Proteogenomics
Proteogenomics is a field of biological research that utilizes a combination of proteomics, genomics, and transcriptomics to aid in the discovery and identification of peptides. Proteogenomics is used to identify new peptides by comparing MS/MS spectra against a protein database that has been derived from genomic and transcriptomic information. Proteogenomics often refers to studies that use proteomic information, often derived from mass spectrometry, to improve gene annotations. The utilization of both proteomics and genomics data alongside advances in the availability and power of spectrographic and chromatographic technology led to the emergence of proteogenomics as its own field in 2004.
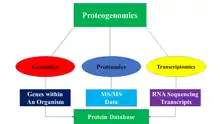
Proteomics deals with proteins in the same way that Genomics studies the genetic code of entire organisms, while Transcriptomics deals with the study of RNA sequencing and transcripts. While all three fields might use forms of mass spectrometry and chromatography to identify and study the functions of DNA, RNA, and proteins, proteomics relies on the assumption that current gene models are correct and that all relevant protein sequences can be found in a reference database such as the Proteomics Identifications Database. Proteogenomics helps eliminate this reliance on existing, limited genetic models by combining datasets from multiple fields in order to produce a database of proteins or genetic markers. In addition, the emergence of novel protein sequences due to mutations often cannot be accounted for in traditional proteomic databases, but can be predicted and studied using a synthesis of genomic and transcriptomic data.
The resulting research has applications in improving gene annotations, studying mutations, and understanding the effects of genetic manipulation.
More recently, the joint profiling of surface proteins and mRNA transcripts from single cells by methods such as CITE-Seq and ESCAPE [1] has been referred to as single-cell proteogenomics,[2][3][4] although the goals of these studies are not related to peptide identification. Since 2019 these methods are more commonly referred to as multimodal omics or multi-omics.[5]
History
Proteogenomics emerged as an independent field in 2004, based on the integration of technological advancements in next-generation sequencing genomics, and mass spectrometry proteomics.[6] The term itself came into use that year, with the publication of a paper by George Church’s research group describing their discovery of a proteogenomic mapping technique that utilized proteomics data to better annotate the genome of the bacteria M. pneumoniae. By using a modern protein database, the lab mapped peptides detected in a whole cell onto a genetic scaffold using tandem mass spectrometry, then used the generated "hits" in order to create a "proteogenomic map" based on traditional genetic signals. The resulting map proved extremely accurate, with over 81% of predicted genomic reading frames being detected in the bacterial cells studied. In addition, the lab discovered several new frames not predicted via purely genetic methods, as well as some evidence supporting the idea that several predictions based genetic models could be false, proving the accuracy and cost-effectiveness of the hybrid technique.[7][8]
The field expanded over the next two decades, initially using proteomics data to aid in refining genetic models via protein databases.[6] In 2020s, one of the most common technique for identifying peptides involves using tandem mass spectrometry. This technique originated with Eng and Yates in 1994 which involves comparing a theoretical peptide fragment spectrum to compare an experimentally derived peptide spectrum to and outputting the most likely matches found.[7] However, in the absence of an established peptide database, Proteogenomics instead compares the experimental spectrum to a genomic database instead which can then be used for genome annotation - as described in George Church's work.[3] The latter technique has become more widely used over the last decade in large part due to the increasing affordability and speed of genomic sequencing techniques coupled with the increasing sensitivity of mass spectrometry-based proteomics.[6]
Methodology

The main idea behind the proteogenomic approach is to identify peptides by comparing MS/MS data to protein databases that contain predicted protein sequences.[9] The protein database is generated in a variety of ways through the utilization of genomic and transcriptomic data. Below are some of the ways in which protein databases are generated:
Six-frame translation
Six-frame translations can be utilized to generate a database that predicts protein sequences. The limitation of this method is that databases will be very large due to the number of sequences that are generated, some of which do not exist in nature.[10]
Ab initio gene prediction
In this method, a protein base is generated by gene predicting algorithms that enable the identification of protein coding regions. The database is similar to one generated through six-frame translation in regards to the fact that the databases can be very large.[10]
Expressed sequence tag data
Six-frame translations can utilize an expressed sequence tag (EST) to generate protein databases. EST data provide transcription information that can aid in the creation of the database. The database can be very large and has the disadvantage of having multiple copies of a given sequence present; however, this problem can be circumvented by compressing the protein sequence generated through computational strategies.[10]
