This Wikibook shows how to transform the probability density of a continuous random variable in both the one-dimensional and multidimensional case. In other words, it shows how to calculate the distribution of a function of continuous random variables. The first section formulates the general problem and provides its solution. However, this general solution is often quite hard to evaluate and simplifications are possible in special cases, e.g., if the random vector is one-dimensional or if the components of the random vector are independent. Formulas for these special cases are derived in the subsequent sections. This Wikibook also aims to provide an overview of different equations used in this field and show their connection.
General Problem and Solution (n-to-m mapping)
Let be a random vector with the probability density function, pdf, and let be a (Borel-measurable) function. We are looking for the probability density function of .





First, we need to remember the definition of the cumulative distribution function, cdf, of a random vector: It measures the probability that each component of Y takes a value smaller than the corresponding component of y. We will use a short-hand notation and say that two vectors are "less or equal" (≤) if all of their components are.

-
()

The wanted density is then obtained by differentiating :

-
()

Thus, the general solution can be expressed as the m‘th derivative of an n-dimensional integral:
-
ℝn → ℝm mapping
()

The following sections will provide simplifications in special cases.
Function of a Random Variable (n=1, m=1)
If n=1 and m=1, X is a continuously distributed random variable with the density and is a Borel-measurable function. Then also Y := f(X) is continuously distributed and we are looking for the density .



In the following, f should always be at least differentiable.
Let us first note that there may be values that are never reached by f, e.g. y<0 if f(x) = x2. For all those y, necessarily .


Following equations 1 and 2, we obtain
-
()

We will now rearrange this expression in various ways.
Derivation using cumulated distribution function

At first, we limit ourselves to f whose derivative is never 0 (thus, f is a diffeomorphism). Then, the inverse map exists and f is either monotonically increasing or monotonically decreasing.

If f is monotonically increasing, then and . Therefore:



If f is monotonically decreasing, then and . Therefore:



This can be summarized as:
-
()

If now the derivative does vanish at some positions , , then we split the definition space of f using those position into disjoint intervals . Equation 5 holds for the functions limited in their definition space to those intervals . We have







With the convention that the sum over 0 addends is 0 and using the inverse function theorem, it is possible to write this in a more compact form (read as: sum over all x, where f(x)=y):
-
ℝ → ℝ mapping
()

Derivation using Integral Substitution
In this section we consider a different derivation.
The probability in 4 is the integral over the probability density. Again in the case of monotonically increasing f, we have:

Now we substitute u = f(x) in the integral on the right hand site, i.e. and . The integral limits are then from -∞ to y and in the rule “” we have due to the inverse function theorem. Consequentially:





Taking the derivative of both sides with respect to y, we get:

Following the same argument as in the last section, we can again derive equation 6.
This rule often misleads physics books to present the following viewpoint, which might be easier to remember, but is not mathematically sound: If you multiply the probability density with the “infinitesimal length” , then you will get the probability for X to lie in the interval [x, x+dx]. Changing to new coordinates y, you will get by substitution:




Derivation using the Delta Distribution
In this section we consider another different derivation, often used in physics.
We start again with equation 4 and write this as an integral:

The intuitive interpretation of the last expression is: one integrates over all possible x-values and uses the delta “function” to pick all positions where y = f(x). This formula is often found in physics books, possibly written as expectation value, :

-
ℝ → ℝ mapping (using Dirac Delta Distribution)
()

We can see this formula is equivalent to equation 6 using the following identity

Examples
- Let us consider the following specific example: let and . We choose to use equation 6 (equations 5 and 7 lead to the same result). We calculate the derivative and find all x for which f(x)=y, which are and if y>0 and none otherwise. For y>0 we have:
![\varrho _{X}(x)={\frac {\exp[-0.5x^{2}]}{{\sqrt {2\pi }}}}](../../I/db7c894041a6b93f33613606a9818a419aef078d.svg)




