Consistency model
In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable. Consistency models are used in distributed systems like distributed shared memory systems or distributed data stores (such as filesystems, databases, optimistic replication systems or web caching). Consistency is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
High level languages, such as C++ and Java, maintain the consistency contract by translating memory operations into low-level operations in a way that preserves memory semantics, reordering some memory instructions, and encapsulating required synchronization with library calls such as pthread_mutex_lock().[1]
Example
Assume that the following case occurs:[2]
- The row X is replicated on nodes M and N
- The client A writes row X to node M
- After a period of time t, client B reads row X from node N
The consistency model determines whether client B will definitely see the write performed by client A, will definitely not, or cannot depend on seeing the write.
Types
Consistency models define rules for the apparent order and visibility of updates, and are on a continuum with tradeoffs.[2] There are two methods to define and categorize consistency models; issue and view.
- Issue
- Issue method describes the restrictions that define how a process can issue operations.
- View
- View method which defines the order of operations visible to processes.
For example, a consistency model can define that a process is not allowed to issue an operation until all previously issued operations are completed. Different consistency models enforce different conditions. One consistency model can be considered stronger than another if it requires all conditions of that model and more. In other words, a model with fewer constraints is considered a weaker consistency model.
These models define how the hardware needs to be laid out and at a high-level, how the programmer must code. The chosen model also affects how the compiler can re-order instructions. Generally, if control dependencies between instructions and if writes to same location are ordered, then the compiler can reorder as required. However, with the models described below, some may allow writes before loads to be reordered while some may not.
Strong consistency models
Strict consistency
Strict consistency is the strongest consistency model. Under this model, a write to a variable by any processor needs to be seen instantaneously by all processors.
The strict model diagram and non-strict model diagrams describe the time constraint – instantaneous. It can be better understood as though a global clock is present in which every write should be reflected in all processor caches by the end of that clock period. The next operation must happen only in the next clock period.
| Sequence | Strict model | Non-strict model | ||
|---|---|---|---|---|
| P1 | P2 | P1 | P2 | |
| 1 | W(x)1 | W(x)1 | ||
| 2 | R(x)1 | R(x)0 | ||
| 3 | R(x)1 | |||
This is the most rigid model. In this model, the programmer's expected result will be received every time. It is deterministic. Its practical relevance is restricted to a thought experiment and formalism, because instantaneous message exchange is impossible. It doesn't help in answering the question of conflict resolution in concurrent writes to the same data item, because it assumes concurrent writes to be impossible.
Sequential consistency
The sequential consistency model was proposed by Lamport(1979). It is a weaker memory model than strict consistency model.[3] A write to a variable does not have to be seen instantaneously, however, writes to variables by different processors have to be seen in the same order by all processors. Sequential consistency is met if "the result of any execution is the same as if the (read and write) operations of all processes on the data store were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program."[3][4] Adve and Gharachorloo, 1996 define two requirements to implement the sequential consistency; program order and write atomicity.
- Program order: Program order guarantees that each process issues a memory request ordered by its program.
- Write atomicity: Write atomicity defines that memory requests are serviced based on the order of a single FIFO queue.
In sequential consistency, there is no notion of time or most recent write operations. There are some operations interleaving that is the same for all processes. A process can see the write operations of all processes but it can just see its own read operations. Program order within each processor and sequential ordering of operations between processors should be maintained. In order to preserve sequential order of execution between processors, all operations must appear to execute instantaneously or atomically with respect to every other processor.
These operations need only "appear" to be completed because it is physically impossible to send information instantaneously. For instance, in a system utilizing a single globally shared bus, once a bus line is posted with information, it is guaranteed that all processors will see the information at the same instant. Thus, passing the information to the bus line completes the execution with respect to all processors and has appeared to have been executed. Cache-less architectures or cached architectures with interconnect networks that are not instantaneous can contain a slow path between processors and memories. These slow paths can result in sequential inconsistency, because some memories receive the broadcast data faster than others.
Sequential consistency can produce non-deterministic results. This is because the sequence of sequential operations between processors can be different during different runs of the program. All memory operations need to happen in the program order.
Linearizability[6] (also known as atomic consistency or atomic memory)[7] can be defined as sequential consistency with a real-time constraint, by considering a begin time and end time for each operation. An execution is linearizable if each operation taking place in linearizable order by placing a point between its begin time and its end time and guarantees sequential consistency.
Verifying sequential consistency through model checking is undecidable in general, even for finite-state cache coherence protocols.[8]
Causal consistency
Causal consistency[4] defined by Hutto and Ahamad, 1990,[9] is a weakening of the sequential consistency model by categorizing events into those causally related and those that are not. It defines that only write operations that are causally related, need to be seen in the same order by all processes. For example, if an event b takes effect from an earlier event a, the causal consistency guarantees that all processes see event b after event a. Tanenbaum et al., 2007 provide a stricter definition, that a data store is considered causally consistent under the following conditions:[4]
- Writes that are potentially causally related must be seen by all processes in the same order.
