Shared snapshot objects
In distributed computing, a shared snapshot object is a type of data structure, which is shared between several threads or processes. For many tasks, it is important to have a data structure, that can provide a consistent view of the state of the memory. In practice, it turns out that it is not possible to get such a consistent state of the memory by just accessing one shared register after another, since the values stored in individual registers can be changed at any time during this process. To solve this problem, snapshot objects store a vector of n components and provide the following two atomic operations: update(i,v) changes the value in the ith component to v, and scan() returns the values stored in all n components.[1][2] Snapshot objects can be constructed using atomic single-writer multi-reader shared registers.
In general, one distinguishes between single-writer multi-reader (swmr) snapshot objects and multi-writer multi-reader (mwmr) snapshot objects. In a swmr snapshot object, the number of components matches the number of processes and only one process Pi is allowed to write to the memory position i and all the other processes are allowed to read the memory. In contrast, in a mwmr snapshot object all processes are allowed to write to all positions of the memory and are allowed to read the memory as well.
General
A shared memory is partitioned into multiple parts. Each of these parts holds a single data value. In the single-writer multi-reader case each process Pi has a memory position i assigned and only this process is allowed to write to the memory position. However, every process is allowed to read any position in the memory. In the multi-writer multi-reader case, the restriction changes and any process is allowed to change any position of the memory. Any process Pi {1,...,n} in an n-process system is able to perform two operations on the snapshot object: scan() and update(i,v). The scan operation has no arguments and returns a consistent view of the memory. The update(i,v) operation updates the memory at the position i with the value v.

Both types of operations are considered to occur atomically between the call by the process and the return by the memory. More generally speaking, in the data vector each entry dk corresponds to the argument of the last linearized update operation, which updates part k of the memory.[1]

In order to get the full benefit of shared snapshot objects, in terms of simplifications for validations and constructions, there are two other restrictions added to the construction of snapshot objects.[1] The first restriction is an architectural one, meaning that any snapshot object is constructed only with single-writer multi-reader registers as the basic element. This is possible for single-writer multi-reader snapshots. For multi-writer multi-reader snapshot objects it is possible to use multi-reader multi-writer registers, which can in turn be constructed from single-writer multi-reader registers.[1][3][4]
In distributed computing the construction of a system is driven by the goal, that the whole system is making progress during the execution. Thus, the behaviour of a process should not bring the whole system to a halt (Lock-freedom). The stronger version of this is the property of wait-freedom, meaning that no process can prevent another process from terminating its operation. More generally, this means that every operation has to terminate after a finite number of steps regardless of the behaviour of other processes. A very basic snapshot algorithm guarantees system-wide progress, but is only lock-free. It is easy to extend this algorithm, so that it is wait-free. The algorithm by Afek et al.,[1] which is presented in the section Implementation has this property.
Implementation
Several methods exists to implement shared snapshot objects. The first presented algorithm provides a principal implementation of a snapshot objects. However, this implementation only provides the property of lock-freedom. The second presented implementation proposed by Afek et al.[1] has a stronger property called wait-freedom. An overview of other implementations is given by Fich.[2]
Basic swmr snapshot algorithm
The basic idea of this algorithm is that every process executing the scan() operations, reads all the memory values twice. If the algorithm reads exactly the same memory content twice, no other process changed a value in between and it can return the result. A process, which executes an update(i,v) operation, just update its value in the memory.
function scan()
while true
a[1..n] := collect;
b[1..n] := collect;
if (∀i∈{1, .., n} location i was not changed between the reads of it during the two collects)) then
return b; // double collect successful
loop
end
function update(i, v)
M[i] := v;
end
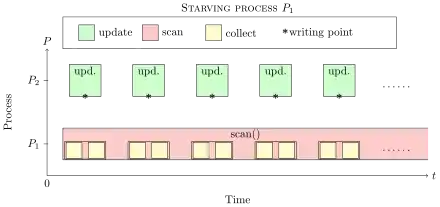
This algorithm provides a very basic implementation of snapshot objects. It guarantees that the system proceeds, while individual threads can starve due to the behaviour of individual processes. A process Pi can prevent another process Pj from terminating a scan() operation by always changing its value, in between the two memory collects. Thus, the algorithm is lock-free, but not wait-free. To hold this stronger the property, no process is allowed to starve due to the behavior of other processes. Figure 1 illustrates the problem. While P1 tries to execute the scan() operation, a second process P2 always disturbs the "double-collect". Thus, the scanning process always has to restart the operation and can never terminates and starves.
