Goodyear MPP
The Goodyear Massively Parallel Processor (MPP) was a massively parallel processing supercomputer built by Goodyear Aerospace for the NASA Goddard Space Flight Center. It was designed to deliver enormous computational power at lower cost than other existing supercomputer architectures, by using thousands of simple processing elements, rather than one or a few highly complex CPUs. Development of the MPP began circa 1979; it was delivered in May 1983, and was in general use from 1985 until 1991.
 The MPP | |
| Discontinued | 1991 |
|---|---|
| Type | Supercomputer |
| Memory | 32 MB Staging Memory |
It was based on Goodyear's earlier STARAN array processor, a 4x256 1-bit processing element (PE) computer. The MPP was a 128x128 2-dimensional array of 1-bit wide PEs. In actuality 132x128 PEs were configured with a 4x128 configuration added for fault tolerance to substitute for up to 4 rows (or columns) of processors in the presence of problems. The PEs operated in a single instruction, multiple data (SIMD) fashion—each PE performed the same operation simultaneously, on different data elements, under the control of a microprogrammed control unit.
After the MPP was retired in 1991, it was donated to the Smithsonian Institution, and is now in the collection of the National Air and Space Museum's Steven F. Udvar-Hazy Center. It was succeeded at Goddard by the MasPar MP-1 and Cray T3D massively parallel computers.
Applications
The MPP was initially developed for high-speed analysis of satellite images. In early tests, it was able to extract and separate different land-use areas on Landsat imagery in 18 seconds, as compared with 7 hours on a DEC VAX-11/780.[1]
Once the system was put into production use, NASA's Office of Space Science and Applications solicited proposals from scientists across the country to test and implement a wide range of computational algorithms on the MPP. 40 projects were accepted, to form the "MPP Working Group"; results of most of them were presented at the First Symposium on the Frontiers of Massively Parallel Computation, in 1986.
Some examples of applications that were made of the MPP are:

- Signal processing of synthetic aperture radar data
- Generating topographic maps via stereo analysis of satellite images
- Mathematical modeling of ocean circulation
- Ray traced computer graphics
- Neural networks
- Solving large systems of linear equations
- Simulation of cosmic ray charged particle transport
- High resolution Mandelbrot sets
System architecture
The overall MPP hardware consisted of the Array Unit, Array Control Unit, Staging Memory, and Host Processor.
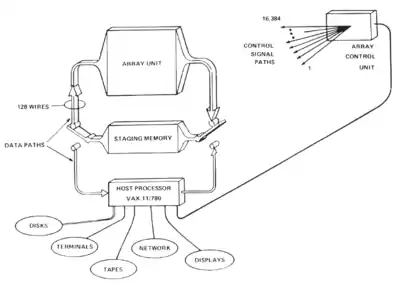
The Array Unit was the heart of the MPP, being the 128x128 array of 16,384 processing elements. Each PE was connected to its four nearest neighbors - north, south, east, and west. The array could be configured as a plane, a cylinder, a daisy-chain or as a torus. The PEs were implemented on a custom silicon-on-sapphire LSI chip which contained eight of the PEs as a 2x4 subarray. Each of the PEs had arithmetic and logic units, 35 shift registers, and 1024 bits of random-access memory implemented with off-the-shelf memory chips. The processors worked in a bit-slice manner and could operate on variable lengths of data. The operating frequency of the array was 10 MHz. Data-bus states of all 16,384 PEs were combined in a tree of inclusive-or logic elements whose single output was used in the Array Control Unit for operations such as finding the maximum or minimum value of an array in parallel. A register in each PE controlled masking of operations — masked operations were only performed on those PEs where this register bit was set.
The Array Control Unit (ACU) broadcast commands and memory addresses to all PEs in the Array Unit, and received status bits from the Array Unit. It performed bookkeeping operations such as loop control and subroutine calling. Application program code was stored in the ACU's memory; the ACU executed scalar parts of the program, and then queued up parallel instructions for the array. It also controlled the shifting of data among PEs, and between the Array Unit and the Staging Memory.