- Concurrent writes may be seen in a different order on different machines.
This model relaxes sequential consistency on concurrent writes by a processor and on writes that are not causally related. Two writes can become causally related if one write to a variable is dependent on a previous write to any variable if the processor doing the second write has just read the first write. The two writes could have been done by the same processor or by different processors.
As in sequential consistency, reads do not need to reflect changes instantaneously, however, they need to reflect all changes to a variable sequentially.
| Sequence | P1 | P2 | P3 | P4 |
|---|---|---|---|---|
| 1 | W(x)1 | R(x)1 | R(x)1 | R(x)1 |
| 2 | W(x)2 | |||
| 3 | W(x)3 | R(x)3 | R(x)2 | |
| 4 | R(x)2 | R(x)3 |
W(x)2 happens after W(x)1 due to the read made by P2 to x before W(x)2, hence this example is causally consistent under Hutto and Ahamad's definition (although not under Tanenbaum et al.'s, because W(x)2 and W(x)3 are not seen in the same order for all processes). However R(x)2 and R(x)3 happen in a different order on P3 and P4, hence this example is sequentially inconsistent.[10]
Processor consistency
In order for consistency in data to be maintained and to attain scalable processor systems where every processor has its own memory, the processor consistency model was derived.[10] All processors need to be consistent in the order in which they see writes done by one processor and in the way they see writes by different processors to the same location (coherence is maintained). However, they do not need to be consistent when the writes are by different processors to different locations.
Every write operation can be divided into several sub-writes to all memories. A read from one such memory can happen before the write to this memory completes. Therefore, the data read can be stale. Thus, a processor under PC can execute a younger load when an older store needs to be stalled. Read before write, read after read and write before write ordering is still preserved in this model.
The processor consistency model[11] is similar to the PRAM consistency model with a stronger condition that defines all writes to the same memory location must be seen in the same sequential order by all other processes. Processor consistency is weaker than sequential consistency but stronger than the PRAM consistency model.
The Stanford DASH multiprocessor system implements a variation of processor consistency which is incomparable (neither weaker nor stronger) to Goodman's definitions.[12] All processors need to be consistent in the order in which they see writes by one processor and in the way they see writes by different processors to the same location. However, they do not need to be consistent when the writes are by different processors to different locations.
Pipelined RAM consistency, or FIFO consistency
Pipelined RAM consistency (PRAM consistency) was presented by Lipton and Sandberg in 1988[13] as one of the first described consistency models. Due to its informal definition, there are in fact at least two subtly different implementations,[12] one by Ahamad et al. and one by Mosberger.
In PRAM consistency, all processes view the operations of a single process in the same order that they were issued by that process, while operations issued by different processes can be viewed in different order from different processes. PRAM consistency is weaker than processor consistency. PRAM relaxes the need to maintain coherence to a location across all its processors. Here, reads to any variable can be executed before writes in a processor. Read before write, read after read and write before write ordering is still preserved in this model.
| Sequence | P1 | P2 | P3 | P4 |
|---|---|---|---|---|
| 1 | W(x)1 | |||
| 2 | R(x)1 | |||
| 3 | W(x)2 | |||
| 4 | R(x)1 | R(x)2 | ||
| 5 | R(x)2 | R(x)1 |
Cache consistency
Cache consistency[11][14] requires that all write operations to the same memory location are performed in some sequential order. Cache consistency is weaker than processor consistency and incomparable with PRAM consistency.
Slow consistency
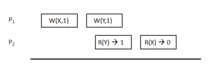
In slow consistency,[14] if a process reads a value previously written to a memory location, it cannot subsequently read any earlier value from that location. Writes performed by a process are immediately visible to that process. Slow consistency is a weaker model than PRAM and cache consistency.
Example: Slow memory diagram depicts a slow consistency example. The first process writes 1 to the memory location X and then it writes 1 to the memory location Y. The second process reads 1 from Y and it then reads 0 from X even though X was written before Y.
Hutto, Phillip W., and Mustaque Ahamad (1990)[9] illustrate that by appropriate programming, slow memory (consistency) can be expressive and efficient. They mention that slow memory has two valuable properties; locality and supporting reduction from atomic memory. They propose two algorithms to present the expressiveness of slow memory.
Session guarantees
These 4 consistency models were proposed in a 1994 paper. They focus on guarantees in the situation where only a single user or application is making data modifications.[15]
Monotonic read consistency
Tanenbaum et al., 2007[4] defines monotonic read consistency as follows:
"If a process reads the value of a data item x, any successive read operation on x by that process will always return that same value or a more recent value."[4]
Monotonic read consistency guarantees that after a process reads a value of data item x at time t, it will never see the older value of that data item.
