Domain-specific architecture
A domain-specific architecture (DSA) is a programmable computer architecture specifically tailored to operate very efficiently within the confines of a given application domain. The term is often used in contrast to general-purpose architectures, such as CPUs, that are designed to operate on any computer program.[1]
History
In conjunction with the semiconductor boom that started in the 1960s, computer architects were tasked with finding new ways to exploit the increasingly large number of transistors available. Moore's Law and Dennard Scaling enabled architects to focus on improving the performance of general-purpose microprocessors on general-purpose programs.[2][3]
These efforts yielded several technological innovations, such as multi-level caches, out-of-order execution, deep instruction pipelines, multithreading, and multiprocessing. The impact of these innovations was measured on generalist benchmarks such as SPEC, and architects were not concerned with the internal structure or specific characteristics of these programs.[1]
The end of Dennard Scaling pushed computer architects to switch from a single, very fast processor to several processor cores. Performance improvement could no longer be achieved by simply increasing the operating frequency of a single core.[4]
The end of Moore's Law shifted the focus away from general-purpose architectures towards more specialized hardware. Although general-purpose CPU will likely have a place in any computer system, heterogeneous systems composed of general-purpose and domain-specific components are the most recent trend for achieving high performance.
While hardware accelerators and ASIC have been used in very specialized application domains since the inception of the semiconductor industry, they generally implement a specific function with very limited flexibility. In contrast, the shift towards domain-specific architectures wants to achieve a better balance of flexibility and specialization.[5]
A notable early example of a domain-specific programmable architecture are GPUs. These specialized hardware were developed specifically to operate within the domain of image processing and computer graphics.[6] These programmable processing units found widespread adoption both in gaming consoles and personal computers. With the improvement of the hardware/software stack for both NVIDIA and AMD GPUs, these architectures are being used more and more for the acceleration of massively and embarrassingly parallel tasks, even outside of the domain of image processing.[7]
Since the renaissance of machine-learning-based artificial intelligence in the 2010s, several domain-specific architectures have been developed to accelerate inference for different forms of artificial neural networks. Some examples are Google's TPU, NVIDIA's NVDLA[8] and ARM's MLP.[9]
Guidelines for DSA design
John Hennessy and David Patterson outlined five principles for DSA design that lead to better area efficiency and energy savings. The objective in these types of architecture is often also to reduce the Non-Recurring Engineering (NRE) costs so that the investment in a specialized solution can be more easily amortized.[1]
- Minimize the distance over which data is moved: moving data in general-purpose memory hierarchies requires a remarkable amount of energy in order to attempt to minimize the latency to access data. In the case of Domain-Specific Architectures, it is expected that understanding the application domains by hardware and compiler designers allows for simpler and specialized memory hierarchies, where the data movement is largely handled in software, with tailor-made memories for specific functions within the domain.[1]
- Invest saved resources into arithmetic units or bigger memories: since a remarkable amount of hardware resources can be saved by dropping general-purpose architectural optimizations such as out-of-order execution, prefetching, address coalescing, and hardware speculation, the resources saved should be re-invested to maximally exploit the available parallelism, for example, by adding more arithmetic units or solve any memory bandwidth issues by adding bigger memories.[1]
- Use the easiest form of parallelism that matches the domain: since the target application domains almost always present an inherent form of parallelism, it is important to decide how to take advantage of this parallelism and expose it to the software. If, for example, a SIMD architecture can work in the domain, it would be easier for the programmer to use than a MIMD architecture.[1]
- Reduce data size and type to the simplest needed for the domain: whenever possible, using narrower and simpler data types yields several advantages. For example, it reduces the cost of moving data for memory-bound applications, and it can also reduce the amount of resources required to implement the respective arithmetic units.[1]
- Use a domain-specific programming language to port code to the DSA: one of the challenges for DSAs is ease of use, and more specifically, being able to effectively program the architecture and run applications on it. Whenever possible, it is advised to use existing Domain-Specific Languages (DSL) such as Halide[10] and TensorFlow[11] to more easily program a DSA. Re-use of existing compiler toolchains and software frameworks makes using a new DSA significantly more accessible.[1]
DSA for deep neural networks
One of the application domains where DSA have found the most amount of success is that of artificial intelligence. In particular, several architectures have been developed for the acceleration of Deep Neural Networks (DNN).[12] In the following sections, we report some examples.
