The kernel has full access to the system's memory and must allow processes to safely access this memory as they require it. Often the first step in doing this is virtual addressing, usually achieved by paging and/or segmentation. Virtual addressing allows the kernel to make a given physical address appear to be another address, the virtual address. Virtual address spaces may be different for different processes; the memory that one process accesses at a particular (virtual) address may be different memory from what another process accesses at the same address. This allows every program to behave as if it is the only one (apart from the kernel) running and thus prevents applications from crashing each other.
On many systems, a program's virtual address may refer to data which is not currently in memory. The layer of indirection provided by virtual addressing allows the operating system to use other data stores, like a hard drive, to store what would otherwise have to remain in main memory (RAM). As a result, operating systems can allow programs to use more memory than the system has physically available. When a program needs data which is not currently in RAM, the CPU signals to the kernel that this has happened, and the kernel responds by writing the contents of an inactive memory block to disk (if necessary) and replacing it with the data requested by the program. The program can then be resumed from the point where it was stopped. This scheme is generally known as demand paging.
Virtual addressing also allows creation of virtual partitions of memory in two disjointed areas, one being reserved for the kernel (kernel space) and the other for the applications (user space). The applications are not permitted by the processor to address kernel memory, thus preventing an application from damaging the running kernel. This fundamental partition of memory space has contributed much to the current designs of actual general-purpose kernels and is almost universal in such systems, Linux being one of them.
⚲ Shell interface
- cat /proc/meminfo
Process Memory Layout
A 32-bit processor can address a maximum of 4GB of memory. Linux kernels split the 4GB address space between user processes and the kernel; under the most common configuration, the first 3GB of the 32-bit range are given over to user space, and the kernel gets the final 1GB starting at 0xc0000000. Sharing the address space gives a number of performance benefits; in particular, the hardware's address translation buffer can be shared between the kernel and user space.

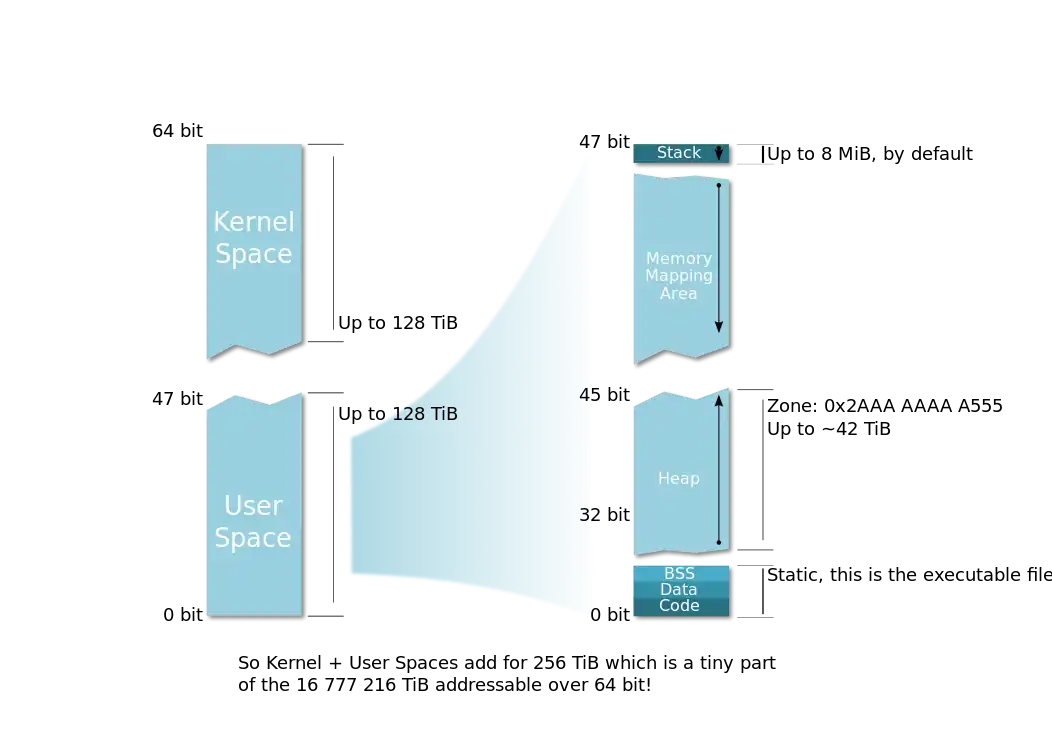
In x86-64, only the least significant 48 bits of a virtual memory address would actually be used in address translation (page table lookup). The remainder bits 48 through 63 of any virtual address must be copies of bit 47, or the processor will raise an exception. Addresses complying with this rule are referred to as "canonical form." Canonical form addresses run from 0 through 00007FFF'FFFFFFFF, and from FFFF8000'00000000 through FFFFFFFF'FFFFFFFF, for a total of 256 TB of usable virtual address space. This is still approximately 64,000 times the virtual address space on 32-bit machines.
Linux takes the higher-addressed half of the address space for itself (kernel space) and leaves the lower-addressed half for user space. The "canonical address" design has, in effect, two memory halves: the lower half starts at 00000000'00000000 and "grows upwards" as more virtual address bits become available, while the higher half is "docked" to the top of the address space and grows downwards.
