Tesseract (software)
Tesseract is an optical character recognition engine for various operating systems.[5] It is free software, released under the Apache License.[1][6][7] Originally developed by Hewlett-Packard as proprietary software in the 1980s, it was released as open source in 2005 and development has been sponsored by Google since 2006.[8]
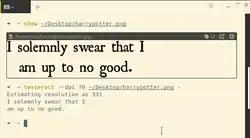 Tesseract 4.1.1 reading an image. | |
| Original author(s) | Ray Smith, Hewlett-Packard[1] |
|---|---|
| Developer(s) | Google and others |
| Stable release | |
| Repository | |
| Written in | C and C++ |
| Operating system | Linux, Windows, and macOS |
| Available in | Interface: English Recognition: Afrikaans, Albanian, Arabic, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Catalan, Czech, Cherokee, Croatian, Danish, Dutch, English, Esperanto, Estonian, Finnish, French, Galician, German, Greek, Hindi, Hebrew, Hungarian, Indonesian, Italian, Japanese, Kannada, Korean, Latvian, Lithuanian, Malayalam, Macedonian, Maltese, Malay, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Telugu, Thai, Turkish, Ukrainian & Vietnamese [3] (more can be added using included training files)[4] |
| Type | Optical character recognition |
| License | Apache License 2.0 |
| Website | github |
In 2006, Tesseract was considered one of the most accurate open-source OCR engines available.[7][9]
History
The Tesseract engine was originally developed as proprietary software at Hewlett-Packard labs in Bristol, England and Greeley, Colorado between 1985 and 1994, with more changes made in 1996 to port to Windows, and some migration from C to C++ in 1998. A lot of the code was written in C, and then some more was written in C++. Since then, all the code has been converted to at least compile with a C++ compiler. Very little work was done in the following decade. It was then released as open source in 2005 by Hewlett-Packard and the University of Nevada, Las Vegas (UNLV). Tesseract development has been sponsored by Google since 2006.[8]
Version 4 adds LSTM-based OCR engine and models for many additional languages and scripts, bringing the total to 116 languages.[10] Additionally 37 scripts are supported. So it is for example possible to recognize text with a mix of Western and Central European languages by using the model for the Latin script it is written in.
Version 5 was released in 2021, after more than two years of testing and developing.[11]
Features
Tesseract was in the top three OCR engines in terms of character accuracy in 1995.[12] It is available for Linux, Windows and Mac OS X.[6][7]
Tesseract up to and including version 2 could only accept TIFF images of simple one-column text as inputs. These early versions did not include layout analysis, and so inputting multi-columned text, images, or equations produced garbled output. Since version 3.00 Tesseract has supported output text formatting, hOCR[13] positional information and page-layout analysis. Support for a number of new image formats was added using the Leptonica library. Tesseract can detect whether text is monospaced or proportionally spaced.[7]
The initial versions of Tesseract could only recognize English-language text. Tesseract v2 added six additional Western languages (French, Italian, German, Spanish, Brazilian Portuguese, Dutch). Version 3 extended language support significantly to include ideographic (Chinese & Japanese) and right-to-left (e.g. Arabic, Hebrew) languages, as well as many more scripts. New languages included Arabic, Bulgarian, Catalan, Chinese (Simplified and Traditional), Croatian, Czech, Danish, German (Fraktur script), Greek, Finnish, Hebrew, Hindi, Hungarian, Indonesian, Japanese, Korean, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak (standard and Fraktur script), Slovenian, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian and Vietnamese. V3.04, released in July 2015, added an additional 39 language/script combinations, bringing the total count of support languages to over 100. New language codes included: amh (Amharic), asm (Assamese), aze_cyrl (Azerbaijana in Cyrillic script), bod (Tibetan), bos (Bosnian), ceb (Cebuano), cym (Welsh), dzo (Dzongkha), fas (Persian), gle (Irish), guj (Gujarati), hat (Haitian and Haitian Creole), iku (Inuktitut), jav (Javanese), kat (Georgian), kat_old (Old Georgian), kaz (Kazakh), khm (Central Khmer), kir (Kyrgyz), kur (Kurdish), lao (Lao), lat (Latin), mar (Marathi), mya (Burmese), nep (Nepali), ori (Oriya), pan (Punjabi), pus (Pashto), san (Sanskrit), sin (Sinhala), srp_latn (Serbian in Latin script), syr (Syriac), tgk (Tajik), tir (Tigrinya), uig (Uyghur), urd (Urdu), uzb (Uzbek), uzb_cyrl (Uzbek in Cyrillic script), yid (Yiddish).[14]
In addition, Tesseract can be trained to work in other languages.[7]
