. Then, for every key store the index of the hash function that lead to a key's insertion into the hash table in a -bit retrieval data structure . The perfect hash function is given by .[5]




References
- Stefan, Walzer (2020). Random hypergraphs for hashing-based data structures (PhD). pp. 27–30.
- Dillinger, Peter C.; Walzer, Stefan (2021). "Ribbon filter: practically smaller than Bloom and Xor". arXiv:2103.02515 [cs.DS].
- Dietzfelbinger, Martin; Walzer, Stefan (2019). "Efficient Gauss elimination for near-quadratic matrices with one short random block per row, with applications". In Bender, Michael A.; Svensson, Ola; Herman, Grzegorz (eds.). 27th Annual European Symposium on Algorithms, ESA 2019, September 9–11, 2019, Munich/Garching, Germany. LIPIcs. Vol. 144. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. pp. 39:1–39:18. arXiv:1907.04750. doi:10.4230/LIPIcs.ESA.2019.39.
- Dietzfelbinger, Martin; Pagh, Rasmus (2008). "Succinct data structures for retrieval and approximate membership (extended abstract)". In Aceto, Luca; Damgård, Ivan; Goldberg, Leslie Ann; Halldórsson, Magnús M.; Ingólfsdóttir, Anna; Walukiewicz, Igor (eds.). Automata, Languages and Programming, 35th International Colloquium, ICALP 2008, Reykjavik, Iceland, July 7–11, 2008, Proceedings, Part I: Track A: Algorithms, Automata, Complexity, and Games. Lecture Notes in Computer Science. Vol. 5125. Springer. pp. 385–396. arXiv:0803.3693. doi:10.1007/978-3-540-70575-8_32.
- Walzer, Stefan (2021). "Peeling close to the orientability threshold – spatial coupling in hashing-based data structures". In Marx, Dániel (ed.). Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA 2021, Virtual Conference, January 10–13, 2021. Society for Industrial and Applied Mathematics. pp. 2194–2211. arXiv:2001.10500. doi:10.1137/1.9781611976465.131.