Fork–join model
In parallel computing, the fork–join model is a way of setting up and executing parallel programs, such that execution branches off in parallel at designated points in the program, to "join" (merge) at a subsequent point and resume sequential execution. Parallel sections may fork recursively until a certain task granularity is reached. Fork–join can be considered a parallel design pattern.[1]: 209 ff. It was formulated as early as 1963.[2][3]
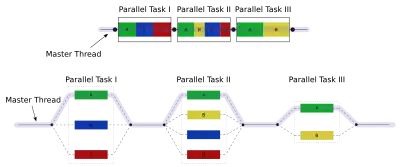
By nesting fork–join computations recursively, one obtains a parallel version of the divide and conquer paradigm, expressed by the following generic pseudocode:[4]
solve(problem):
if problem is small enough:
solve problem directly (sequential algorithm)
else:
for part in subdivide(problem)
fork subtask to solve(part)
join all subtasks spawned in previous loop
return combined results
Examples
The simple parallel merge sort of CLRS is a fork–join algorithm.[5]
mergesort(A, lo, hi):
if lo < hi: // at least one element of input
mid = ⌊lo + (hi - lo) / 2⌋
fork mergesort(A, lo, mid) // process (potentially) in parallel with main task
mergesort(A, mid, hi) // main task handles second recursion
join
merge(A, lo, mid, hi)
The first recursive call is "forked off", meaning that its execution may run in parallel (in a separate thread) with the following part of the function, up to the join that causes all threads to synchronize. While the join may look like a barrier, it is different because the threads will continue to work after a barrier, while after a join only one thread continues.[1]: 88
The second recursive call is not a fork in the pseudocode above; this is intentional, as forking tasks may come at an expense. If both recursive calls were set up as subtasks, the main task would not have any additional work to perform before being blocked at the join.[1]
Implementations
Implementations of the fork–join model will typically fork tasks, fibers or lightweight threads, not operating-system-level "heavyweight" threads or processes, and use a thread pool to execute these tasks: the fork primitive allows the programmer to specify potential parallelism, which the implementation then maps onto actual parallel execution.[1] The reason for this design is that creating new threads tends to result in too much overhead.[4]
The lightweight threads used in fork–join programming will typically have their own scheduler (typically a work stealing one) that maps them onto the underlying thread pool. This scheduler can be much simpler than a fully featured, preemptive operating system scheduler: general-purpose thread schedulers must deal with blocking for locks, but in the fork–join paradigm, threads only block at the join point.[4]
Fork–join is the main model of parallel execution in the OpenMP framework, although OpenMP implementations may or may not support nesting of parallel sections.[6] It is also supported by the Java concurrency framework,[7] the Task Parallel Library for .NET,[8] and Intel's Threading Building Blocks (TBB).[1] The Cilk programming language has language-level support for fork and join, in the form of the spawn and sync keywords,[4] or cilk_spawn and cilk_sync in Cilk Plus.[1]
See also
References
- Michael McCool; James Reinders; Arch Robison (2013). Structured Parallel Programming: Patterns for Efficient Computation. Elsevier.
- Melvin E. Conway (1963). A multiprocessor system design. Fall Join Computer Conference. pp. 139–146. doi:10.1145/1463822.1463838.
- Nyman, Linus; Laakso, Mikael (2016). "Notes on the History of Fork and Join". IEEE Annals of the History of Computing. IEEE Computer Society. 38 (3): 84–87. doi:10.1109/MAHC.2016.34.
- Doug Lea (2000). A Java fork/join framework (PDF). ACM Conference on Java.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. p. 797. ISBN 0-262-03384-4.
- Blaise Barney (12 June 2013). "OpenMP". Lawrence Livermore National Laboratory. Retrieved 5 April 2014.
- "Fork/Join". The Java Tutorials. Retrieved 5 April 2014.
- Daan Leijen; Wolfram Schulte; Sebastian Burckhardt (2009). The design of a Task Parallel Library. OOPSLA.