Distributed hash table
A distributed hash table (DHT) is a distributed system that provides a lookup service similar to a hash table. Key–value pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key. The main advantage of a DHT is that nodes can be added or removed with minimum work around re-distributing keys. Keys are unique identifiers which map to particular values, which in turn can be anything from addresses, to documents, to arbitrary data.[1] Responsibility for maintaining the mapping from keys to values is distributed among the nodes, in such a way that a change in the set of participants causes a minimal amount of disruption. This allows a DHT to scale to extremely large numbers of nodes and to handle continual node arrivals, departures, and failures.
DHTs form an infrastructure that can be used to build more complex services, such as anycast, cooperative web caching, distributed file systems, domain name services, instant messaging, multicast, and also peer-to-peer file sharing and content distribution systems. Notable distributed networks that use DHTs include BitTorrent's distributed tracker, the Kad network, the Storm botnet, the Tox instant messenger, Freenet, the YaCy search engine, and the InterPlanetary File System.
History
DHT research was originally motivated, in part, by peer-to-peer (P2P) systems such as Freenet, Gnutella, BitTorrent and Napster, which took advantage of resources distributed across the Internet to provide a single useful application. In particular, they took advantage of increased bandwidth and hard disk capacity to provide a file-sharing service.[2]
These systems differed in how they located the data offered by their peers. Napster, the first large-scale P2P content delivery system, required a central index server: each node, upon joining, would send a list of locally held files to the server, which would perform searches and refer the queries to the nodes that held the results. This central component left the system vulnerable to attacks and lawsuits.
Gnutella and similar networks moved to a query flooding model – in essence, each search would result in a message being broadcast to every other machine in the network. While avoiding a single point of failure, this method was significantly less efficient than Napster. Later versions of Gnutella clients moved to a dynamic querying model which vastly improved efficiency.[3]
Freenet is fully distributed, but employs a heuristic key-based routing in which each file is associated with a key, and files with similar keys tend to cluster on a similar set of nodes. Queries are likely to be routed through the network to such a cluster without needing to visit many peers.[4] However, Freenet does not guarantee that data will be found.
Distributed hash tables use a more structured key-based routing in order to attain both the decentralization of Freenet and Gnutella, and the efficiency and guaranteed results of Napster. One drawback is that, like Freenet, DHTs only directly support exact-match search, rather than keyword search, although Freenet's routing algorithm can be generalized to any key type where a closeness operation can be defined.[5]
In 2001, four systems—CAN,[6] Chord,[7] Pastry, and Tapestry—ignited DHTs as a popular research topic. A project called the Infrastructure for Resilient Internet Systems (Iris) was funded by a $12 million grant from the United States National Science Foundation in 2002.[8] Researchers included Sylvia Ratnasamy, Ion Stoica, Hari Balakrishnan and Scott Shenker.[9] Outside academia, DHT technology has been adopted as a component of BitTorrent and in the Coral Content Distribution Network.
Properties
DHTs characteristically emphasize the following properties:
- Autonomy and decentralization: The nodes collectively form the system without any central coordination.
- Fault tolerance: The system should be reliable (in some sense) even with nodes continuously joining, leaving, and failing.[10]
- Scalability: The system should function efficiently even with thousands or millions of nodes.
A key technique used to achieve these goals is that any one node needs to coordinate with only a few other nodes in the system – most commonly, O(log n) of the n participants (see below) – so that only a limited amount of work needs to be done for each change in membership.
Some DHT designs seek to be secure against malicious participants[11] and to allow participants to remain anonymous, though this is less common than in many other peer-to-peer (especially file sharing) systems; see anonymous P2P.
Structure
The structure of a DHT can be decomposed into several main components.[12][13] The foundation is an abstract keyspace, such as the set of 160-bit strings. A keyspace partitioning scheme splits ownership of this keyspace among the participating nodes. An overlay network then connects the nodes, allowing them to find the owner of any given key in the keyspace.
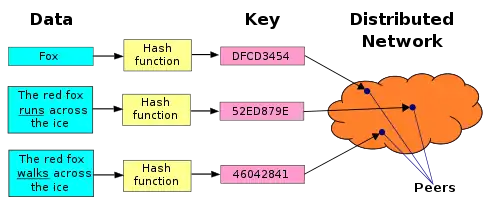
Once these components are in place, a typical use of the DHT for storage and retrieval might proceed as follows. Suppose the keyspace is the set of 160-bit strings. To index a file with given filename and data in the DHT, the SHA-1 hash of filename is generated, producing a 160-bit key k, and a message put(k, data) is sent to any node participating in the DHT. The message is forwarded from node to node through the overlay network until it reaches the single node responsible for key k as specified by the keyspace partitioning. That node then stores the key and the data. Any other client can then retrieve the contents of the file by again hashing filename to produce k and asking any DHT node to find the data associated with k with a message get(k). The message will again be routed through the overlay to the node responsible for k, which will reply with the stored data.