 Tensor Processing Unit 3.0 | |
| Designer | |
|---|---|
| Introduced | May 2016 |
| Type | Neural network Machine learning |
TPU
Google's TPU was developed in 2015 to accelerate DNN inference since the company projected that the use of voice search would require to double the computational resources allocated at the time for neural network inference.[13]
The TPU was designed to be a co-processor communicating via a PCIe bus, to be easily incorporated in existing servers. It is primarily a matrix-multiplication engine following a CISC (Complex Instruction Set Computer) ISA. The multiplication engine uses systolic execution to save energy, reducing the number of writes to SRAM.[14]
The TPU was fabricated with a 28-nm process and clocked at 700MHz. The portion of the application that runs on the TPU is implemented in TensorFlow.[14]
The TPU computes primarily reduced precision integers, which further contributes to energy savings and increased performance.[14]
Microsoft Catapult
Microsoft's Project Catapult[15] put an FPGA connected through a PCIe bus into data center servers, with the idea of using the FPGA to accelerate various applications running on the server, leveraging the reconfiguration capabilities of FPGA to accelerate many different applications.
Differently from Google's TPU, the Catapult FPGA needed to be programmed via hardware-description languages such as Verilog and VHDL. For this reason, a major concern for the authors of the framework was the limited programmability.[16]
Microsoft designed a CNN accelerator for the Catapult framework that was primarily designed to accelerate the ranking function in the Bing search engine. The proposed architecture provided a runtime reconfigurable design based on a two-dimensional systolic array.[17][18]
NVDLA
NVDLA is NVIDIA's deep-learning inference accelerator. It is an open-source hardware design available in a number of highly parametrizable configurations. The small-NVDLA model is designed to be deployed in resource-constrained scenarios such as IoT where cost, area and power are the main concerns. Conversely. the large-NVDLA model is more suitable for HPC scenarios. NVDLA provides its own dedicated training infrastructure, compilation tools and runtime software stack.[19]
DSA for other domains
Aside from an application in artificial intelligence, DSAs are being adopted in many domains within scientific computing, image processing, and networking.[20][21]
Pixel Visual Core
The Pixel Visual Core (PVC) is an of ARM-based image processors designed by Google. The PVC is a fully programmable image, vision and AI multi-core domain-specific architecture (DSA) for mobile devices and in future for IoT. It first appeared in the Google Pixel 2 and 2 XL which were introduced on October 19, 2017. It has also appeared in the Google Pixel 3 and 3 XL. Starting with the Pixel 4, this chip was replaced with the Pixel Neural Core.[22]
Anton3
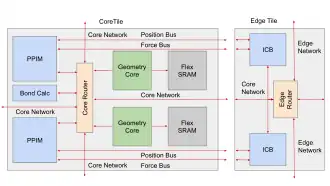
Anton3 is a DSA designed to efficiently compute molecular-dynamics simulations. It uses a specialized 3D torus topology interconnection network to connect several computing nodes.[21] Each computing node contains a set of 64 cores interconnected through a mesh. The cores implement a specialized deep pipeline to efficiently compute the force-field between molecules. This heterogeneous system combines general-purpose hardware and domain-specific components to achieve record-breaking simulation speed.[23]
References
- Hennessy, John L.; Patterson, David A. (2019). Computer architecture: a quantitative approach. Krste Asanović (6 ed.). Cambridge, Mass: Morgan Kaufmann Publishers, an imprint of Elsevier. p. 540. ISBN 978-0-12-811905-1.
- Moore, G.E. (January 1998). "Cramming More Components Onto Integrated Circuits". Proceedings of the IEEE. 86 (1): 82–85. doi:10.1109/jproc.1998.658762. ISSN 0018-9219.
- Dennard, R.H.; Gaensslen, F.H.; Yu, Hwa-Nien; Rideout, V.L.; Bassous, E.; LeBlanc, A.R. (October 1974). "Design of ion-implanted MOSFET's with very small physical dimensions". IEEE Journal of Solid-State Circuits. 9 (5): 256–268. Bibcode:1974IJSSC...9..256D. doi:10.1109/jssc.1974.1050511. ISSN 0018-9200. S2CID 283984.