Single-Writer Multi-Reader implementation by Afek et al.
The basic idea of the swmr snapshot algorithm by Afek et al. is that a process can detect whether another process changed its memory location and that processes help each other. In order to detect if another process changed its value, a counter is attached to each register and a process increases the counter on every update. The second idea is that, every process who updates its memory position also performs a scan() operation and provides its "view of the memory" in its register to other processes. A scanning process can borrow this scan result and return it.
Based on unbounded memory
Using this idea one can construct a wait-free algorithm that uses registers of unbounded size. A process performing an update operation can help a process to complete the scan. The basic idea is that if a process sees another process updating a memory location twice, that process must have executed a complete, linearized, update operation in between. To implement this, every update operation first performs a scan of the memory and then writes the snapshot value atomically together with the new value v and a sequence number. If a process is performing a scan of the memory and detects that a process updated the memory part twice, it can "borrow" the "embedded" scan of the update to complete the scan operation.[1]
function scan() // returns a consistent view of the memory
for j = 1 to n do moved[j] := 0 end
while true do
a[1..n] := collect; // collects (data, sequence, view) triples
b[1..n] := collect; // collects (data, sequence, view) triples
if (∀j∈{1, ..., n}) (a[j].seq = b[j].seq) then
return (b[1].data, ..., b[n].data) // no process changed memory
else for j = 1 to n do
if a[j].seq ≠ b[j].seq then // process moved
if moved[j] = 1 then // process already moved before
return b[j].view;
else moved[j] := moved[j] + 1;
end
end
end function
procedure update(i,v) // updates the registers with the data-values, updates the sequence number, embedded scan
s[1..n] := scan; // embedded scan
ri := (v, ri.seq = ri.seq + 1, s[1..n]);
end procedure
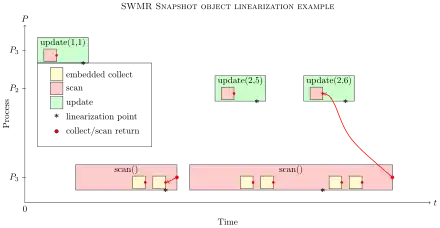
Every register consists of a field for the data-value, the sequence number and a field for the result of the last embedded scan, collected before the last update. In each scan operation the process Pi can decide whether a process changed its memory using the sequence number. If there is no change to the memory during the double collect, Pi can return the result of the second scan. Once the process observes that another process updated the memory in between, it saves this information in the moved field. If a process Pj changed its memory twice during the execution of the scan(), the scanning process Pi can return the embedded scan of the updating process, which it saved in its own register during its update operation.
These operations can be linearized by linearizing each update() operation at its write to the register. The scan operation is more complicated to linearize. If the double collect of the scan operation is successful the scan operation can be linearized at the end of the second scan. In the other case - one process updated its register two times - the operation can be linearized at the time the updating process collected its embedded scan before writing its value to the register.[1]
Based on bounded memory
One of the limitations of the presented algorithm is that it is based on an unbounded memory since the sequence number will increase constantly. To overcome this limitation, it is necessary to introduce a different way to detect whether a process has changed its memory position twice in between. Every pair of processes communicates using two single-writer single-reader (swsr) registers, which contains two atomic bits. Before a process starts to perform a "double collect", it copies the value of its partner process to its own register. If the scanner-process Pi observes after executing the "double-collect" that the value of the partner process Pj has changed in between it indicates that the process has performed an update operation on the memory.[1]

function scan() // returns a consistent view of the memory
for j=1 to n do moved[j] := 0 end
while true do
for j=1 to n do qi,j := rj.pj,i end
a[1..n] := collect; // collects (data, bit-vector, toggle, view) triples
b[1..n] := collect; // collects (data, bit-vector, toggle, view) triples
if (∀j∈{1, ...,n}) (a[j].pj,i = b[j].pj,i = qi,j) and a[j].toggle = b[j].toggle then
return (b[1].data, ..., b[n].data) // no process changed memory
else for j=1 to n do
if (a[j].pj,i ≠ qi,j) or (b[j].pj,i ≠ qi,j) or (a[j].toggle ≠ b[j].toggle) then // process j performed an update
if moved[j] = 2 then // process already moved before
return b[j].view;
else moved[j] := moved[j] + 1;
end
end
end function
procedure update(i,v) // updates the registers with the data-value, "write-state" of all registers, invert the toggle bit and the embedded scan
for j = 1 to n do f[j] := ¬qj,i end
s[1..n] := scan; // embedded scan
ri := (v, f[1..n], ¬ri.toggle, s[1..n]);
end procedure
The unbounded sequence number is replaced by two handshake bits for every pair of processes. These handshake bits are based on swsr registers and can be expressed by a matrix M, where process Pi is allowed to write to row i and is allowed to read the handshake bits in a column i. Before the scanning-process performs the double-collect it collects all the handshake bits from all registers, by reading its column. Afterwards, it can decide whether a process changed its value during the double value or not. Therefore, the process just has to compare the column again with the initially read handshake bits. If only one process Pj has written twice, during the collection of Pi it is possible that the handshake bits do not change during the scan. Thus, it is necessary to introduce another bit called "toggle bit", this bit is changed in every write. This makes it possible to distinguish two consecutive writes, even though no other process updated its register. This approach allows to substitute the unbounded sequence numbers with the handshake bits, without changing anything else in the scan procedure.