Memory management Linux API
- ⚲ man 2 brk ↪ ⚙️ brk id, do_brk_flags id dynamically changes data segment size of the calling process.
The change is made by resetting the program break of the process, which determines the maximum space that can be allocated. The program break is the address of the first location beyond the current end of the data region, and determines the maximum space that can be allocated by the process. The amount of available space increases as the break value increases. The added available space is initialized to a value of zero.
- ⚲ man 2 mmap ↪ ⚙️ ksys_mmap_pgoff id maps files or devices into memory.
It is a method of memory-mapped file I/O. It naturally implements demand paging, because file contents are not read from disk initially and do not use physical RAM at all. The actual reads from disk are performed in a "lazy" manner, after a specific location is accessed. After the memory is no longer needed it is important to man 2 unmmap the pointers to it. Protection information can be managed using man 2 mprotect and special treatment can be enforced using man 2 madvise. In Linux, man 2 mmap can create several types of mappings, such as anonymous mappings, shared mappings and private mappings. Using the MAP_ANONYMOUS flag mmap() can map a specific area of the process's virtual memory not backed by any file, whose contents are initialized to zero.
These functions are typically called from a higher-level memory management library function such as C standard library man 3 malloc or C++ new operator.
💾 History: Two basic related to memory management system calls brk and mmap Linux inherits from Unix.
BTW: On Linux, man 2 sbrk is not a separate system call, but a C library function that also calls to sys_brk id and keeps some internal state to return the previous break value.
📚 References
Virtual memory
🔧 TODO
Virtually contiguous memory on top of physical and swapped memory pages.
Acronyms
- VPFN - Virtual Page Frame Number
- PFN - Physical Page Frame Number
- pgd - Page Directory
- pmd - Page Middle Directory
- pte - Page table Entry
- TLB - Translation Lookaside Buffer
- MMU - Memory Management Unit
⚲ API:
⚙️ Internals
virt_to_page id vmalloc_init id find_vma id
📚 References
Data structures
⚲ API:
- list_head id - common double linked list
- linux/list.h inc - basic list_head id operations
- linux/klist.h inc - some klist_node id->kref id helpers
- linux/kfifo.h inc - generic kernel FIFO
- kfifo_in id ...
- linux/rbtree.h inc - Red-black trees
📚 References
- List Management Functions doc
- FIFO Buffer doc
- Data structures and low-level utilities doc
- Everything you never wanted to know about kobjects, ksets, and ktypes doc
- Adding reference counters (krefs) to kernel objects doc
- Generic Associative Array Implementation doc
- XArray doc
- ID Allocation doc
- Circular Buffers doc
- Red-black Trees (rbtree) in Linux doc
- Generic radix trees/sparse arrays doc
- Generic bitfield packing and unpacking functions doc
- How to access I/O mapped memory from within device drivers doc
- this_cpu operations doc
- ktime accessors doc
- The errseq_t datatype doc
Memory mapping
🔧 TODO
Key items:
man 2 mmap man 2 ksys_mmap_pgoff do_mmap id mm_struct id vm_area_struct id vm_struct id remap_pfn_range id SetPageReserved id ClearPageReserved id free_mmap_pages alloc_mmap_pages free_mmap_pages id
📚 References
Swap
🔧 TODO
si_swapinfo id swap_info id handle_pte_fault id do_swap_page id linux/swap.h inc mm/swapfile.c src
Logical memory
⚲ kmalloc id is the normal method of allocating memory in the kernel for objects smaller than the page size. It is defined in linux/slab.h inc. The first argument size is the size (in bytes) of the block of memory to be allocated. The second argument flags are the allocation flags or GFP flags, a set of macros that the caller provides to control the type of requested memory. The most commonly used values for flags are GFP_KERNEL and GFP_ATOMIC, but there is more to be considered.
Memory-allocation requests in the kernel are always qualified by a set of GFP flags ("GFP" initially came from "get free page") describing what can and cannot be done to satisfy the request. The most commonly used flags are GFP_ATOMIC and GFP_KERNEL, though they are actually built up from lower-level flags. The full set of flags is huge; they can be found in the linux/gfp.h inc header file.
⚲ API:
Slab allocation
Slab allocation is a memory management algorithm intended for the efficient memory allocation of kernel objects. It eliminates fragmentation caused by allocations and deallocations. The technique is used to retain allocated memory that contains a data object of a certain type for reuse upon subsequent allocations of objects of the same type.
💾 History: SLAB allocator is the original implementation Slab allocation. It was the default allocator since kernel 2.2 until 2.6.23, when SLUB allocator became the default, but it is still available as an option.
Basics
This section is about SLAB and SLUB allocator implementations
A slab can be thought of as an array of objects of certain type or with the same size, spanning through one or more contiguous pages of memory; for example, the slab named "task_struct" holds objects of struct task_struct type, used by the scheduling subsystem. Other slabs store objects used by other subsystems, and there is also slabs for dynamic allocations inside the kernel, such as the "kmalloc-64" slab that holds up to 64-byte chunks requested via kmalloc() calls. In a slab, each object can be allocated and freed separately.