The keyspace partitioning and overlay network components are described below with the goal of capturing the principal ideas common to most DHTs; many designs differ in the details.
Keyspace partitioning
Most DHTs use some variant of consistent hashing or rendezvous hashing to map keys to nodes. The two algorithms appear to have been devised independently and simultaneously to solve the distributed hash table problem.
Both consistent hashing and rendezvous hashing have the essential property that removal or addition of one node changes only the set of keys owned by the nodes with adjacent IDs, and leaves all other nodes unaffected. Contrast this with a traditional hash table in which addition or removal of one bucket causes nearly the entire keyspace to be remapped. Since any change in ownership typically corresponds to bandwidth-intensive movement of objects stored in the DHT from one node to another, minimizing such reorganization is required to efficiently support high rates of churn (node arrival and failure).
Consistent hashing
Consistent hashing employs a function that defines an abstract notion of the distance between the keys and , which is unrelated to geographical distance or network latency. Each node is assigned a single key called its identifier (ID). A node with ID owns all the keys for which is the closest ID, measured according to .






For example, the Chord DHT uses consistent hashing, which treats nodes as points on a circle, and is the distance traveling clockwise around the circle from to . Thus, the circular keyspace is split into contiguous segments whose endpoints are the node identifiers. If and are two adjacent IDs, with a shorter clockwise distance from to , then the node with ID owns all the keys that fall between and .


Rendezvous hashing
In rendezvous hashing, also called highest random weight (HRW) hashing, all clients use the same hash function (chosen ahead of time) to associate a key to one of the n available servers. Each client has the same list of identifiers {S1, S2, ..., Sn }, one for each server. Given some key k, a client computes n hash weights w1 = h(S1, k), w2 = h(S2, k), ..., wn = h(Sn, k). The client associates that key with the server corresponding to the highest hash weight for that key. A server with ID owns all the keys for which the hash weight is higher than the hash weight of any other node for that key.



Locality-preserving hashing
Locality-preserving hashing ensures that similar keys are assigned to similar objects. This can enable a more efficient execution of range queries, however, in contrast to using consistent hashing, there is no more assurance that the keys (and thus the load) is uniformly randomly distributed over the key space and the participating peers. DHT protocols such as Self-Chord and Oscar[14] address such issues. Self-Chord decouples object keys from peer IDs and sorts keys along the ring with a statistical approach based on the swarm intelligence paradigm.[15] Sorting ensures that similar keys are stored by neighbour nodes and that discovery procedures, including range queries, can be performed in logarithmic time. Oscar constructs a navigable small-world network based on random walk sampling also assuring logarithmic search time.
Overlay network
Each node maintains a set of links to other nodes (its neighbors or routing table). Together, these links form the overlay network.[16] A node picks its neighbors according to a certain structure, called the network's topology.
All DHT topologies share some variant of the most essential property: for any key k, each node either has a node ID that owns k or has a link to a node whose node ID is closer to k, in terms of the keyspace distance defined above. It is then easy to route a message to the owner of any key k using the following greedy algorithm (that is not necessarily globally optimal): at each step, forward the message to the neighbor whose ID is closest to k. When there is no such neighbor, then we must have arrived at the closest node, which is the owner of k as defined above. This style of routing is sometimes called key-based routing.