![\varrho _{Y}(y)=\sum \limits _{{x,f(x)=y}}{\frac {\varrho _{X}(x)}{\left|f^{\prime }(x)\right|}}={\frac {\varrho _{X}(-{\sqrt {y}})}{\left|f^{\prime }(-{\sqrt {y}})\right|}}+{\frac {\varrho _{X}(+{\sqrt {y}})}{\left|f^{\prime }(+{\sqrt {y}})\right|}}={\frac {\exp[-0.5y]}{{\sqrt {2\pi }}\,2{\sqrt {y}}}}+{\frac {\exp[-0.5y]}{{\sqrt {2\pi }}\,2{\sqrt {y}}}}={\frac {\exp[-0.5y]}{{\sqrt {2\pi \,y}}}}](../../I/49781792da05c06cd3a7a245b688fed35c363e58.svg)
- Since f never reaches negative values, the sum remains 0 for y<0 and we finally obtain:
![\varrho _{Y}(y)={\begin{cases}0,&{\text{if }}y\leq 0\\{\frac {\exp[-0.5y]}{{\sqrt {2\pi \,y}}}},&{\text{if }}y>0\end{cases}}](../../I/08feae4e4476c470ba4e83cf5cf5b821dcf9ed20.svg)
- This example is illustrated in the following graphics:






- Another example is the inverse transformation method. Suppose a computer generates random numbers X with a uniform distribution on [0, 1], i.e.

- If we want to obtain random numbers according to a distribution with the pdf , we choose f as the inverse function of the cdf of Z, i.e. . We can now show that Y will have the same distribution as the wanted Z, by using equation 5 and the fact that :




- .

- An example is illustrated in the following plot:
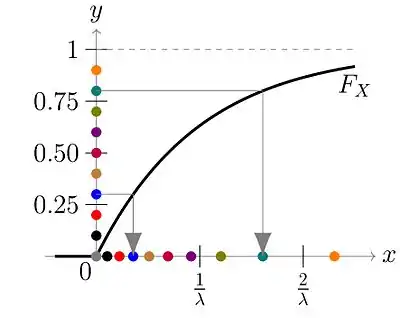 Random numbers yi are generated from a uniform distribution between 0 and 1, i.e. Y ~ U(0, 1). They are sketched as colored points on the y-axis. Each of the points is mapped according to x=F-1(y), which is shown with gray arrows for two example points. In this example, we have used an exponential distribution. Hence, for x ≥ 0, the probability density is and the cumulated distribution function is . Therefore, . We can see that using this method, many points end up close to 0 and only few points end up having high x-values - just as it is expected for an exponential distribution.
Random numbers yi are generated from a uniform distribution between 0 and 1, i.e. Y ~ U(0, 1). They are sketched as colored points on the y-axis. Each of the points is mapped according to x=F-1(y), which is shown with gray arrows for two example points. In this example, we have used an exponential distribution. Hence, for x ≥ 0, the probability density is and the cumulated distribution function is . Therefore, . We can see that using this method, many points end up close to 0 and only few points end up having high x-values - just as it is expected for an exponential distribution.



Mapping of a Random Vector to a Random Variable (n>1, m=1)
We will now investigate the case when a random vector X with known density is mapped to (scalar) random variable Y and calculate the new density .

According to 3, we find:
-
()

The direct evaluation of this equation is sometimes the easiest way, e.g., if there is a known formula for the area or volume presented by the integral. Otherwise one needs to solve a parameter-depended multiple integral.
If the components of the random vector are independent, then the probability density factorizes:


In this case the delta function may provide a fast tool for the evaluation. Replacing the integration bound with a step function inside the integral, and using the fact that the derivative of a step function is the delta:

-
()

If one wants to avoid calculations with the delta function, it is of course possible to evaluate the innermost integral , provided that the components are independent:


Examples
- Let with the independent, continuous random variable X1 and X2. According to equation 9, we have:


- If one uses the sum formula instead, the sum runs over all x1, for which , i.e. where x1 = y - x2.
- The derivative is , so that one also obtains the equation .