While the scanning process Pi uses a handshake bit to detect whether it can use its double collect or not, other processes may also perform update operations. As a first step, they read again the handshake bits provided by the other processes, and generate the complement of them. Afterwards these processes again generate the embedded scan and save the updated data-value, the collected - complemented - handshake bits, the complemented toggle bit and the embedded scan to the register.
Since the handshake bits equivalently replace the sequence numbers, the linearization is the same as in the unbounded memory case.
Multi-Writer Multi-Reader implementation by Afek et al.
The construction of multi-writer multi-reader snapshot object assumes that n processes are allowed to write to any location in the memory, which consists of m registers. So, there is no correlation, between process id and memory location anymore. Therefore, it is not possible anymore to couple the handshake bits or the embedded scan with the data fields. Hence, the handshake bits, the data memory and the embedded scan cannot be stored in the same register and the write to the memory is not an atomic operation anymore.
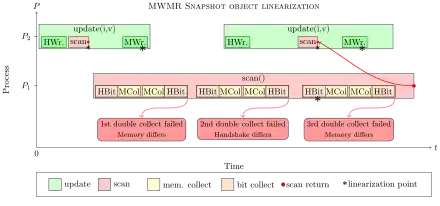
Therefore, the update() process has to update three different registers independently. It first has to save the handshake bits it reads, then do the embedded scan and finally saves its value to the designated memory position. Each write independently appears to be done atomically, but together they are not. The new update() procedure leads to some changes in the scan() function. It is not sufficient anymore to read the handshake bits and collect the memory content twice. In order to detect a beginning update process, a process has to collect the handshake bits a second time, after collecting the memory content.
If a double-collect fails, it is now necessary that a process sees another process moving three times before borrowing the embedded scan. Figure 3 illustrates the problem. The first double-collect fails, because an update process started before the scan operation finishes its memory-write during the first double collect. However, the embedded scan of this write is performed and saved, before P1 starts scanning the memory and therefore no valid Linearization point. The second double-collect fails, because process P2 starts a second write and updated its handshake bits. In the swmr scenario, we would now borrow the embedded scan and return it. In the mwmr scenario, this is not possible because the embedded scan from the second write is still not linearized within the scan-interval (begin and end of operation). Thus, the process has to see a third change from the other process to be entirely sure that at least one embedded scan has been linearized during the scan-interval. After the third change by one process, the scanning process can borrow the old memory value without violating the linearization criterion.
Complexity
The basic presented implementation of shared snapshot objects by Afek et al. needs memory operations.[1] Another implementation by Anderson, which was developed independently, needs an exponential number of operations .[5] There are also randomized implementations of snapshot objects based on swmr registers using operations.[6] Another implementation by Israeli and Shirazi, using unbounded memory, requires operations on the memory.[7][8] Israeli et al. show in a different work the lower bound of low-level operations for any update operation. The lower bound is , where w is the number of updaters and r is the number of scanners. Attiya and Rachman present a deterministic snapshot algorithm based on swmr registers, which uses operations per update and scan.[8] Applying a general method by Israeli, Shaham, and Shirazi [9] this can be improved to an unbounded snapshot algorithm, which only needs operations per scan and operations per update. There are further improvements introduced by Inoue et al.,[10] using only a linear number of read and write operations. In contrast to the other presented methods, this approach uses mwmr registers and not swmr registers.