Beyond basic routing correctness, two important constraints on the topology are to guarantee that the maximum number of hops in any route (route length) is low, so that requests complete quickly; and that the maximum number of neighbors of any node (maximum node degree) is low, so that maintenance overhead is not excessive. Of course, having shorter routes requires higher maximum degree. Some common choices for maximum degree and route length are as follows, where n is the number of nodes in the DHT, using Big O notation:
| Max. degree | Max route length | Used in | Note |
|---|---|---|---|
| Worst lookup lengths, with likely much slower lookups times | |||
| Koorde (with constant degree) | More complex to implement, but acceptable lookup time can be found with a fixed number of connections | ||
| Chord Kademlia Pastry Tapestry | Most common, but not optimal (degree/route length). Chord is the most basic version, with Kademlia seeming the most popular optimized variant (should have improved average lookup) | ||
| Koorde (with optimal lookup) | More complex to implement, but lookups might be faster (have a lower worst case bound) | ||
| Worst local storage needs, with much communication after any node connects or disconnects |





The most common choice, degree/route length, is not optimal in terms of degree/route length tradeoff, but such topologies typically allow more flexibility in choice of neighbors. Many DHTs use that flexibility to pick neighbors that are close in terms of latency in the physical underlying network. In general, all DHTs construct navigable small-world network topologies, which trade-off route length vs. network degree.[17]
Maximum route length is closely related to diameter: the maximum number of hops in any shortest path between nodes. Clearly, the network's worst case route length is at least as large as its diameter, so DHTs are limited by the degree/diameter tradeoff[18] that is fundamental in graph theory. Route length can be greater than diameter, since the greedy routing algorithm may not find shortest paths.[19]
Algorithms for overlay networks
Aside from routing, there exist many algorithms that exploit the structure of the overlay network for sending a message to all nodes, or a subset of nodes, in a DHT.[20] These algorithms are used by applications to do overlay multicast, range queries, or to collect statistics. Two systems that are based on this approach are Structella,[21] which implements flooding and random walks on a Pastry overlay, and DQ-DHT, which implements a dynamic querying search algorithm over a Chord network.[22]
Security
Because of the decentralization, fault tolerance, and scalability of DHTs, they are inherently more resilient against a hostile attacker than a centralized system.
Open systems for distributed data storage that are robust against massive hostile attackers are feasible.[23]
A DHT system that is carefully designed to have Byzantine fault tolerance can defend against a security weakness, known as the Sybil attack, which affects most current DHT designs.[24][25] Whanau is a DHT designed to be resistant to Sybil attacks.[26]
Petar Maymounkov, one of the original authors of Kademlia, has proposed a way to circumvent the weakness to the Sybil attack by incorporating social trust relationships into the system design.[27] The new system, codenamed Tonika or also known by its domain name as 5ttt, is based on an algorithm design known as "electric routing" and co-authored with the mathematician Jonathan Kelner.[28] Maymounkov has now undertaken a comprehensive implementation effort of this new system. However, research into effective defences against Sybil attacks is generally considered an open question, and wide variety of potential defences are proposed every year in top security research conferences.
Implementations
Most notable differences encountered in practical instances of DHT implementations include at least the following:
- The address space is a parameter of DHT. Several real-world DHTs use 128-bit or 160-bit key space.
- Some real-world DHTs use hash functions other than SHA-1.
- In the real world the key k could be a hash of a file's content rather than a hash of a file's name to provide content-addressable storage, so that renaming of the file does not prevent users from finding it.
- Some DHTs may also publish objects of different types. For example, key k could be the node ID and associated data could describe how to contact this node. This allows publication-of-presence information and often used in IM applications, etc. In the simplest case, ID is just a random number that is directly used as key k (so in a 160-bit DHT ID will be a 160-bit number, usually randomly chosen). In some DHTs, publishing of nodes' IDs is also used to optimize DHT operations.
- Redundancy can be added to improve reliability. The (k, data) key pair can be stored in more than one node corresponding to the key. Usually, rather than selecting just one node, real world DHT algorithms select i suitable nodes, with i being an implementation-specific parameter of the DHT. In some DHT designs, nodes agree to handle a certain keyspace range, the size of which may be chosen dynamically, rather than hard-coded.
- Some advanced DHTs like Kademlia perform iterative lookups through the DHT first in order to select a set of suitable nodes and send put(k, data) messages only to those nodes, thus drastically reducing useless traffic, since published messages are only sent to nodes that seem suitable for storing the key k; and iterative lookups cover just a small set of nodes rather than the entire DHT, reducing useless forwarding. In such DHTs, forwarding of put(k, data) messages may only occur as part of a self-healing algorithm: if a target node receives a put(k, data) message, but believes that k is out of its handled range and a closer node (in terms of DHT keyspace) is known, the message is forwarded to that node. Otherwise, data are indexed locally. This leads to a somewhat self-balancing DHT behavior. Of course, such an algorithm requires nodes to publish their presence data in the DHT so the iterative lookups can be performed.