Other methods
Protein databases can also be created by using RNA sequencing data, annotated RNA transcripts, and variant protein sequences. Also, there are other more specialized protein databases that can be made to appropriately identify the peptide of interest.[10]
Another method in the identification of proteins through proteogenomics is comparative proteogenomics. Comparative proteogenomics compares proteomic data from multiple related species concurrently and exploits the homology between their proteins to improve annotations with higher statistical confidence.[11][12]
Applications
Proteogenomics can be applied in different ways. One application is the improvement of gene annotations in various organisms. Gene annotation involves discovering genes and their functions.[13] Proteogenomics has become especially useful in the discovery and improvement of gene annotations in prokaryotic organisms. For example, various microorganisms have had their genomic annotation studied through the proteogenomic approach including, Escherichia coli, Mycobacterium, and multiple species of Shewanella bacteria. [14]
Besides improving gene annotations, proteogenomic studies can also provide valuable information about the presence of programmed frameshifts, N-terminal methionine excision, signal peptides, proteolysis and other post-translational modifications.[15][11] Proteogenomics has potential applications in medicine, especially to oncology research. Cancer occurs through genetic mutations such as methylation, translocation, and somatic mutations. Research has shown that both genomic and proteomic information are needed to understand the molecular variations that lead to cancer.[16][17] Proteogenomics has aided in this through the identification of protein sequences that may have functional roles in cancer.[18] A specific example of this occurred in a study involving colon cancer that resulted in the discovery of potential targets for cancer treatment.[16] Proteogenomics has also led to personalized cancer targeting immunotherapies, where antibody epitopes for cancer antigens are predicted using proteogenomics to create medicines that act on the patient's specific tumor.[19] In addition to treatment, proteogenonomics may provide insight into cancer diagnosis. In studies involving colon and rectal cancer, proteogenomics was utilized to identify somatic mutations. The identification of somatic mutations in patients could be used to diagnose cancer in patients. In addition to direct applications in cancer treatment and diagnosis, a proteogenomic approach can be used to study proteins that result in resistance to chemotherapy.[17]
Challenges
Proteogenomics may offer methods of peptide identification without having the disadvantage of incomplete or inaccurate protein databases faced by proteomics; however, there are incurring challenges with the proteogenomic approach.[10] One of the biggest challenges of proteogenomics is the sheer size of protein databases generated. statistically, a large protein database is more likely to result in the incorrect matching of the data from the protein database to the MS/MS data, this issue can hinder the identification of new peptides. False positives are also an issue through proteogenomic approaches. false positives can occur as a result of extremely large protein data bases where miss-matched data leads to incorrect identification. Another issue is the incorrect matching of MS/MS spectra to protein sequence data that corresponds to a similar peptide instead of the actual peptide. There are cases of receiving data of a peptide located at multiple gene sites, this can lead to data that can be interpreted in different ways. Despite these challenges, there are ways to reduce many of the errors that occur. For example, when dealing with a very large protein database, one could compare the identified novel peptide sequences to all of the sequences within the database and then compare the post translational modifications. Next it can be determined if the two sequences represent the same peptide or if they are two different peptides.[10]
References
- "Proteona ESCAPE RNA Sequencing". 11 December 2018.
- "Proteona Driving Adoption of Immune Profiling Platform for CAR-T, Multiple Myeloma Research". Precision Oncology News. 2021-05-07. Retrieved 2021-05-15.
- "TotalSeq eBook". BioLegend. Retrieved November 23, 2020.
- "Proteona releases ESCAPE™ RNA sequencing for measuring protein and RNA in single cells with a focus on clinical questions". Proteona. Retrieved November 23, 2020.
- "Method of the Year 2019: Single-cell multimodal omics". Nature Methods. 17 (1): 1. January 2020. doi:10.1038/s41592-019-0703-5. ISSN 1548-7105. PMID 31907477.
- Menschaert, Gerben; Fenyö, David (2017). "Proteogenomics from a bioinformatics angle: A growing field". Mass Spectrometry Reviews. 36 (5): 584–599. Bibcode:2017MSRv...36..584M. doi:10.1002/mas.21483. ISSN 1098-2787. PMC 6101030. PMID 26670565.
- Ruggles, Kelly V.; Krug, Karsten; Wang, Xiaojing; Clauser, Karl R.; Wang, Jing; Payne, Samuel H.; Fenyö, David; Zhang, Bing; Mani, D. R. (2017-06-01). "Methods, Tools and Current Perspectives in Proteogenomics*". Molecular & Cellular Proteomics. 16 (6): 959–981. doi:10.1074/mcp.MR117.000024. ISSN 1535-9476. PMC 5461547. PMID 28456751.