Monotonic write consistency
Monotonic write consistency condition is defined by Tanenbaum et al., 2007[4] as follows:
"A write operation by a process on a data item X is completed before any successive write operation on X by the same process."[4]
Read-your-writes consistency
A value written by a process on a data item X will be always available to a successive read operation performed by the same process on data item X.[4]
Writes-follows-reads consistency
In writes-follow-reads consistency, updates are propagated after performing the previous read operations. Tanenbaum et al., 2007[4] defines the following condition for writes-follow-reads consistency:
"A write operation by a process on a data item x following a previous read operation on x by the same process is guaranteed to take place on the same or a more recent value of x that was read."[4]
Weak memory consistency models
The following models require specific synchronization by programmers.
Weak ordering
Weak ordering classifies memory operations into two categories: data operations and synchronization operations. To enforce program order, a programmer needs to find at least one synchronisation operation in a program. Synchronization operations signal the processor to make sure it has completed and seen all previous operations done by all processors. Program order and atomicity is maintained only on synchronisation operations and not on all reads and writes. This was derived from the understanding that certain memory operations – such as those conducted in a critical section - need not be seen by all processors until after all operations in the critical section are completed. It assumes reordering memory operations to data regions between synchronisation operations does not affect the outcome of the program. This exploits the fact that programs written to be executed on a multi-processor system contain the required synchronization to make sure that data races do not occur and SC outcomes are produced always.[16]
| P1 | P2 |
|---|---|
X = 1; ''fence'' xready = 1; |
''fence''
while (!xready) {};
''fence''
y = 2; |
Coherence is not relaxed in this model. Once these requirements are met, all other "data" operations can be reordered. The way this works is that a counter tracks the number of data operations and until this counter becomes zero, the synchronisation operation isn't issued. Furthermore, no more data operations are issued unless all the previous synchronisations are completed. Memory operations in between two synchronisation variables can be overlapped and reordered without affecting the correctness of the program. This model ensures that write atomicity is always maintained, therefore no additional safety net is required for weak ordering.
In order to maintain weak ordering, write operations prior to a synchronization operation must be globally performed before the synchronization operation. Operations present after a synchronization operation should also be performed only after the synchronization operation completes. Therefore, accesses to synchronization variables is sequentially consistent and any read or write should be performed only after previous synchronization operations have completed.
There is high reliance on explicit synchronization in the program. For weak ordering models, the programmer must use atomic locking instructions such as test-and-set, fetch-and-op, store conditional, load linked or must label synchronization variables or use fences.
Release consistency
The release consistency model relaxes the weak consistency model by distinguishing the entrance synchronization operation from the exit synchronization operation. Under weak ordering, when a synchronization operation is to be seen, all operations in all processors need to be visible before the synchronization operation is done and the processor proceeds. However, under the release consistency model, during the entry to a critical section, termed as "acquire", all operations with respect to the local memory variables need to be completed. During the exit, termed as "release", all changes made by the local processor should be propagated to all other processors. Coherence is still maintained.
The acquire operation is a load/read that is performed to access the critical section. A release operation is a store/write performed to allow other processors to use the shared variables.
Among synchronization variables, sequential consistency or processor consistency can be maintained. Using SC, all competing synchronization variables should be processed in order. However, with PC, a pair of competing variables need to only follow this order. Younger acquires can be allowed to happen before older releases.[17]
RCsc and RCpc
There are two types of release consistency, release consistency with sequential consistency (RCsc) and release consistency with processor consistency (RCpc). The latter type denotes which type of consistency is applied to those operations nominated below as special.
There are special (cf. ordinary) memory operations, themselves consisting of two classes of operations: sync or nsync operations. The latter are operations not used for synchronisation; the former are, and consist of acquire and release operations. An acquire is effectively a read memory operation used to obtain access to a certain set of shared locations. Release, on the other hand, is a write operation that is performed for granting permission to access the shared locations.
For sequential consistency (RCsc), the constraints are:
- acquire → all,
- all → release,
- special → special.
For processor consistency (RCpc) the write to read program order is relaxed, having constraints:
- acquire → all,
- all → release,
- special → special (except when special write is followed by special read).
Note: the above notation A → B, implies that if the operation A precedes B in the program order, then program order is enforced.
Entry consistency
This is a variant of the release consistency model. It also requires the use of acquire and release instructions to explicitly state an entry or exit to a critical section. However, under entry consistency, every shared variable is assigned a synchronization variable specific to it. This way, only when the acquire is to variable x, all operations related to x need to be completed with respect to that processor. This allows concurrent operations of different critical sections of different shared variables to occur. Concurrency cannot be seen for critical operations on the same shared variable. Such a consistency model will be useful when different matrix elements can be processed at the same time.
Local consistency
In local consistency,[14] each process performs its own operations in the order defined by its program. There is no constraint on the ordering in which the write operations of other processes appear to be performed. Local consistency is the weakest consistency model in shared memory systems.
General consistency
In general consistency,[18] all the copies of a memory location are eventually identical after all processes' writes are completed.
Eventual consistency
An eventual consistency[4] is a weak consistency model in the system with the lack of simultaneous updates. It defines that if no update takes a very long time, all replicas eventually become consistent.