The Staging Memory was a 32 MB block of memory for buffering Array Unit data. It was useful because the PEs themselves had only a total of 2 MB of memory (1024 bits per PE), and because it provided higher communication bit rate than the Host Processor connection (80 megabytes/second versus 5 megabytes/second). The Staging Memory also provided data-manipulation features such as "corner turning" (rearranging byte- or word-oriented data from the array) and multi-dimensional array access. Data was moved between the Staging Memory and the array via 128 parallel lines.
The Host Processor was a front-end computer that loaded programs and data into the MPP, and provided software development tools and networked access to the MPP. The original Host Processor was a PDP-11, which was soon replaced by a VAX-11/780 connected to the MPP by a DR-780 channel. The VAX ran the VMS operating system, and was programmed in MPP Pascal.
Speed of operations
The raw computing speed for basic arithmetic operations on the MPP was as follows:
| Operation | Millions of operations per second |
|---|---|
| Addition of arrays | |
| 8-bit integers (9-bit sum) | 6553 |
| 12-bit integers (13-bit sum) | 4428 |
| 32-bit floating point numbers | 430 |
| Multiplication of arrays | |
| 8-bit integers (16-bit product) | 1861 |
| 12-bit integers (24-bit product) | 910 |
| 32-bit floating point numbers | 216 |
| Multiplication of array by scalar | |
| 8-bit integers (16-bit product) | 2340 |
| 12-bit integers (24-bit product) | 1260 |
| 32-bit floating point numbers | 373 |
References
- Fischer, James R.; Goodyear Aerospace Corporation (1987). "Appendix B. Technical Summary". Frontiers of massively parallel scientific computation. National Aeronautics and Space Administration, Scientific and Technical Information Office. pp. 289–294. Retrieved 11 June 2012.
- Batcher, K. E. (1 September 1980). "Design of a Massively Parallel Processor". IEEE Transactions on Computers. C-29 (9): 836–840. doi:10.1109/TC.1980.1675684. S2CID 13351618.
- Batcher, Ken (1998). "Retrospective: Architecture of a massively parallel processor". 25 years of the international symposia on Computer architecture (Selected papers). pp. 15–16. doi:10.1145/285930.285937. ISBN 978-1581130584. S2CID 1875609.
{{cite book}}:|journal=ignored (help) - J. L. Potter, ed. (1986). Massively parallel processor. [S.l.]: Mit Press. ISBN 9780262661799.
- Neil Boyd Coletti, "Image processing on MPP-like arrays", Ph.D. thesis, Department of Computer Science, University of Illinois at Urbana-Champaign, 1983.
- Efstratios J. Gallopoulos; Scott D. McEwan (1983). Numerical Experiments with the Massively Parallel Processor. Department of Computer Science, University of Illinois at Urbana-Champaign. Retrieved 11 June 2012.
- Gallopoulos, E.J. (July 1985). "The Massively Parallel Processor for problems in fluid dynamics". Computer Physics Communications. 37 (1–3): 311–315. Bibcode:1985CoPhC..37..311G. doi:10.1016/0010-4655(85)90167-5.
- E. Gallopoulos, D. Kopetzky, S.McEwan, D.L. Slotnick and A. Spry, "MPP program development and simulation". In "The Massively Parallel Processor", J.L. Potter ed., pp. 276–290, MIT Press, 1985
- Tom Henkel. "MPP processes satellite data; Supercomputer claims world's fastest I/O rate", Computerworld, 13 Feb 1984, p. 99.
- Eric J. Lerner. "Many processors make light work", Aerospace America, February 1986, p. 50.
- "Massively Parallel Processor Yields High Speed". Aviation Week & Space Technology. 1984-05-28. p. 157.
- Todd Kushner, Angela Wu, Azriel Rosenfeld, "Image Processing on MPP", Pattern Recognition - PR, vol. 15, no. 3, pp. 121–130, 1982