Tesseract can process right-to-left text such as Arabic or Hebrew, many Indic scripts as well as CJK quite well. Accuracy rates are shown in this presentation for Tesseract tutorial at DAS 2016, Santorini by Ray Smith.[15]
Tesseract is suitable for use as a backend and can be used for more complicated OCR tasks including layout analysis by using a frontend such as OCRopus.[16]
Tesseract's output will have very poor quality if the input images are not preprocessed to suit it: Images (especially screenshots) must be scaled up such that the text x-height is at least 20 pixels,[17] any rotation or skew must be corrected or no text will be recognized, low-frequency changes in brightness must be high-pass filtered, or Tesseract's binarization stage will destroy much of the page, and dark borders must be manually removed, or they will be misinterpreted as characters.[18]
User interfaces
Tesseract is executed from the command-line interface.[19] While Tesseract is not supplied with a GUI, there are many separate projects which provide a GUI for it.[20] One common example is OCRFeeder.[21]
Reception
In a July 2007 article on Tesseract, Anthony Kay of Linux Journal termed it "a quirky command-line tool that does an outstanding job". At that time he noted "Tesseract is a bare-bones OCR engine. The build process is a little quirky, and the engine needs some additional features (such as layout detection), but the core feature, text recognition, is drastically better than anything else I've tried from the Open Source community. It is reasonably easy to get excellent recognition rates using nothing more than a scanner and some image tools, such as The GIMP and Netpbm."[5]
In November 2020, Brewster Kahle from the Internet Archive praised Tesseract saying:
Tesseract has made a major step forward in the last few years. When we last evaluated the accuracy it was not as good as the proprietary OCR, but that has changed– we have done evaluations and it is just as good, and can get better for our application because of its new architecture.[22]
See also
References
- Google (2008). "tesseract-ocr". GitHub. Retrieved 8 March 2016.
- Error: Unable to display the reference properly. See the documentation for details.
- "Languages supported in different versions of Tesseract". Archived from the original on 8 August 2022. Retrieved 21 November 2022.
- "Tesseract documentation – Traineddata files ... – Language data files for Tesseract". Archived from the original on 5 September 2022. Retrieved 21 November 2022.
- Kay, Anthony (July 2007). "Tesseract: an Open-Source Optical Character Recognition Engine". Linux Journal. Retrieved 28 September 2011.
- Vincent, Luc (August 2006). "Announcing Tesseract OCR". Archived from the original on 26 October 2006. Retrieved 26 June 2008.
- Canonical Ltd. (February 2011). "OCR". Retrieved 11 February 2011.
- Announcing Tesseract OCR - The official Google blog
- Willis, Nathan (September 2006). "Google's Tesseract OCR engine is a quantum leap forward". Archived from the original on 28 May 2022. Retrieved 18 July 2008.
- "TESSERACT(1) Manual Page". GitHub. Retrieved 15 March 2018.
- Schmidt, Julia (1 December 2021). "OCR Engine Tesseract 5.0 converts to float for faster training and recognition • DEVCLASS". DEVCLASS. Retrieved 20 December 2021.
- Rice Stephen V., Frank R. Jenkins, and Thomas A. Nartker The Fourth Annual Test of OCR Accuracy, expervision.com, retrieved 21 May 2013
- Tesseract Project (February 2011). "Issue 263: patch to enable hOCR output". Archived from the original on 13 November 2012. Retrieved 26 February 2011.
- "langdata - Source training data for Tesseract for lots of languages". GitHub. Retrieved 6 November 2016.
- "Training LSTM networks on 100 languages and test results" (PDF). GitHub. Retrieved 18 March 2018.
- Announcing the OCRopus Open Source OCR System Archived 2007-04-14 at the Wayback Machine (Thomas Breuel, OCRopus Project Leader).
- "FAQ - tesseract-ocr - Frequently Asked Questions - An OCR Engine that was developed at HP Labs between 1985 and 1995... and now at Google. - Google Project Hosting". Archived from the original on 23 December 2015. Retrieved 30 May 2014.
- "ImproveQuality - tesseract-ocr - Advice on improving the quality of your output. - An OCR Engine that was developed at HP Labs between 1985 and 1995... and now at Google. - Google Project Hosting". 27 January 2014. Archived from the original on 20 September 2015. Retrieved 30 May 2014.
- Google Code – Tesseract Readme
- "3rdParty - tesseract-ocr - GUIs and Other Projects using Tesseract OCR". github.com. Retrieved 30 March 2017.
- "OCRFeeder". GNOME wiki. Retrieved 12 January 2019.
- Brewster Kahle (23 November 2020). "FOSS wins again: Free and Open Source Communities comes through on 19th Century Newspapers (and Books and Periodicals...) - Internet Archive Blogs". blog.archive.org. Retrieved 1 December 2020.