Most shared decentralized databases have an eventual consistency model, either BASE: basically available; soft state; eventually consistent, or a combination of ACID and BASE sometimes called SALT: sequential; agreed; ledgered; tamper-resistant, and also symmetric; admin-free; ledgered; and time-consensual.[19][20][21]
Relaxed memory consistency models
Some different consistency models can be defined by relaxing one or more requirements in sequential consistency called relaxed consistency models.[7] These consistency models do not provide memory consistency at the hardware level. In fact, the programmers are responsible for implementing the memory consistency by applying synchronization techniques. The above models are classified based on four criteria and are detailed further.
There are four comparisons to define the relaxed consistency:
- Relaxation
- One way to categorize the relaxed consistency is to define which sequential consistency requirements are relaxed. We can have less strict models by relaxing either program order or write atomicity requirements defined by Adve and Gharachorloo, 1996. Program order guarantees that each process issues a memory request ordered by its program and write atomicity defines that memory requests are serviced based on the order of a single FIFO queue. In relaxing program order, any or all the ordering of operation pairs, write-after-write, read-after-write, or read/write-after-read, can be relaxed. In the relaxed write atomicity model, a process can view its own writes before any other processors.
- Synchronizing vs. non-synchronizing
- A synchronizing model can be defined by dividing the memory accesses into two groups and assigning different consistency restrictions to each group considering that one group can have a weak consistency model while the other one needs a more restrictive consistency model. In contrast, a non-synchronizing model assigns the same consistency model to the memory access types.
- Issue vs. view-based
- [14] Issue method provides sequential consistency simulation by defining the restrictions for processes to issue memory operations. Whereas, view method describes the visibility restrictions on the events order for processes.
- Relative model strength
- Some consistency models are more restrictive than others. In other words, strict consistency models enforce more constraints as consistency requirements. The strength of a model can be defined by the program order or atomicity relaxations and the strength of models can also be compared. Some models are directly related if they apply the same relaxations or more. On the other hand, the models that relax different requirements are not directly related.
Sequential consistency has two requirements, program order and write atomicity. Different relaxed consistency models can be obtained by relaxing these requirements. This is done so that, along with relaxed constraints, the performance increases, but the programmer is responsible for implementing the memory consistency by applying synchronisation techniques and must have a good understanding of the hardware.
Potential relaxations:
- Write to read program order
- Write to write program order
- Read to read and read to write program orders
Relaxed write to read
An approach to improving the performance at the hardware level is by relaxing the PO of a write followed by a read which effectively hides the latency of write operations. The optimisation this type of relaxation relies on is that it allows the subsequent reads to be in a relaxed order with respect to the previous writes from the processor. Because of this relaxation some programs like XXX may fail to give SC results because of this relaxation. Whereas, programs like YYY are still expected to give consistent results because of the enforcement of the remaining program order constraints.
Three models fall under this category. The IBM 370 model is the strictest model. A read can be complete before an earlier write to a different address, but it is prohibited from returning the value of the write unless all the processors have seen the write. The SPARC V8 total store ordering model (TSO) model partially relaxes the IBM 370 Model, it allows a read to return the value of its own processor's write with respect to other writes to the same location i.e. it returns the value of its own write before others see it. Similar to the previous model, this cannot return the value of write unless all the processors have seen the write. The processor consistency model (PC) is the most relaxed of the three models and relaxes both the constraints such that a read can complete before an earlier write even before it is made visible to other processors.
In Example A, the result is possible only in IBM 370 because read(A) is not issued until the write(A) in that processor is completed. On the other hand, this result is possible in TSO and PC because they allow the reads of the flags before the writes of the flags in a single processor.
In Example B the result is possible only with PC as it allows P2 to return the value of a write even before it is visible to P3. This won't be possible in the other two models.
To ensure sequential consistency in the above models, safety nets or fences are used to manually enforce the constraint. The IBM370 model has some specialised serialisation instructions which are manually placed between operations. These instructions can consist of memory instructions or non-memory instructions such as branches. On the other hand, the TSO and PC models do not provide safety nets, but the programmers can still use read-modify-write operations to make it appear like the program order is still maintained between a write and a following read. In case of TSO, PO appears to be maintained if the R or W which is already a part of a R-modify-W is replaced by a R-modify-W, this requires the W in the R-modify-W is a ‘dummy’ that returns the read value. Similarly for PC, PO seems to be maintained if the read is replaced by a write or is already a part of R-modify-W.