- Integrating over x2 first leads to the following, equivalent expression:

- If with independent X1 and X2, then .


- If with independent X1 and X2, then .


- If with independent X1 and X2, then .


- Given the independent random variables X1 and X2 with the density

- Let . According to equation 8, we need to solve:


- The last integral is over a circle with radius y ≤ 1, hence with the area . This simplifies the calculation:

- .

- If y<0, we integrate over an empty set, which gives 0. If y>1, . Therefore, the final result is:


- This example is illustrated in the following graphics:



Invertible Transformation of a Random Vector (n=m)
Let be a a random vector with the density and let be a diffeomorphism. For the density of we have:


and therefore
-
ℝn → ℝn mapping
()

where is the Jacobian determinant of . Note that . In the one-dimensional case (n=1), equation 10 coincides with equation 5.


Examples
- Given the random vector and the invertible matrix A and a vector , let . Then . Also, .
- Given the independent random variables and , we introduce polar coordinates and . The inverse map is and . Due to Jacobian determinant , the wanted density is .












Possible simplifications for multidimensional mappings (n>1, m>1)
Even if none of the above special cases apply, simplifications can still be possible. Some of them are listed below:
Independent Target-Components
If one knows beforehand that the components of will be independent, i.e.


then the density of each component can be calculated like in the above section Mapping of a Random Vector to a Random Variable.


Example
- Given the random vector with independent components.
- Let , .
- Obviously, the components Y1 = X1 + X2 and Y2 = X3 + X4 are independent and therefore:
- and
- .
- Note that the components of can be independent even if the components of are not.






Split Integral Region
Sometimes it is useful to split the integral region in equation 3 into parts that can be evaluate separately. This can be made explicit by rewriting 3 with delta functions:

and then use the identity .

Example
- To illustrate the idea, we use a simple ℝn → ℝ example: Let Y = X12 + X22 + X3 with

- The parametrisation of the region where at the same time x12 + x22 + x3 ≤ y and x12 + x22 ≤ 1 and x3 ≥ 0 may not be obvious, so we use the two above formulas:
![{\begin{array}{rcl}\varrho _{Y}(y)&=&\int _{{{\mathbb {R}}^{3}}}\varrho _{{{\vec {X}}}}({\vec {x}})\,\delta (y-f({\vec {x}}))\,dx_{1}\,dx_{2}\,dx_{3}\\&=&\int _{0}^{\infty }\iint _{{x_{1}^{2}+x_{2}^{2}\leq 1}}{\frac {e^{{-x_{3}}}}{\pi }}\,\delta (y-x_{1}^{2}-x_{2}^{2}-x_{3})\,dx_{1}\,dx_{2}\,dx_{3}\\&=&\int _{0}^{\infty }\iint _{{x_{1}^{2}+x_{2}^{2}\leq 1}}{\frac {e^{{-x_{3}}}}{\pi }}\,\int _{{{\mathbb {R}}}}\delta (\xi -x_{1}^{2}-x_{2}^{2})\,\delta (y-x_{3}-\xi )\,d\xi \,\,dx_{1}\,dx_{2}\,dx_{3}\\&=&\int _{0}^{\infty }\,\int _{{{\mathbb {R}}}}\left[\iint _{{x_{1}^{2}+x_{2}^{2}\leq 1}}{\frac {e^{{-x_{3}}}}{\pi }}\delta (\xi -x_{1}^{2}-x_{2}^{2})\,dx_{1}\,dx_{2}\right]\,\delta (y-x_{3}-\xi )\,d\xi \,dx_{3}\end{array}}](../../I/93bdd9606740d44dbe46b12fee85a7296eb5e749.svg)
- Now, we have split the integral such that the expression in brackets can be evaluated separately, because the region depends on x1 and x2 only and may contain x3 only as parameter.

