Data synchronization
Data synchronization is the process of establishing consistency between source and target data stores, and the continuous harmonization of the data over time. It is fundamental to a wide variety of applications, including file synchronization and mobile device synchronization. Data synchronization can also be useful in encryption for synchronizing public key servers.
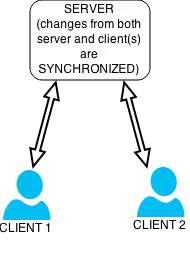
Data synchronization is needed to update and keep multiple copies of a set of data coherent with one another or to maintain data integrity, Figure 3.[1] For example, database replication is used to keep multiple copies of data synchronized with database servers that store data in different locations.
Examples
Examples include:
- File synchronization, such as syncing a hand-held MP3 player to a desktop computer;
- Cluster file systems, which are file systems that maintain data or indexes in a coherent fashion across a whole computing cluster;
- Cache coherency, maintaining multiple copies of data in sync across multiple caches;
- RAID, where data is written in a redundant fashion across multiple disks, so that the loss of any one disk does not lead to a loss of data;
- Database replication, where copies of data on a database are kept in sync, despite possible large geographical separation;
- Journaling, a technique used by many modern file systems to make sure that file metadata are updated on a disk in a coherent, consistent manner.
Challenges
Some of the challenges which user may face in data synchronization:
- data formats complexity;
- real-timeliness;
- data security;
- data quality;
- performance.
Data formats complexity
Data formats tend to grow more complex with time as the organization grows and evolves. This results not only in building simple interfaces between the two applications (source and target), but also in a need to transform the data while passing them to the target application. ETL (extraction transformation loading) tools can be helpful at this stage for managing data format complexities.
Real-timeliness
In real-time systems, customers want to see the current status of their order in e-shop, the current status of a parcel delivery—a real time parcel tracking—, the current balance on their account, etc. This shows the need of a real-time system, which is being updated as well to enable smooth manufacturing process in real-time, e.g., ordering material when enterprise is running out stock, synchronizing customer orders with manufacturing process, etc. From real life, there exist so many examples where real-time processing gives successful and competitive advantage.
Data security
There are no fixed rules and policies to enforce data security. It may vary depending on the system which you are using. Even though the security is maintained correctly in the source system which captures the data, the security and information access privileges must be enforced on the target systems as well to prevent any potential misuse of the information. This is a serious issue and particularly when it comes for handling secret, confidential and personal information. So because of the sensitivity and confidentiality, data transfer and all in-between information must be encrypted.
Data quality
Data quality is another serious constraint. For better management and to maintain good quality of data, the common practice is to store the data at one location and share with different people and different systems and/or applications from different locations. It helps in preventing inconsistencies in the data.
Performance
There are five different phases involved in the data synchronization process:
- data extraction from the source (or master, or main) system;
- data transfer;
- data transformation;
- data load to the target system.
- data updation
Each of these steps is critical. In case of large amounts of data, the synchronization process needs to be carefully planned and executed to avoid any negative impact on performance.
File-based solutions
There are tools available for file synchronization, version control (CVS, Subversion, etc.), distributed filesystems (Coda, etc.), and mirroring (rsync, etc.), in that all these attempt to keep sets of files synchronized. However, only version control and file synchronization tools can deal with modifications to more than one copy of the files.
- File synchronization is commonly used for home backups on external hard drives or updating for transport on USB flash drives. The automatic process prevents copying already identical files, thus can save considerable time relative to a manual copy, also being faster and less error prone.[2]
- Version control tools are intended to deal with situations where more than one user attempts to simultaneously modify the same file, while file synchronizers are optimized for situations where only one copy of the file will be edited at a time. For this reason, although version control tools can be used for file synchronization, dedicated programs require less overhead.
- Distributed filesystems may also be seen as ensuring multiple versions of a file are synchronized. This normally requires that the devices storing the files are always connected, but some distributed file systems like Coda allow disconnected operation followed by reconciliation. The merging facilities of a distributed file system are typically more limited than those of a version control system because most file systems do not keep a version graph.