However, compiler optimisations cannot be done after exercising this relaxation alone. Compiler optimisations require the full flexibility of reordering any two operations in the PO, so the ability to reorder a write with respect to a read is not sufficiently helpful in this case.
| P1 | P2 |
|---|---|
| A = flag1 = flag2 = 0 | |
| flag1 = 1 | flag2 = 1 |
| A = 1 | A = 2 |
| reg1 = A | reg3 = A |
| reg2 = flag2 | reg4 = flag1 |
| reg1 = 1; reg3 = 2, reg2 = reg4 = 0 | |
| P1 | P2 | P3 |
|---|---|---|
| A = B = 0 | ||
| A = 1 | ||
| if (A == 1) | ||
| B = 1 | if (B == 1) | |
| reg1 = A | ||
| B = 1, reg1 = 0 | ||
Relaxed write to read and write to write
Some models relax the program order even further by relaxing even the ordering constraints between writes to different locations. The SPARC V8 partial store ordering model (PSO) is the only example of such a model. The ability to pipeline and overlap writes to different locations from the same processor is the key hardware optimisation enabled by PSO. PSO is similar to TSO in terms of atomicity requirements, in that it allows a processor to read the value of its own write and prevents other processors from reading another processor's write before the write is visible to all other processors. Program order between two writes is maintained by PSO using an explicit STBAR instruction. The STBAR is inserted in a write buffer in implementations with FIFO write buffers. A counter is used to determine when all the writes before the STBAR instruction have been completed, which triggers a write to the memory system to increment the counter. A write acknowledgement decrements the counter, and when the counter becomes 0, it signifies that all the previous writes are completed.
In the examples A and B, PSO allows both these non-sequentially consistent results. The safety net that PSO provides is similar to TSO's, it imposes program order from a write to a read and enforces write atomicity.
Similar to the previous models, the relaxations allowed by PSO are not sufficiently flexible to be useful for compiler optimisation, which requires a much more flexible optimisation.
Relaxing read and read to write program orders: Alpha, RMO, and PowerPC
In some models, all operations to different locations are relaxed. A read or write may be reordered with respect to a different read or write in a different location. The weak ordering may be classified under this category and two types of release consistency models (RCsc and RCpc) also come under this model. Three commercial architectures are also proposed under this category of relaxation: the Digital Alpha, SPARC V9 relaxed memory order (RMO), and IBM PowerPC models.
These three commercial architectures exhibit explicit fence instructions as their safety nets. The Alpha model provides two types of fence instructions, memory barrier (MB) and write memory barrier (WMB). The MB operation can be used to maintain program order of any memory operation before the MB with a memory operation after the barrier. Similarly, the WMB maintains program order only among writes. The SPARC V9 RMO model provides a MEMBAR instruction which can be customised to order previous reads and writes with respect to future read and write operations. There is no need for using read-modify-writes to achieve this order because the MEMBAR instruction can be used to order a write with respect to a succeeding read. The PowerPC model uses a single fence instruction called the SYNC instruction. It is similar to the MB instruction, but with a little exception that reads can occur out of program order even if a SYNC is placed between two reads to the same location. This model also differs from Alpha and RMO in terms of atomicity. It allows a write to be seen earlier than a read's completion. A combination of read modify write operations may be required to make an illusion of write atomicity.
RMO and PowerPC allow reordering of reads to the same location. These models violate sequential order in examples A and B. An additional relaxation allowed in these models is that memory operations following a read operation can be overlapped and reordered with respect to the read. Alpha and RMO allow a read to return the value of another processor's early write. From a programmer's perspective these models must maintain the illusion of write atomicity even though they allow the processor to read its own write early.
Transactional memory models
Transactional memory model[7] is the combination of cache coherency and memory consistency models as a communication model for shared memory systems supported by software or hardware; a transactional memory model provides both memory consistency and cache coherency. A transaction is a sequence of operations executed by a process that transforms data from one consistent state to another. A transaction either commits when there is no conflict or aborts. In commits, all changes are visible to all other processes when a transaction is completed, while aborts discard all changes. Compared to relaxed consistency models, a transactional model is easier to use and can provide higher performance than a sequential consistency model.
Other consistency models
Some other consistency models are as follows:
- Causal+ consistency[22][23]
- Delta consistency
- Fork consistency
- One-copy serializability
- Serializability
- Vector-field consistency
- Weak consistency
- Strong consistency
Several other consistency models have been conceived to express restrictions with respect to ordering or visibility of operations, or to deal with specific fault assumptions.[24]
Consistency and replication
Tanenbaum et al., 2007[4] defines two main reasons for replicating; reliability and performance. Reliability can be achieved in a replicated file system by switching to another replica in the case of the current replica failure. The replication also protects data from being corrupted by providing multiple copies of data on different replicas. It also improves the performance by dividing the work. While replication can improve performance and reliability, it can cause consistency problems between multiple copies of data. The multiple copies are consistent if a read operation returns the same value from all copies and a write operation as a single atomic operation (transaction) updates all copies before any other operation takes place. Tanenbaum, Andrew, & Maarten Van Steen, 2007[4] refer to this type of consistency as tight consistency provided by synchronous replication. However, applying global synchronizations to keep all copies consistent is costly. One way to decrease the cost of global synchronization and improve the performance can be weakening the consistency restrictions.
Data-centric consistency models
Tanenbaum et al., 2007[4] defines the consistency model as a contract between the software (processes) and memory implementation (data store). This model guarantees that if the software follows certain rules, the memory works correctly. Since, in a system without a global clock, defining the last operation among writes is difficult, some restrictions can be applied on the values that can be returned by a read operation. The goal of data-centric consistency models is to provide a consistent view on a data store where processes may carry out concurrent updates.