- Schauer, Bryan. "Multicore Processors – A Necessity" (PDF). Archived from the original (PDF) on 2011-11-25. Retrieved 2023-07-06.
- Barr, Keith Elliott (2007). ASIC design in the silicon sandbox: a complete guide to building mixed-signal integrated circuits. New York: McGraw-Hill. ISBN 978-0-07-148161-8.
- "What is a GPU?". Virtual Desktop. Retrieved 2023-07-07.
- "NVIDIA Accelerated Applications". NVIDIA. Retrieved 2023-07-06.
- "NVDLA - Microarchitectures - Nvidia - WikiChip". en.wikichip.org. Retrieved 2023-07-06.
- "Machine Learning Processor (MLP) - Microarchitectures - ARM - WikiChip". en.wikichip.org. Retrieved 2023-07-06.
- Ragan-Kelley, Jonathan. "Halide". halide-lang.org. Retrieved 2023-07-06.
- "TensorFlow". TensorFlow. Retrieved 2023-07-06.
- Ghayoumi, Mehdi (2021-10-12), "Deep Neural Networks (DNNs) Fundamentals and Architectures", Deep Learning in Practice, Boca Raton: Chapman and Hall/CRC, pp. 77–107, doi:10.1201/9781003025818-5, ISBN 9781003025818, S2CID 241427658, retrieved 2023-07-06
- Hennessy, John L.; Patterson, David A. (2019). Computer architecture: a quantitative approach. Krste Asanović (6 ed.). Cambridge, Mass: Morgan Kaufmann Publishers, an imprint of Elsevier. p. 557. ISBN 978-0-12-811905-1.
- Hennessy, John L.; Patterson, David A. (2019). Computer architecture: a quantitative approach. Krste Asanović (6 ed.). Cambridge, Mass: Morgan Kaufmann Publishers, an imprint of Elsevier. p. 560. ISBN 978-0-12-811905-1.
- "Project Catapult". Microsoft Research. Retrieved 2023-07-06.
- Putnam, Andrew; Caulfield, Adrian M.; Chung, Eric S.; Chiou, Derek; Constantinides, Kypros; Demme, John; Esmaeilzadeh, Hadi; Fowers, Jeremy; Gopal, Gopi Prashanth; Gray, Jan; Haselman, Michael; Hauck, Scott; Heil, Stephen; Hormati, Amir; Kim, Joo-Young (2016-10-28). "A reconfigurable fabric for accelerating large-scale datacenter services". Communications of the ACM. 59 (11): 114–122. doi:10.1145/2996868. ISSN 0001-0782. S2CID 3826382.
- Hennessy, John L.; Patterson, David A. (2019). Computer architecture: a quantitative approach. Krste Asanović (6 ed.). Cambridge, Mass: Morgan Kaufmann Publishers, an imprint of Elsevier. p. 573. ISBN 978-0-12-811905-1.
- "A peck between penguins". Bing. Retrieved 2023-07-06.
- "NVDLA Primer — NVDLA Documentation". nvdla.org. Retrieved 2023-07-06.
- "NVIDIA BlueField Data Processing Units (DPUs)". NVIDIA. Retrieved 2023-07-06.
- Shaw, David E.; Adams, Peter J.; Azaria, Asaph; Bank, Joseph A.; Batson, Brannon; Bell, Alistair; Bergdorf, Michael; Bhatt, Jhanvi; Butts, J. Adam; Correia, Timothy; Dirks, Robert M.; Dror, Ron O.; Eastwood, Michael P.; Edwards, Bruce; Even, Amos (2021-11-14). Anton 3: twenty microseconds of molecular dynamics simulation before lunch. ACM. pp. 1–11. doi:10.1145/3458817.3487397. ISBN 978-1-4503-8442-1. S2CID 239036976.
- Cutress, Ian. "Hot Chips 2018: The Google Pixel Visual Core Live Blog (10am PT, 5pm UTC)". www.anandtech.com. Retrieved 2023-07-07.
- Russell, John (2021-09-02). "Anton 3 Is a 'Fire-Breathing' Molecular Simulation Beast". HPCwire. Retrieved 2023-07-06.
Further reading
- Computer Architecture. A Quantitative Approach. Sixth Edition. John L. Hennessy. Stanford University. David A. Patterson. University of California, Berkeley.