- Since on most machines sending messages is much more expensive than local hash table accesses, it makes sense to bundle many messages concerning a particular node into a single batch. Assuming each node has a local batch consisting of at most b operations, the bundling procedure is as follows. Each node first sorts its local batch by the identifier of the node responsible for the operation. Using bucket sort, this can be done in O(b + n), where n is the number of nodes in the DHT. When there are multiple operations addressing the same key within one batch, the batch is condensed before being sent out. For example, multiple lookups of the same key can be reduced to one or multiple increments can be reduced to a single add operation. This reduction can be implemented with the help of a temporary local hash table. Finally, the operations are sent to the respective nodes.[29]
Examples
DHT protocols and implementations
- Apache Cassandra
- BATON Overlay
- Mainline DHT – standard DHT used by BitTorrent (based on Kademlia as provided by Khashmir)[30]
- Content addressable network (CAN)
- Chord
- Koorde
- Kademlia
- Pastry
- P-Grid
- Riak
- Tapestry
- TomP2P
- Voldemort
Applications using DHTs
- BTDigg: BitTorrent DHT search engine
- Codeen: web caching
- Freenet: a censorship-resistant anonymous network
- GlusterFS: a distributed file system used for storage virtualization
- GNUnet: Freenet-like distribution network including a DHT implementation
- I2P: An open-source anonymous peer-to-peer network
- I2P-Bote: serverless secure anonymous email
- IPFS: A content-addressable, peer-to-peer hypermedia distribution protocol
- JXTA: open-source P2P platform
- LBRY: A blockchain-based content sharing protocol which uses a Kademlia-influenced DHT system for content distribution
- Oracle Coherence: an in-memory data grid built on top of a Java DHT implementation
- Perfect Dark: a peer-to-peer file-sharing application from Japan
- Retroshare: a Friend-to-friend network[31]
- Jami: a privacy-preserving voice, video and chat communication platform, based on a Kademlia-like DHT
- Tox: an instant messaging system intended to function as a Skype replacement
- Twister: a microblogging peer-to-peer platform
- YaCy: a distributed search engine
See also
- Couchbase Server: a persistent, replicated, clustered distributed object storage system compatible with memcached protocol.
- Memcached: a high-performance, distributed memory object caching system.
- Prefix hash tree: sophisticated querying over DHTs.
- Merkle tree: tree having every non-leaf node labelled with the hash of the labels of its children nodes.
- Most distributed data stores employ some form of DHT for lookup.
- Skip graphs are an efficient data structure for implementing DHTs.
References
- Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M. F.; Balakrishnan, H. (2001). "Chord: A scalable peer-to-peer lookup service for internet applications" (PDF). ACM SIGCOMM Computer Communication Review. 31 (4): 149. doi:10.1145/964723.383071.
A value can be an address, a document, or an arbitrary data item.
- Liz, Crowcroft; et al. (2005). "A survey and comparison of peer-to-peer overlay network schemes" (PDF). IEEE Communications Surveys & Tutorials. 7 (2): 72–93. CiteSeerX 10.1.1.109.6124. doi:10.1109/COMST.2005.1610546. S2CID 7971188.
- Richter, Stevenson; et al. (2009). "Analysis of the impact of dynamic querying models on client-server relationships". Trends in Modern Computing: 682–701.
- Searching in a Small World Chapters 1 & 2 (PDF), retrieved 2012-01-10
- "Section 5.2.2" (PDF), A Distributed Decentralized Information Storage and Retrieval System, retrieved 2012-01-10
- Ratnasamy; et al. (2001). "A Scalable Content-Addressable Network" (PDF). In Proceedings of ACM SIGCOMM 2001. Retrieved 2013-05-20.
{{cite journal}}: Cite journal requires|journal=(help) - Hari Balakrishnan, M. Frans Kaashoek, David Karger, Robert Morris, and Ion Stoica. Looking up data in P2P systems. In Communications of the ACM, February 2003.
- David Cohen (October 1, 2002). "New P2P network funded by US government". New Scientist. Retrieved November 10, 2013.
- "MIT, Berkeley, ICSI, NYU, and Rice Launch the IRIS Project". Press release. MIT. September 25, 2002. Archived from the original on September 26, 2015. Retrieved November 10, 2013.
- R Mokadem, A Hameurlain and AM Tjoa. Resource discovery service while minimizing maintenance overhead in hierarchical DHT systems. Proc. iiWas, 2010
- Guido Urdaneta, Guillaume Pierre and Maarten van Steen. A Survey of DHT Security Techniques. ACM Computing Surveys 43(2), January 2011.
- Moni Naor and Udi Wieder. Novel Architectures for P2P Applications: the Continuous-Discrete Approach. Proc. SPAA, 2003.
- Gurmeet Singh Manku. Dipsea: A Modular Distributed Hash Table Archived 2004-09-10 at the Wayback Machine. Ph. D. Thesis (Stanford University), August 2004.
- Girdzijauskas, Šarūnas; Datta, Anwitaman; Aberer, Karl (2010-02-01). "Structured overlay for heterogeneous environments". ACM Transactions on Autonomous and Adaptive Systems. 5 (1): 1–25. doi:10.1145/1671948.1671950. ISSN 1556-4665. S2CID 13218263.