- Mirror (computing): A mirror is an exact copy of a data set. On the Internet, a mirror site is an exact copy of another Internet site. Mirror sites are most commonly used to provide multiple sources of the same information, and are of particular value as a way of providing reliable access to large downloads.
Theoretical models
Several theoretical models of data synchronization exist in the research literature, and the problem is also related to the problem of Slepian–Wolf coding in information theory. The models are classified based on how they consider the data to be synchronized.
Unordered data
The problem of synchronizing unordered data (also known as the set reconciliation problem) is modeled as an attempt to compute the symmetric difference between two remote sets and of b-bit numbers.[3] Some solutions to this problem are typified by:



- Wholesale transfer
- In this case all data is transferred to one host for a local comparison.
- Timestamp synchronization
- In this case all changes to the data are marked with timestamps. Synchronization proceeds by transferring all data with a timestamp later than the previous synchronization.[4]
- Mathematical synchronization
- In this case data are treated as mathematical objects and synchronization corresponds to a mathematical process.[3][5][6]
Ordered data
In this case, two remote strings and need to be reconciled. Typically, it is assumed that these strings differ by up to a fixed number of edits (i.e. character insertions, deletions, or modifications). Then data synchronization is the process of reducing edit distance between and , up to the ideal distance of zero. This is applied in all filesystem based synchronizations (where the data is ordered). Many practical applications of this are discussed or referenced above.


It is sometimes possible to transform the problem to one of unordered data through a process known as shingling (splitting the strings into shingles).[7]
Error handling
In fault-tolerant systems, distributed databases must be able to cope with the loss or corruption of (part of) their data. The first step is usually replication, which involves making multiple copies of the data and keeping them all up to date as changes are made. However, it is then necessary to decide which copy to rely on when loss or corruption of an instance occurs.
The simplest approach is to have a single master instance that is the sole source of truth. Changes to it are replicated to other instances, and one of those instances becomes the new master when the old master fails.
Paxos and Raft are more complex protocols that exist to solve problems with transient effects during failover, such as two instances thinking they are the master at the same time.
Secret sharing is useful if failures of whole nodes are very common. This moves synchronization from an explicit recovery process to being part of each read, where a read of some data requires retrieving encoded data from several different nodes. If corrupt or out-of-date data may be present on some nodes, this approach may also benefit from the use of an error correction code.
DHTs and Blockchains try to solve the problem of synchronization between many nodes (hundreds to billions).
See also
- SyncML, a standard mainly for calendar, contact and email synchronization
- Synchronization (computer science)
References
- Nakatani, Kazuo; Chuang, Ta-Tao; Zhou, Duanning (2006). "Data Synchronization Technology: Standards, Business Values and Implications". Communications of the Association for Information Systems. 17. doi:10.17705/1cais.01744. ISSN 1529-3181.
- A. Tridgell (February 1999). "Efficient algorithms for sorting and synchronization" (PDF). PhD thesis. The Australian National University.
- Minsky, Y.; Ari Trachtenberg; Zippel, R. (2003). "Set reconciliation with nearly optimal communication complexity". IEEE Transactions on Information Theory. 49 (9): 2213–2218. CiteSeerX 10.1.1.73.5806. doi:10.1109/TIT.2003.815784.
- "Palm developer knowledgebase manuals". Archived from the original on 2002-03-11. Retrieved 2007-01-09.
- Ari Trachtenberg; D. Starobinski; S. Agarwal. "Fast PDA Synchronization Using Characteristic Polynomial Interpolation" (PDF). IEEE INFOCOM 2002. doi:10.1109/INFCOM.2002.1019402.
- Y. Minsky and A. Trachtenberg, Scalable set reconciliation, Allerton Conference on Communication, Control, and Computing, Oct. 2002
- S. Agarwal; V. Chauhan; Ari Trachtenberg (November 2006). "Bandwidth efficient string reconciliation using puzzles" (PDF). IEEE Transactions on Parallel and Distributed Systems. 17 (11): 1217–1225. doi:10.1109/TPDS.2006.148. S2CID 4300693. Retrieved 2007-05-23.