Applications
There are several algorithms in distributed computing which can be simplified in design and/or verification using shared snapshot objects.[1] Examples of this are exclusion problems,[11][12][13] concurrent time-stamp systems,[14] approximate agreement,[15] randomized consensus[16][17] and wait-free implementations of other data structures.[18] With mwmr snapshot objects it is also possible to create atomic multi-writer multi-reader registers.
See also
References
- Afek, Yehuda; Attiya, Hagit; Dolev, Danny; Gafni, Eli; Merritt, Michael; Shavit, Nir (Sep 1993). "Atomic Snapshots of Shared Memory". J. ACM. 40 (4): 873–890. doi:10.1145/153724.153741. S2CID 52150066.
- Fich, Faith Ellen (2005). "How Hard is It to Take a Snapshot?". SOFSEM 2005: Theory and Practice of Computer Science. Lecture Notes in Computer Science. Vol. 3381 (SOFSEM 2005: Theory and Practice of Computer Science ed.). Springer Berlin Heidelberg. pp. 28–37. doi:10.1007/978-3-540-30577-4_3. ISBN 978-3-540-24302-1.
- Li, Ming; Tromp, John; Vitanyi, Paul M. B. (July 1996). "How to Share Concurrent Wait-free Variables". J. ACM. 43 (4): 723–746. CiteSeerX 10.1.1.56.3236. doi:10.1145/234533.234556. S2CID 15035117.
- Peterson, Gary L; Burns, James E. (1987). "Concurrent reading while writing ii: the multi-writer case". Foundations of Computer Science, 1987., 28th Annual Symposium on. pp. 383–392.
- Anderson, James H (1993). "Composite registers". Distributed Computing. 6 (3): 141–154. doi:10.1007/BF02242703. S2CID 1688458.
- Attiya, Hagit; Helihy, Maurice; Rachman, Ophir (1995). "Atomic snapshots using lattice agreement". Distributed Computing. 8 (3): 121–132. doi:10.1007/BF02242714. S2CID 26538026.
- Israeli, Amos; Shirazi, Asaf (1992). "Efficient snapshot protocol using 2-lattice agreement". Manuscript.
- Attiya, Hagit; Rachman, Ophir (April 1998). "Atomic Snapshots in O( n log n ) Operations". SIAM Journal on Computing. 27 (2): 319–340. doi:10.1145/164051.164055. S2CID 15199715.
- Israeli, Amos; Shaham, Amnon; Shirazi, Asaf (1993). "Linear-time snapshot protocols for unbalanced systems". Distributed Algorithms. Springer. pp. 26–38. doi:10.1007/3-540-57271-6_25. ISBN 978-3-540-57271-8.
- Inoue, Michiko; Masuzawa, Toshimitsu; Chen, Wei; Tokura, Nobuki (1994). Linear-time snapshot using multi-writer multi-reader registers. pp. 130–140. doi:10.1007/BFb0020429. ISBN 978-3-540-58449-0.
{{cite book}}:|work=ignored (help) - Dolev, Danny; Gafni, Eli; Shavit, Nir (1988). "Toward a non-atomic era: l-exclusion as a test case". Proceedings of the twentieth annual ACM symposium on Theory of computing. pp. 78–92.
- Katseff, Howard P (1978). "A new solution to the critical section problem". Proceedings of the tenth annual ACM symposium on Theory of computing. pp. 86–88.
- Lamport, Leslie (1988). "The mutual exclusion problem: partII—statement and solutions". Journal of the ACM. 33 (2): 327–348. CiteSeerX 10.1.1.32.9808. doi:10.1145/5383.5385. S2CID 7387839.
- Dolev, Danny; Shavit, Nir (1989). "Bounded concurrrent time-stamp systems are constructible". Proceedings of the twenty-first annual ACM symposium on Theory of computing. ACM. pp. 454–466.
- Attiya, Hagit; Lynch, Nancy; Shavit, Nir (1990). "Are wait-free algorithms fast?". Foundations of Computer Science, 1990. Proceedings., 31st Annual Symposium on. pp. 55–64.
- Abrahamson, Karl (1988). "On achieving consensus using a shared memory". Proceedings of the seventh annual ACM Symposium on Principles of distributed computing. pp. 291–302.
- Attiya, Hagit; Dolev, Danny; Shavit, Nir (1989). Bounded polynomial randomized consensus. pp. 281–293.
{{cite book}}:|work=ignored (help) - Aspnes, James; Herlihy, Maurice (1990). "Wait-free data structures in the asynchronous PRAM model". Proceedings of the second annual ACM symposium on Parallel algorithms and architectures. ACM. pp. 340–349.