Consistent ordering of operations
Some consistency models such as sequential and also causal consistency models deal with the order of operations on shared replicated data in order to provide consistency. In these models, all replicas must agree on a consistent global ordering of updates.
Grouping operations
In grouping operation, accesses to the synchronization variables are sequentially consistent. A process is allowed to access a synchronization variable that all previous writes have been completed. In other words, accesses to synchronization variables are not permitted until all operations on the synchronization variables are completely performed.[4]
Client-centric consistency models
In distributed systems, maintaining sequential consistency in order to control the concurrent operations is essential. In some special data stores without simultaneous updates, client-centric consistency models can deal with inconsistencies in a less costly way. The following models are some client-centric consistency models:[4]
Consistency protocols
The implementation of a consistency model is defined by a consistency protocol. Tanenbaum et al., 2007[4] illustrates some consistency protocols for data-centric models.
Continuous consistency
Continuous consistency introduced by Yu and Vahdat (2000).[25] In this model, the consistency semantics of an application is described by using conits in the application. Since the consistency requirements can differ based on application semantics, Yu and Vahdat (2000)[25] believe that a predefined uniform consistency model may not be an appropriate approach. The application should specify the consistency requirements that satisfy the application semantics. In this model, an application specifies each consistency requirement as a conit (abbreviation of consistency units). A conit can be a physical or logical consistency and is used to measure the consistency. Tanenbaum et al., 2007[4] describes the notion of a conit by giving an example.
There are three inconsistencies that can be tolerated by applications.
- Deviation in numerical values
- [25] Numerical deviation bounds the difference between the conit value and the relative value of the last update. A weight can be assigned to the writes which defines the importance of the writes in a specific application. The total weights of unseen writes for a conit can be defined as a numerical deviation in an application. There are two different types of numerical deviation; absolute and relative numerical deviation.
- Deviation in ordering
- [25] Ordering deviation is the discrepancy between the local order of writes in a replica and their relative ordering in the eventual final image.
- Deviation in staleness between replicas
- [25] Staleness deviation defines the validity of the oldest write by bounding the difference between the current time and the time of the oldest write on a conit not seen locally. Each server has a local queue of uncertain write that is required an actual order to be determined and applied on a conit. The maximal length of uncertain writes queue is the bound of ordering deviation. When the number of writes exceeds the limit, instead of accepting new submitted write, the server will attempt to commit uncertain writes by communicating with other servers based on the order that writes should be executed.
If all three deviation bounds are set to zero, the continuous consistency model is the strong consistency.
Primary-based protocols
Primary-based protocols[4] can be considered as a class of consistency protocols that are simpler to implement. For instance, sequential ordering is a popular consistency model when consistent ordering of operations is considered. The sequential ordering can be determined as primary-based protocol. In these protocols, there is an associated primary for each data item in a data store to coordinate write operations on that data item.
Remote-write protocols
In the simplest primary-based protocol that supports replication, also known as primary-backup protocol, write operations are forwarded to a single server and read operations can be performed locally.
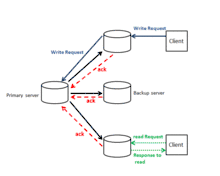
- Example: Tanenbaum et al., 2007[4] gives an example of a primary-backup protocol. The diagram of primary-backup protocol shows an example of this protocol. When a client requests a write, the write request is forwarded to a primary server. The primary server sends request to backups to perform the update. The server then receives the update acknowledgement from all backups and sends the acknowledgement of completion of writes to the client. Any client can read the last available update locally. The trade-off of this protocol is that a client who sends the update request might have to wait so long to get the acknowledgement in order to continue. This problem can be solved by performing the updates locally, and then asking other backups to perform their updates. The non-blocking primary-backup protocol does not guarantee the consistency of update on all backup servers. However, it improves the performance. In the primary-backup protocol, all processes will see the same order of write operations since this protocol orders all incoming writes based on a globally unique time. Blocking protocols guarantee that processes view the result of the last write operation.
Local-write protocols
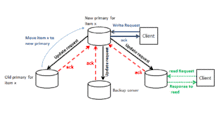
In primary-based local-write protocols,[4] primary copy moves between processes willing to perform an update. To update a data item, a process first moves it to its location. As a result, in this approach, successive write operations can be performed locally while each process can read their local copy of data items. After the primary finishes its update, the update is forwarded to other replicas and all perform the update locally. This non-blocking approach can lead to an improvement. The diagram of the local-write protocol depicts the local-write approach in primary-based protocols. A process requests a write operation in a data item x. The current server is considered as the new primary for a data item x. The write operation is performed and when the request is finished, the primary sends an update request to other backup servers. Each backup sends an acknowledgment to the primary after finishing the update operation.
Replicated-write protocols
In replicated-write protocols,[4] unlike the primary-based protocol, all updates are carried out to all replicas.
