Search tree
In computer science, a search tree is a tree data structure used for locating specific keys from within a set. In order for a tree to function as a search tree, the key for each node must be greater than any keys in subtrees on the left, and less than any keys in subtrees on the right.[1]
The advantage of search trees is their efficient search time given the tree is reasonably balanced, which is to say the leaves at either end are of comparable depths. Various search-tree data structures exist, several of which also allow efficient insertion and deletion of elements, which operations then have to maintain tree balance.
Search trees are often used to implement an associative array. The search tree algorithm uses the key from the key–value pair to find a location, and then the application stores the entire key–value pair at that particular location.
Types of Trees
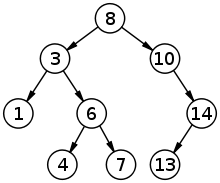
Binary search tree
A Binary Search Tree is a node-based data structure where each node contains a key and two subtrees, the left and right. For all nodes, the left subtree's key must be less than the node's key, and the right subtree's key must be greater than the node's key. These subtrees must all qualify as binary search trees.
The worst-case time complexity for searching a binary search tree is the height of the tree, which can be as small as O(log n) for a tree with n elements.
B-tree
B-trees are generalizations of binary search trees in that they can have a variable number of subtrees at each node. While child-nodes have a pre-defined range, they will not necessarily be filled with data, meaning B-trees can potentially waste some space. The advantage is that B-trees do not need to be re-balanced as frequently as other self-balancing trees.
Due to the variable range of their node length, B-trees are optimized for systems that read large blocks of data, they are also commonly used in databases.
The time complexity for searching a B-tree is O(log n).
(a,b)-tree
An (a,b)-tree is a search tree where all of its leaves are the same depth. Each node has at least a children and at most b children, while the root has at least 2 children and at most b children.
a and b can be decided with the following formula:[2]

The time complexity for searching an (a,b)-tree is O(log n).
Ternary search tree
A ternary search tree is a type of tree that can have 3 nodes: a low child, an equal child, and a high child. Each node stores a single character and the tree itself is ordered the same way a binary search tree is, with the exception of a possible third node.
Searching a ternary search tree involves passing in a string to test whether any path contains it.
The time complexity for searching a balanced ternary search tree is O(log n).
Searching algorithms
Searching for a specific key
Assuming the tree is ordered, we can take a key and attempt to locate it within the tree. The following algorithms are generalized for binary search trees, but the same idea can be applied to trees of other formats.
Recursive
search-recursive(key, node)
if node is NULL
return EMPTY_TREE
if key < node.key
return search-recursive(key, node.left)
else if key > node.key
return search-recursive(key, node.right)
else
return node
Iterative
searchIterative(key, node)
currentNode := node
while currentNode is not NULL
if currentNode.key = key
return currentNode
else if currentNode.key > key
currentNode := currentNode.left
else
currentNode := currentNode.right
Searching for min and max
In a sorted tree, the minimum is located at the node farthest left, while the maximum is located at the node farthest right.[3]
Minimum
findMinimum(node)
if node is NULL
return EMPTY_TREE
min := node
while min.left is not NULL
min := min.left
return min.key
Maximum
findMaximum(node)
if node is NULL
return EMPTY_TREE
max := node
while max.right is not NULL
max := max.right
return max.key
See also
References
- Black, Paul and Pieterse, Vreda (2005). "search tree". Dictionary of Algorithms and Data Structures
- Toal, Ray. "(a,b) Trees"
- Gildea, Dan (2004). "Binary Search Tree"