- Jaffe, Jacob D.; Berg, Howard C.; Church, George M. (January 2004). "Proteogenomic mapping as a complementary method to perform genome annotation". Proteomics. 4 (1): 59–77. doi:10.1002/pmic.200300511. ISSN 1615-9853. PMID 14730672. S2CID 10747815.
- Nesvizhskii, Alexey I. (November 2014). "Proteogenomics: concepts, applications and computational strategies". Nature Methods. 11 (11): 1114–1125. doi:10.1038/nmeth.3144. ISSN 1548-7105. PMC 4392723. PMID 25357241.
- Nesvizhskii, Alexey I (1 November 2014). "Proteogenomics: concepts, applications and computational strategies". Nature Methods. 11 (11): 1114–1125. doi:10.1038/nmeth.3144. PMC 4392723. PMID 25357241.
- Gupta N., Benhamida J., Bhargava V., Goodman D., Kain E., Kerman I., Nguyen N., Ollikainen N., Rodriguez J., Wang J., et al. Comparative proteogenomics: Combining mass spectrometry and comparative genomics to analyze multiple genomes. Genome Res. 2008;18:1133–1142.
- Gallien S., Perrodou E., Carapito C., Deshayes C., Reyrat J. M., Van Dorsselaer A., Poch O., Schaeffer C., Lecompte O. ( 2009) Ortho-proteogenomics: multiple proteomes investigation through orthology and a new MS-based protocol. Genome Res 19, 128– 135.
- Ansong, C.; Purvine, S. O.; Adkins, J. N.; Lipton, M. S.; Smith, R. D. (7 March 2008). "Proteogenomics: needs and roles to be filled by proteomics in genome annotation". Briefings in Functional Genomics and Proteomics. 7 (1): 50–62. doi:10.1093/bfgp/eln010. PMID 18334489.
- Kucharova, Veronika; Wiker, Harald G. (December 2014). "Proteogenomics in microbiology: Taking the right turn at the junction of genomics and proteomics". Proteomics. 14 (23–24): 2360–2675. doi:10.1002/pmic.201400168. hdl:1956/9547. PMID 25263021. S2CID 3240135.
- Gupta N., Tanner S., Jaitly N., Adkins J.N., Lipton M., Edwards R., Romine M., Osterman A., Bafna V., Smith R.D., et al. Whole proteome analysis of post-translational modifications: Applications of mass-spectrometry for proteogenomic annotation. Genome Res. 2007;17:1362–1377.
- Sajjad, Wasim; Rafiq, Muhammad; Ali, Barkat; Hayat, Muhammad; Zada, Sahib; Sajjad, Wasim; Kumar, Tanweer (July 2016). "Proteogenomics: New Emerging Technology". HAYATI Journal of Biosciences. 23 (3): 97–100. doi:10.1016/j.hjb.2016.11.002.
- Shukla, Hem D.; Mahmood, Javed; Vujaskovic, Zeljko (December 2015). "Integrated proteo-genomic approach for early diagnosis and prognosis of cancer". Cancer Letters. 369 (1): 28–36. doi:10.1016/j.canlet.2015.08.003. PMID 26276717.
- Chambers, Matthew C.; Jagtap, Pratik D.; Johnson, James E.; McGowan, Thomas; Kumar, Praveen; Onsongo, Getiria; Guerrero, Candace R.; Barsnes, Harald; Vaudel, Marc (2017-11-01). "An Accessible Proteogenomics Informatics Resource for Cancer Researchers". Cancer Research. 77 (21): e43–e46. doi:10.1158/0008-5472.can-17-0331. PMC 5675041. PMID 29092937.
- Creech, Amanda L.; Ting, Ying S.; Goulding, Scott P.; Sauld, John FK; Barthelme, Dominik; Rooney, Michael S.; Addona, Terri A.; Abelin, Jennifer G. (2018). "The role of mass spectrometry and proteogenomics in the advancement of HLA epitope prediction". Proteomics. 18 (12): e1700259. doi:10.1002/pmic.201700259. ISSN 1615-9861. PMC 6033110. PMID 29314742.
| Genomics | |
|---|---|
| Bioinformatics | |
| Structural biology | |
| Research tools | |
| Organizations | |
| |