The primary motivation for slab allocation is that the initialization and destruction of kernel data objects can actually outweigh the cost of allocating memory for them. As object creation and deletion are widely employed by the kernel, overhead costs of initialization can result in significant performance drops. The notion of object caching was therefore introduced in order to avoid the invocation of functions used to initialize object state.
With slab allocation, memory chunks suitable to fit data objects of certain type or size are preallocated. The slab allocator keeps track of these chunks, known as caches kmalloc_caches id, so that when a request to allocate memory for a data object of a certain type is received, it can instantly satisfy the request with an already allocated slot slab_alloc id.
Deallocatoion of the object with kfree id does not free up the memory, but only opens a slot which is put in the list of free slots kmem_cache_cpu id by the slab allocator. The next call to allocate memory of the same size will return the now unused memory slot. See slab_alloc id//___slab_alloc id/get_freelist id. This process eliminates the need to search for suitable memory space and greatly alleviates memory fragmentation. In this context, a slab is one or more contiguous pages in the memory containing pre-allocated memory chunks.
Slab allocation provides a kind of front-end to the zoned buddy allocator for those sections of the kernel that require more flexible memory allocation than the standard 4KB page size.
⚲ Interface:
⚙️ Internals:
- mm/slab_common.c src
- mm_init id is called from start_kernel id
- ____kasan_kmalloc id
SLAB allocator
SLAB is the name given to the first slab allocation implementation in the kernel to distinguish it from later allocators that use the same interface. It's heavily based on Jeff Bonwick's paper "The Slab Allocator: An Object-Caching Kernel Memory Allocator" (1994) describing the first slab allocator implemented in the Solaris 5.4 kernel.
⚙️ Internals: mm/slab.c src
SLUB allocator
SLUB (acronym of "the unqueued slab allocator") is the iteration of the original SLAB allocator that replaced it and became the Linux default allocator since 2.6.23.
⚙️ Internals: mm/slub.c src
SLOB allocator
Unfortunately, SLAB and SLUB allocators consume a big amount of memory allocating their slabs, which is a serious drawback in small systems with memory constraints, such as embedded systems. To overcome it, the SLOB (Simple List Of Blocks) allocator was designed in January 2006 by Matt Mackall as a simpler method to allocate kernel objects.
SLOB allocator uses a first-fit algorithm, which chooses the first available space for memory. This algorithm reduces memory consumption, but a major limitation of this method is that it suffers greatly from internal fragmentation.
The SLOB allocator is also used as a fall back by the kernel build system when no slab allocator is defined (when the CONFIG_SLAB flag is disabled).
⚙️ Internals: mm/slob.c src, slob_alloc id
📚 References
- KASAN - KernelAddressSANitizer doc - dynamic memory safety error detector designed to find out-of-bound and use-after-free bugs
- Video "SL[AUO]B: Kernel memory allocator design and philosophy" Christopher Lameter (Linux.conf.au 2015 conference) Slides
Page Allocator
The page allocator (or "zoned buddy allocator") is a low-level allocator that deals with physical memory. It delivers physical pages (usually with a size of 4096 bytes) of free memory to high-level memory consumers such as the slab allocators and kmalloc(). As the ultimate source of memory in the system, the page allocator must ensure that memory is always available, since a failure providing memory to a critical kernel subsystem can lead to a general system failure or a kernel panic.
The page allocator divides physical memory into "zones", each of which corresponds to zone_type id with specific characteristics. ZONE_DMA contains memory at the bottom of the address range for use by severely challenged devices, for example, while ZONE_NORMAL id may contain most memory on the system. 32-bit systems have a ZONE_HIGHMEM for memory that is not directly mapped into the kernel's address space. Depending on the characteristics of any given allocation request, the page allocator will search the available zones in a specific priority order. For the curious, /proc/zoneinfo gives a lot of information about the zones in use on any given system.
Within a zone, memory is grouped into page blocks, each of which can be marked with a migration type - migratetype id describing how the block should be allocated.
⚲ API:
⚙️ Internals:
- build_all_zonelists id is called from start_kernel id
- __alloc_pages_nodemask id - the 'heart' of the zoned buddy allocator
- struct zone id
- mm/mmzone.c src
- mm/page_alloc.c src
📚 References
Memory addressing
Pages
In Linux, different architectures have different page sizes. The original —for x86 architecture— and still most commonly used page size is 4096 bytes (4 KB). The page size (in bytes) of the current architecture is defined by the PAGE_SIZE macro included in arch/x86/include/asm/page_types.h src header file. User space programs can get this value using the man 2 getpagesize library function. Another related macro is PAGE_SHIFT, that contains the number of bits to shift an address to get its page number —12 bits for 4K pages.
One of the most fundamental kernel data structures relating memory-management is struct page. The kernel keeps track of the status of every page of physical memory present in the system using variables of this type. There are millions of pages in a modern system, and therefore there are millions of these structures in memory.
The full definition of struct page can be found in linux/mm_types.h inc.
📚 References