Active replication
In active replication,[4] there is a process associated with each replica to perform the write operation. In other words, updates are sent to each replica in the form of an operation in order to be executed. All updates need to be performed in the same order in all replicas. As a result, a totally-ordered multicast mechanism is required. There is a scalability issue in implementing such a multicasting mechanism in large distributed systems. There is another approach in which each operation is sent to a central coordinator (sequencer). The coordinator first assigns a sequence number to each operation and then forwards the operation to all replicas. Second approach cannot also solve the scalability problem.
Quorum-based protocols
Voting can be another approach in replicated-write protocols. In this approach, a client requests and receives permission from multiple servers in order to read and write a replicated data. As an example, suppose in a distributed file system, a file is replicated on N servers. To update a file, a client must send a request to at least N/2 + 1 in order to make their agreement to perform an update. After the agreement, changes are applied on the file and a new version number is assigned to the updated file. Similarly, for reading replicated file, a client sends a request to N/2 + 1 servers in order to receive the associated version number from those servers. Read operation is completed if all received version numbers are the most recent version.[4]
Cache-coherence protocols
In a replicated file system, a cache-coherence protocol[4] provides the cache consistency while caches are generally controlled by clients. In many approaches, cache consistency is provided by the underlying hardware. Some other approaches in middleware-based distributed systems apply software-based solutions to provide the cache consistency.
Cache consistency models can differ in their coherence detection strategies that define when inconsistencies occur. There are two approaches to detect the inconsistency; static and dynamic solutions. In the static solution, a compiler determines which variables can cause the cache inconsistency. So, the compiler enforces an instruction in order to avoid the inconsistency problem. In the dynamic solution, the server checks for inconsistencies at run time to control the consistency of the cached data that has changed after it was cached.
The coherence enforcement strategy is another cache-coherence protocol. It defines how to provide the consistency in caches by using the copies located on the server. One way to keep the data consistent is to never cache the shared data. A server can keep the data and apply some consistency protocol such as primary-based protocols to ensure the consistency of shared data. In this solution, only private data can be cached by clients. In the case that shared data is cached, there are two approaches in order to enforce the cache coherence.
In the first approach, when a shared data is updated, the server forwards invalidation to all caches. In the second approach, an update is propagated. Most caching systems apply these two approaches or dynamically choose between them.
See also
- Cache coherence – Computer architecture term concerning shared resource data
- Distributed shared memory – software and hardware implementations in which each cluster node accesses a large shared memory
- Non-uniform memory access – Computer memory design used in multiprocessing
References
- Mark D. Hill (August 1998). "Multiprocessors Should Support Simple Memory Consistency Models". IEEE Computer. 31 (8): 28–34. doi:10.1109/2.707614.
- Todd Lipcon (2014-10-25). "Design Patterns for Distributed Non-Relational Databases" (PDF). Archived from the original (PDF) on 2014-11-03. Retrieved 2011-03-24.
A consistency model determines rules for visibility and apparent order of updates. Example: * Row X is replicated on nodes M and N * Client A writes row X to node N * Some period of time t elapses. * Client B reads row X from node M * Does client B see the write from client A? Consistency is a continuum with tradeoffs
- Lamport, Leslie (Sep 1979). "How to make a multiprocessor computer that correctly executes multiprocess programs". IEEE Transactions on Computers. C-28 (9): 690–691. doi:10.1109/TC.1979.1675439. S2CID 5679366.
- Tanenbaum, Andrew; Maarten Van Steen (2007). "Distributed systems". Pearson Prentice Hall.
- Herlihy, Maurice P.; Jeannette M. Wing (July 1990). ""Linearizability: A correctness condition for concurrent objects." ACM Transactions on Programming Languages and Systems". ACM Transactions on Programming Languages and Systems. 12 (3): 463–492. CiteSeerX 10.1.1.142.5315. doi:10.1145/78969.78972. S2CID 228785.
- Mankin, Jenny (2007). "CSG280: Parallel Computing Memory Consistency Models: A Survey in Past and Present Research".
{{cite journal}}: Cite journal requires|journal=(help) - Shaz Qadeer (August 2003). "Verifying Sequential Consistency on Shared-Memory Multiprocessors by Model Checking". IEEE Transactions on Parallel and Distributed Systems. 14 (8): 730–741. arXiv:cs/0108016. doi:10.1109/TPDS.2003.1225053. S2CID 1641693.
- Hutto, Phillip W.; Mustaque Ahamad (1990). "Slow memory: Weakening consistency to enhance concurrency in distributed shared memories". Proceedings.,10th International Conference on Distributed Computing Systems. IEEE. pp. 302–309. doi:10.1109/ICDCS.1990.89297. ISBN 978-0-8186-2048-5. S2CID 798676.
- "Memory Consistency Models" (PDF). Archived from the original (PDF) on 2016-03-03. Retrieved 2016-11-17.