- Forestiero, Agostino; Leonardi, Emilio; Mastroianni, Carlo; Meo, Michela (October 2010). "Self-Chord: A Bio-Inspired P2P Framework for Self-Organizing Distributed Systems". IEEE/ACM Transactions on Networking. 18 (5): 1651–1664. doi:10.1109/TNET.2010.2046745. S2CID 14797120.
- Galuba, Wojciech; Girdzijauskas, Sarunas (2009), "Peer to Peer Overlay Networks: Structure, Routing and Maintenance", in LIU, LING; ÖZSU, M. TAMER (eds.), Encyclopedia of Database Systems, Springer US, pp. 2056–2061, doi:10.1007/978-0-387-39940-9_1215, ISBN 9780387399409
- Girdzijauskas, Sarunas (2009). Designing peer-to-peer overlays a small-world perspective.
{{cite book}}:|website=ignored (help) - The (Degree,Diameter) Problem for Graphs, Maite71.upc.es, archived from the original on 2012-02-17, retrieved 2012-01-10
- Gurmeet Singh Manku, Moni Naor, and Udi Wieder. "Know thy Neighbor's Neighbor: the Power of Lookahead in Randomized P2P Networks". Proc. STOC, 2004.
- Ali Ghodsi (22 May 2007). "Distributed k-ary System: Algorithms for Distributed Hash Tables". Archived from the original on 22 May 2007.. KTH-Royal Institute of Technology, 2006.
- Castro, Miguel; Costa, Manuel; Rowstron, Antony (1 January 2004). "Should we build Gnutella on a structured overlay?" (PDF). ACM SIGCOMM Computer Communication Review. 34 (1): 131. CiteSeerX 10.1.1.221.7892. doi:10.1145/972374.972397. S2CID 6587291.
- Talia, Domenico; Trunfio, Paolo (December 2010). "Enabling Dynamic Querying over Distributed Hash Tables". Journal of Parallel and Distributed Computing. 70 (12): 1254–1265. doi:10.1016/j.jpdc.2010.08.012.
- Baruch Awerbuch, Christian Scheideler. "Towards a scalable and robust DHT". 2006. doi:10.1145/1148109.1148163
- Maxwell Young; Aniket Kate; Ian Goldberg; Martin Karsten. "Practical Robust Communication in DHTs Tolerating a Byzantine Adversary".
- Natalya Fedotova; Giordano Orzetti; Luca Veltri; Alessandro Zaccagnini. "Byzantine agreement for reputation management in DHT-based peer-to-peer networks". doi:10.1109/ICTEL.2008.4652638
- Whanau: A Sybil-proof Distributed Hash Table https://pdos.csail.mit.edu/papers/whanau-nsdi10.pdf
- Chris Lesniewski-Laas. "A Sybil-proof one-hop DHT" (PDF): 20.
{{cite journal}}: Cite journal requires|journal=(help) - Jonathan Kelner, Petar Maymounkov (2009). "Electric routing and concurrent flow cutting". arXiv:0909.2859. Bibcode:2009arXiv0909.2859K.
{{cite journal}}: Cite journal requires|journal=(help) - Sanders, Peter; Mehlhorn, Kurt; Dietzfelbinger, Martin; Dementiev, Roman (2019). Sequential and Parallel Algorithms and Data Structures: The Basic Toolbox. Springer International Publishing. ISBN 978-3-030-25208-3.
- Tribler wiki Archived December 4, 2010, at the Wayback Machine retrieved January 2010.
- Retroshare FAQ retrieved December 2011
External links
- Distributed Hash Tables, Part 1 by Brandon Wiley.
- Distributed Hash Tables links Carles Pairot's Page on DHT and P2P research
- kademlia.scs.cs.nyu.edu Archive.org snapshots of kademlia.scs.cs.nyu.edu
- Eng-Keong Lua; Crowcroft, Jon; Pias, Marcelo; Sharma, Ravi; Lim, Steve (2005). "IEEE Survey on overlay network schemes". CiteSeerX 10.1.1.111.4197: covering unstructured and structured decentralized overlay networks including DHTs (Chord, Pastry, Tapestry and others).
- Mainline DHT Measurement at Department of Computer Science, University of Helsinki, Finland.
| Companies | |
|---|---|
| People | |
| Technology | |
| Clients (comparison, usage share) |
|
| Tracker software (comparison) | |
| Search engines (comparison) | |
| Defunct sites (comparison) | |
| Related topics | |
| |