- Therefore:

Helper Coordinates
If f is injective, then it can be easier to introduce additional helper coordinates Ym+1 to Yn, then do the transformation from section Invertible Transformation of a Random Vector and finally integrate out all helper coordinates of the so-obtained density.

Example
- Given the random vector with the density and the following mapping:



- Now we introduce the helper coordinate Y3 = X3, which results in the transformation matrix

- with the corresponding pdf . Thus, we finally obtain


- Remark: If the joint pdf , i.e. the conditional distribution, is not of interest and one is only interested in the marginal distribution with , then it is possible to calculate the density as described in section Mapping of a Random Vector to a Random Variable for the mapping Y1 = 1 X1 + 2 X2 + 3 X3 (and likewise for Y2 = 4 X1 + 5 X2 + 6 X3).


Real-World Applications
In order to show some possible applications, we present the following questions, which can be answered using the techniques outlines in this Wikibook. In principle, the answers could also be approximated using a numerical random number simulation: generate several realizations of , calculate and make a histogram of the results. However, many such random numbers are needed for reasonable results, especially for higher-dimensional random vectors. Gladly, we can always calculate the resulting distribution analytically using the above formulas.

Statistical Physics
- Suppose atoms in a laser are moving with normally distributed velocities Vx, , σ2 = kBT/m. Due to the Doppler effect, light emitted with frequency f0 by an atom moving with vx will be detected as f ≈ f0 ( 1 + vx / c ). Hence, f is a function of Vx. What does the detected spectrum, , look like? (Answer: Gaussian around f0.)
- Suppose the velocity components of an ideal gas (Vx, Vy, Vz) are identically, independently normally distributed as in the last example. What is the probability density of ? (The answer is known as Maxwell-Boltzmann distribution.)
![{\displaystyle \varrho _{V_{x}}(v_{x})={\frac {\exp[-v_{x}^{2}/2\sigma ^{2}]}{\sqrt {2\pi \sigma ^{2}}}}}](../../I/17e254a89deeeb299ac815b8cf3bcee8f7845a89.svg)



Quantifying Uncertainty of Derived Properties
- Suppose we do not know the exact value of X and Y, but we can assign a probability distribution to each of them. What is the distrubution of the derived property Z = X2 / Y and what is the mean value and standard deviation of Z? (To tackle such problems, linearisation around the mean values are sometimes used and both X and Y are assumed to be normally distributed. However, we are not limited to such restrictions.)
- Suppose we consider the value of one gram gold, silver and platinum in one year from now as independent random variables G, S and P, respectively. Box A contains 1 gram gold, 2 gram silver and 3 gram platinum. Box B contains 4, 5 and 6 gram, respectively. Thus, . What is the value of the contents in box A (or box B) in one year from now? (The answer is given in an example above.) Note that A and B are correlated.

Note that the above examples assume the distribution of to be known. If it is unknown, or if the calculation is based on only a few data points, methods from mathematical statistics are a better choice to quantify uncertainty.
Generation of Correlated Random Numbers
Correlated random numbers can be obtained by first generating a vector of uncorrelated random numbers and then applying a function on them.
- In order to obtain random numbers with covariance matrix CY, we can use the following know procedure: Calculate the Cholesky decomposition CY = A AT. Generate a vector of uncorrelated random numbers with all var(Xi) = 1. Apply the matrix A: . This will result in correlated random variables with covariance matrix CY = A AT.


- With the formulas outlined in this Wikibook, we can additionally study the shape of the resulting distribution and the effect of non-linear transformations. Consider, e.g., that X is uniform distributed in [0, 2π], Y1 = sin(X) and Y2 = cos(X). In this case, a 2D plot of random numbers from (Y1, Y2) will show a uniform distribution on a circle. Although Y1 and Y2 are stochastically dependent, they are uncorrelated. It is therefore important to know the resulting distribution, because has more information than the covariance matrix CY.