- Goodman, James R (1991). "Cache consistency and sequential consistency". IEEE Scalable Coherent Interface (SCI) Working Group.
- Senftleben, Maximilian (2013). Operational Characterization of Weak Memory Consistency Models (PDF) (M.Sc. thesis). University of Kaiserslautern.
- Lipton, R.J.; J.S. Sandberg. (1988). PRAM: A scalable shared memory (Technical report). Princeton University. CS-TR-180-88.
- Steinke, Robert C.; Gary J. Nutt (2004). "A unified theory of shared memory consistency". Journal of the ACM. 51 (5): 800–849. arXiv:cs/0208027. doi:10.1145/1017460.1017464. S2CID 3206071.
- Terry, Douglas B.; Demers, Alan J.; Petersen, Karin; Spreitzer, Mike J.; Theimer, Marvin M.; Welch, Brent B. (1 October 1994). "Session guarantees for weakly consistent replicated data". Proceedings of 3rd International Conference on Parallel and Distributed Information Systems. IEEE Computer Society Press. pp. 140–150. doi:10.1109/PDIS.1994.331722. ISBN 0-8186-6400-2. S2CID 2807044.
- "Shared Memory Consistency Models : A tutorial" (PDF). Archived from the original (PDF) on 2008-09-07. Retrieved 2008-05-28.
- Solihin, Yan (2009). Fundamentals of Parallel Computer Architecture. Solihin Books.
- Singhal, Mukesh; Niranjan G. Shivaratri (1994). "Advanced concepts in operating systems". McGraw-Hill, Inc.
- Collin Cusce. "SALT: A Descriptive Model For Blockchain". 2018.
- Stefan Tai, Jacob Eberhardt, and Markus Klems. "Not ACID, not BASE, but SALT: A Transaction Processing Perspective on Blockchains". 2017.
- Chao Xie, Chunzhi Su, Manos Kapritsos, Yang Wang, Navid Yaghmazadeh, Lorenzo Alvisi, Prince Mahajan. "Salt: Combining ACID and BASE in a Distributed Database".
- Lloyd, Wyatt; Freedman, Michael; Kaminsky, Michael; Andersen, David. "Don't Settle for Eventual:Scalable Causal Consistency for Wide-Area Storage with COPS" (PDF). Proceedings of the 23rd ACM Symposium on Operating Systems Principles (SOSP’11).
- Almeida, Sérgio; Leitão, João; Rodrigues, Luís (2013). "ChainReaction: A causal+ consistent datastore based on chain replication". Proceedings of the 8th ACM European Conference on Computer Systems. pp. 85–98. doi:10.1145/2465351.2465361. ISBN 9781450319942. S2CID 651196.
- Paolo Viotti; Marko Vukolic (2016). "Consistency in Non-Transactional Distributed Storage Systems". ACM Computing Surveys. 49 (1): 19:1–19:34. arXiv:1512.00168. doi:10.1145/2926965. S2CID 118557.
- Yu, Haifeng; Amin Vahdat (2000). "Design and evaluation of a continuous consistency model for replicated services". Proceedings of the 4th Conference on Symposium on Operating System Design & Implementation. 4: 21.
Further reading
- Paolo Viotti; Marko Vukolic (2016). "Consistency in Non-Transactional Distributed Storage Systems". ACM Computing Surveys. 49 (1): 19:1–19:34. arXiv:1512.00168. doi:10.1145/2926965. S2CID 118557.
- Ali Sezgin (2004). "Formalization and verification of shared memory" (PDF).
{{cite journal}}: Cite journal requires|journal=(help) (contains many valuable references) - Kathy Yelick; Dan Bonachea; Chuck Wallace (2004). "A Proposal for a UPC Memory Consistency Model (v1.0)" (PDF).
{{cite journal}}: Cite journal requires|journal=(help) - Mosberger, David (1993). "Memory Consistency Models". Operating Systems Review. 27 (1): 18–26. CiteSeerX 10.1.1.331.2924. doi:10.1145/160551.160553. S2CID 16123648.
- Sarita V. Adve; Kourosh Gharachorloo (December 1996). "Shared Memory Consistency Models: A Tutorial" (PDF). IEEE Computer. 29 (12): 66–76. CiteSeerX 10.1.1.36.8566. doi:10.1109/2.546611. Archived from the original (PDF) on 2008-09-07. Retrieved 2008-05-28.
- Steinke, Robert C.; Gary J. Nutt (2004). "A unified theory of shared memory consistency". Journal of the ACM. 51 (5): 800–849. arXiv:cs.DC/0208027. doi:10.1145/1017460.1017464. S2CID 3206071.
- Terry, Doug. "Replicated data consistency explained through baseball." Communications of the ACM 56.12 (2013): 82-89. https://www.microsoft.com/en-us/research/wp-content/uploads/2011/10/ConsistencyAndBaseballReport.pdf
External links
- IETF slides
- Memory Ordering in Modern Microprocessors, Part I and Part II, by Paul E. McKenney (2005). Linux Journal
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |