Segmental duplication on the human Y chromosome
Segmental duplication are blocks of DNA ranging from 1 to 400 kb in length which recur at multiple sites within the genome, sharing greater than 90% similarity.[1] Multiple studies have found a correlation between the location of segmental duplications and regions of chromosomal instability. This correlation suggests that they may be mediators of some genomic disorders. Segmental duplications are shown to be flanked on both sides by large homologous repeats, which exposes the region to recurrent rearrangement by nonallelic homologous recombination, leading to either deletion, duplication, or inversion of the original sequence.[1]
Background
Finding segmental duplications
Cataloging of segmental duplications was originally difficult due to its inconspicuousness, large size, and high degree of sequence similarity. This led to issues of interpreting separate loci as one sequence as these duplications are over-represented in unordered and unassigned contigs. Furthermore, these duplications are more prevalent within the pericentromeric and subtelomeric regions. BACs containing intrachromosomal duplications can be made and their duplication pattern can be characterized using FISH. Comparison can be made between chromosomes that were positive by FISH and the chromosomal position using BLAST.[2] Scientist have attempted to map the location of these segmental duplications, but they run into issues of accurate sequencing within these duplication regions. Because of this, scientists share the sentiment that accurate human genome assembly is difficult due to these segmental duplications.[2]
Genomic instability
Regions of the genome which are flanked by repeats represent potential hotspots of genomic instability that are prone to copy-number variation. It has been shown that the larger and more homologous duplicated sequences lead to more sporadic segmental aneusomy events. The human genome contains around 130 regions, totaling 274Mb and ten percent of the total genome, that are flanked by these intrachromosomal duplications. Scientists have currently identified twenty-five of these regions to be directly associated with some form of genetic disorder.[1] Further research identified fifty-one regions displaying genomic instability in the form of copy-number polymorphisms. It was also observed that these CNPs are prevalent across different ethnic groups as well. This allows for two important claims to be made. Firstly, it is possible that the structural rearrangements are evolutionarily ancient and occurred prior to separation of ethnic groups. Secondly, it may also be possible that they have independently occurred within each ethnic group. Research has also found an increase of segmental duplications within regions of the CNPs showing that the duplications are responsible for the variation in copy number. Hypotheses have been made suggesting that many CNPs are only prevalent within the human genome because of the absence or presence of the evolutionarily recent segmental duplication events that have not quite become fixed within the human population.[1] This shows that segmental duplications are responsible for defining locations of chromosomal rearrangement within the human genome. Segmental duplications are also often themselves variant in copy number.
Primate segmental duplications
Most human segmental duplications are less than 300 kb in length, whereas research has begun to show that other primates, such as the chimpanzee, contain more duplications. There is a difference in copy number and content for about a third of the duplications with at least 94% shared identity. However, when the levels of segmental duplication in primates are compared with other mammals, we see that primates on average contain more than the rest of the mammalian world.[3]
Segmental duplications have been hypothesized to be evolutionarily significant. From this, it has been observed that new-lineage segmental duplications map near shared ancestral duplications when comparing the human and chimpanzee. This phenomenon is known as duplication shadowing and it suggests that unique regions flanking duplications are about ten times as likely to become duplicated as other randomly duplicated regions. One distinguishing factor of primate genomes from other mammalian genomes is the abundance of interchromosomal and interspersed interchromosomal duplications. 48% of human duplications can be termed as interchromosomal, versus 13% in mice.[3]
Segmental duplications found in primate genomes fall under one of three classifications. These are the pericentromeric, subtelomeric, and interstitial regions. Segmental duplications in pericentromeric regions are unique in that around 30% of their sequence can be traced to duplications occurring from other chromosomes. The number of segmental duplications in pericentromeric regions is highly variable, having as few as zero. Twenty-nine of the forty-three pericentromeric regions have some form of segmental duplication totaling 47.6Mb, which is almost a third of all segmental duplications found in the human genome. Segmental duplication in subtelomeric regions are similar to those pericentromeric in that they are enriched in interchromosomal segmental duplications. Thirty of the forty-two subtelomeric regions contain segmental duplications. However, these total only 2.6Mb. It is not known whether the duplications of the subtelomeric regions arise from other chromosomes as with the pericentromeric regions. Interstitial region segmental duplications are distributed on the euchromatin between the pericentromeric and subtelomeric regions. They account for the most of the interchromosomal duplications. Interstitial duplications make up most of the largest and highest-identity human segmental duplications as compared to interchromosomal duplications.[3]
Following formation of segmental duplications, forces of evolution such as base-pair substitutions, insertions, deletions, and retrotransposition are all possible. It has been suggested that segmental duplications undergo homology-driven mutations. There are two main homology-driven processes that lead to structural alterations. Homology between segmental duplications can initiate NAHR, which occurs from the alignment of highly similar segmental duplications that are followed by paralogous recombination, or through the non-reciprocal transfer of sequence from one segmental duplication copy to another. This is referred to as gene conversion, which can be detected using newly created computational algorithms.[3]
Role in evolution
Segmental duplications are also important for their role in the evolution of new genes as it is one of the primary mechanisms by which new genes are created. The most common method by which segmental duplication operates in creating new genes is by duplication of the entire gene, whether it is in tandem or in an interspersed configuration. Using whole-genome shotgun sequencing, it has been found that gene density is the greatest factor in showing correlation with segmental duplication density.[3] However, this does not mean that all segmental duplications are enriched for genes and that all duplication regions are sites for the formation of new genes. Rather, it has been seen that segmental duplications which contain interstitial interchromosomal duplications are regions with the most enrichment of genes. Comparing the subtelomeric and pericentromeric regions, it is seen that the subtelomeric regions contains more gene content and transcriptional activity. Genes found within segmental duplications also share properties. Firstly, strong signatures of positive selection are common in segmentally duplicated genes. Secondly, these genes are five to ten times more likely than their counterparts to show interspecies and intraspecies structural and copy-number variation. Finally, immune response and xenobiotic recognition are some functions that are enriched within these genes. Together, this suggests an important role for segmental duplication within human and primate adaptive evolution.[3]
This has a great effect in humans as polymorphic insertions, inversions, and deletions are found with greater frequency near sites of segmental duplications. Similarly observed in chimpanzees, this suggests that duplicated regions are continuing to rearrange and evolve in contemporary primate populations.[3] Recent research also suggests that segmental duplications and structural variation also have protective and beneficial effects. A 900kb inversion polymorphism, which is mediated by segmental duplication, is associated with positive selection for increased fertility for the Icelandic population. Additionally, an increased copy number of CCL3L1 due to duplication is associated with decreased susceptibility to the HIV infection.[3]
Human Y Chromosome
The human Y chromosome contains the greatest proportion of duplicated sequence within the human genome at 50.4%.[3] The majority of the chromosome (41Mb out of 63Mb) is made up of three blocks of highly reiterated satellites and other repeats. The other 22Mb euchromatin region also has a unique genetic structure with large gene-rich palindromes.[4]
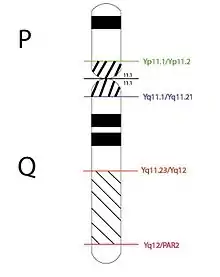
Difficulty in mapping pericentromeric regions
On the human Y chromosome as well as other primate Y chromosomes, the pericentromeric and subtelomeric regions are the most important. The pericentromeric region is the area around the centromere of the chromosome. However, there exist issues in mapping of these pericentromeric issues. Primarily, pericentromeric regions exhibit a high degree of similarity (>98%). From this, it becomes increasingly difficult to disassemble sequence contigs using whole genome shotgun approaches. To solve this issue, a new technique was developed to allow for facilitation of mapping of pericentromeric regions. The key breakthrough was that this new methodology allowed for the detection of these overlaps. This was accomplished by using a transchromosomal assay rather than a cis-based approach for detection. This new method has allowed for the detection of BAC clones as well as the previously difficult to determine heterochromatin parts of the pericentromeric regions.[5] This allows for closer study of these regions.
Pericentromeric region in Yq11
The pericentromeric region on the Y chromosome is a 450kb euchromatin island between the satellite three sequence and the long arm of the chromosome. Whole genome assembly comparison experiments revealed that 80.2% of the pericentromeric sequence of the Y chromosome is composed of segmental duplications with 73.8% and 5.3% of the DNA duplicated interchromosomally and intrachromosomally respectively. It is estimated that it has a recent origin to within the last thirty million year of primate evolution.[4] Further FISH testing confirms that the segment is highly duplicated and that the majority of the signals is located near the centromeric region of the chromosome.[4][6] In addition, the pericentromeric Yq11 region shares long stretches of sequence with chromosomes 1, 2, 3, 10, 16, and 22. For this same region, thirty-six modules are distributed interchromosomally while only one module is distributed intrachromosomally. There are twenty genes segments on the Yq11 region and thirteen of them are believed to not be functional genes. Eight of these gene segments display features of degenerated processed pseudogenes while five of them display partial exon-intron structure.[4]
Multi-copy ampliconic genes on msrY
The msrY is the male-specific region of the Y chromosome in marsupial and placental mammals. On this Y chromosome, ampliconic genes are present in multiple copies. This group of genes undergo gene conversion. The ampliconic genes evolve faster than their autosomal counterparts. In fact, they even evolve faster than single-copy genes located on the Y chromosome. Finally, these ampliconic genes evolve faster in modern human and chimpanzees as compared to the Old World monkeys of the past.[7]
Evolutionary dynamics of segmental duplication
The male-specific region of the Y chromosome contains a mosaic of heterochromatic sequences. It is also made up of three classes of euchromatic sequence, which are the ampliconic genes, X-transposed, and X-degenerate. It has also been shown that an additional euchromatic sequence exists for the Yq11 region of the Y chromosome. These regions are all primarily interchromosomal. There are also three additional euchromatin/heterochromatin transition regions for a total of four on the Y chromosome. Together, these are Yp11.2/Yp11.1, Yq11.1/Yq11.21, Yq11.23/Yq12, and Yq12/PAR2. Of these four regions, the Yq11.23/Yq12 region is unique in its structure as it is composed of recurrent TPTE and SLC25A15 duplicons which have originated from different long arms regions of chromosome 13. Furthermore, the Yp11.2/Yp11.1 and Yq11.1/Yq11.21 regions contain the more ancient duplications and are predominantly located in the subtelomeric regions. Nowadays, these duplications prefer to map to the pericentromeric regions in the modern human and chimpanzee. There has been a shift from the subtelomeric regions of the Old World monkeys to the pericentromeric regions of the modern primate. This evolutionary change coincides with the shortening of the subtelomeric regions as well as the development of higher-order alpha-satellites.[8]
Yp11.2/Yp11.1 transition region
This is the only region which does not show any homologies to segmental duplication of other chromosomes with more than 95% sequence identity. Lowering the stringency conditions, homologues can be ascertained with chromosomes 1, 2, 3, 4, 8, 9, 10, 16, and 18. There exist three copies of this human region on the chimpanzee Y chromosome with two surrounding the Y chromosome centromere and the third located at Yp11.2. Both the human region and the homologous chimpanzee region are encompassed by typical alpha-satellite DNA found near the chromosome centromeres. The first duplicative transposition occurred about 1.2mya with a second larger genomic sequence invert occurring 880,000ya.[8]
Yq11.1/Yq11.21 transition region
The chimpanzee Y chromosome completely spans the orthologous part of the human region, and the human region is completely included in the orthologous chimpanzee region. The segmental duplications are primarily consistent between the two genomes with the exception of chromosomes 1, 11, and 14 unable to be located on the chimpanzee genome.[8]
Yq11.23/Yq12 and Yq12/PAR2 transition regions
When looking at the Yq11.23/Yq12 region, many segmental duplications can be found on both the human and chimpanzee chromosomes with the exception of a couple giving a 93% matching rate. However, orthologous sequences were unable to be detected for the Yq12/PAR2 transition region. It has been shown that segmental duplications from the Yq11.1/Yq11.21, Yq11.23/Yq12, and Yq12/PAR2 transition regions shows a predisposition to accumulate in the pericentromeric regions of both the human and chimpanzee genome.[8]
Non-human primate interchromosomal segmental duplication
Analysis of the Sumatran orangutan, white-tufted ear marmoset, greater bushbaby, and grey mouse lemur yielded the discovery of eight new duplicons, which correspond to more ancient duplication events. Furthermore, this shows that these duplicons have diverged more than the other mammalian species. In addition, four mutated retrotransposon insertions were shown to have simulated the entire existence of additional ancestral duplicons illustrating the need for sequencing of the euchromatin/heterochromatin transition regions for these mammals.[9]
References
- Sharp, Andrew J. et al. (2005). Segmental Duplications and Copy-Number Variation in the Human Genome. American Journal of Human Genetics, 77(1), 78–88.
- Bailey, Jeffrey A. et al. (2001). Segmental Duplications: Organization and Impact Within the Current Human Genome Project Assembly. Genome Research, 11(6), 1005–1017.
- Bailey JA, Eichler EE. (2006). Primate segmental duplications: crucibles of evolution, diversity and disease. Nat Rev Genet 7:552–564.
- Kirsch, Stefan. et al. (2005). Interchromosomal segmental duplications of the pericentromeric region on the human Y chromosome. Genome Research,15(2), 195–204.
- Horvath, Juliann E. et al. (2000). The Mosaic Structure of Human Pericentromeric DNA: A Strategy for Characterizing Complex Regions of the Human Genome. Genome Research, 10(6), 839–852.
- Wiland, Ewa. et al. (2015). FISH and array CGH characterization of de novoderivative Y chromosome (Yq duplication and partial Yp deletion) in an azoospermic male. Reproductive Biomedicine Online, 31(2), 217–224.
- Ghenu, Ana-Hermina. et al. (2016) Multicopy gene family evolution on primate Y chromosomes. BMC Genomics, 17, 157
- Kirsch, Stefan. et al. (2008). Evolutionary dynamics of segmental duplications from human Y-chromosomal euchromatin/heterochromatin transition regions. Genome Research, 18(7), 1030–1042.
- Kirsch Stefan. et al. (2009). Non-Human Primate BAC Resource to Study Interchromosomal Segmental Duplications. Cytogenet Genome Res 125:253-259