Randomized algorithm
A randomized algorithm is an algorithm that employs a degree of randomness as part of its logic or procedure. The algorithm typically uses uniformly random bits as an auxiliary input to guide its behavior, in the hope of achieving good performance in the "average case" over all possible choices of random determined by the random bits; thus either the running time, or the output (or both) are random variables.
| Part of a series on |
| Probabilistic data structures |
|---|
| Random trees |
| Related |
One has to distinguish between algorithms that use the random input so that they always terminate with the correct answer, but where the expected running time is finite (Las Vegas algorithms, for example Quicksort[1]), and algorithms which have a chance of producing an incorrect result (Monte Carlo algorithms, for example the Monte Carlo algorithm for the MFAS problem[2]) or fail to produce a result either by signaling a failure or failing to terminate. In some cases, probabilistic algorithms are the only practical means of solving a problem.[3]
In common practice, randomized algorithms are approximated using a pseudorandom number generator in place of a true source of random bits; such an implementation may deviate from the expected theoretical behavior and mathematical guarantees which may depend on the existence of an ideal true random number generator.
Motivation
As a motivating example, consider the problem of finding an ‘a’ in an array of n elements.
Input: An array of n≥2 elements, in which half are ‘a’s and the other half are ‘b’s.
Output: Find an ‘a’ in the array.
We give two versions of the algorithm, one Las Vegas algorithm and one Monte Carlo algorithm.
Las Vegas algorithm:
findingA_LV(array A, n)
begin
repeat
Randomly select one element out of n elements.
until 'a' is found
end
This algorithm succeeds with probability 1. The number of iterations varies and can be arbitrarily large, but the expected number of iterations is

Since it is constant, the expected run time over many calls is . (See Big Theta notation)

Monte Carlo algorithm:
findingA_MC(array A, n, k)
begin
i := 0
repeat
Randomly select one element out of n elements.
i := i + 1
until i = k or 'a' is found
end
If an ‘a’ is found, the algorithm succeeds, else the algorithm fails. After k iterations, the probability of finding an ‘a’ is:
![{\displaystyle \Pr[\mathrm {find~a} ]=1-(1/2)^{k}}](../I/2c3fa724b0da3c3ac125350c4d0703329e0eabbc.svg)
This algorithm does not guarantee success, but the run time is bounded. The number of iterations is always less than or equal to k. Taking k to be constant the run time (expected and absolute) is .
Randomized algorithms are particularly useful when faced with a malicious "adversary" or attacker who deliberately tries to feed a bad input to the algorithm (see worst-case complexity and competitive analysis (online algorithm)) such as in the Prisoner's dilemma. It is for this reason that randomness is ubiquitous in cryptography. In cryptographic applications, pseudo-random numbers cannot be used, since the adversary can predict them, making the algorithm effectively deterministic. Therefore, either a source of truly random numbers or a cryptographically secure pseudo-random number generator is required. Another area in which randomness is inherent is quantum computing.
In the example above, the Las Vegas algorithm always outputs the correct answer, but its running time is a random variable. The Monte Carlo algorithm (related to the Monte Carlo method for simulation) is guaranteed to complete in an amount of time that can be bounded by a function the input size and its parameter k, but allows a small probability of error. Observe that any Las Vegas algorithm can be converted into a Monte Carlo algorithm (via Markov's inequality), by having it output an arbitrary, possibly incorrect answer if it fails to complete within a specified time. Conversely, if an efficient verification procedure exists to check whether an answer is correct, then a Monte Carlo algorithm can be converted into a Las Vegas algorithm by running the Monte Carlo algorithm repeatedly till a correct answer is obtained.
Computational complexity
Computational complexity theory models randomized algorithms as probabilistic Turing machines. Both Las Vegas and Monte Carlo algorithms are considered, and several complexity classes are studied. The most basic randomized complexity class is RP, which is the class of decision problems for which there is an efficient (polynomial time) randomized algorithm (or probabilistic Turing machine) which recognizes NO-instances with absolute certainty and recognizes YES-instances with a probability of at least 1/2. The complement class for RP is co-RP. Problem classes having (possibly nonterminating) algorithms with polynomial time average case running time whose output is always correct are said to be in ZPP.
The class of problems for which both YES and NO-instances are allowed to be identified with some error is called BPP. This class acts as the randomized equivalent of P, i.e. BPP represents the class of efficient randomized algorithms.
Early history
Sorting
Quicksort was discovered by Tony Hoare in 1959, and subsequently published in 1961.[4] In the same year, Hoare published the quickselect algorithm,[5] which finds the median element of a list in linear expected time. It remained open until 1973 whether a deterministic linear-time algorithm existed.[6]
Number Theory
In 1917, Henry Cabourn Pocklington introduced a randomized algorithm known as Pocklington's algorithm for efficiently finding square roots modulo prime numbers.[7] In 1970, Elwyn Berlekamp introduced a randomized algorithm for efficiently computing the roots of a polynomial over a finite field.[8] In 1977, Robert M. Solovay and Volker Strassen discovered a polynomial-time randomized primality test (i.e., determining the primality of a number). Soon afterwards Michael O. Rabin demonstrated that the 1976 Miller's primality test could also be turned into a polynomial-time randomized algorithm. At that time, no provably polynomial-time deterministic algorithms for primality testing were known.
Data Structures
One of the earliest randomized data structures is the hash table, which was introduced in 1953 by Hans Peter Luhn at IBM.[9] Luhn's hash table used chaining to resolve collisions and was also one of the first applications of linked lists.[9] Subsequently, in 1954, Gene Amdahl, Elaine M. McGraw, Nathaniel Rochester, and Arthur Samuel of IBM Research introduced linear probing,[9] although Andrey Ershov independently had the same idea in 1957.[9] In 1962, Donald Knuth performed the first correct analysis of linear probing,[9] although the memorandum containing his analysis was not published until much later.[10] The first published analysis was due to Konheim and Weiss in 1966.[11]
Early works on hash tables either assumed access to a fully random hash function or assumed that the keys themselves were random.[9] In 1979, Carter and Wegman introduced universal hash functions,[12] which they showed could be used to implement chained hash tables with constant expected time per operation.
Early work on randomized data structures also extended beyond hash tables. In 1970, Burton Howard Bloom introduced an approximate-membership data structure known as the Bloom filter.[13] In 1989, Raimund Seidel and Cecilia R. Aragon introduced a randomized balanced search tree known as the treap.[14] In the same year, William Pugh introduced another randomized search tree known as the skip list.[15]
Implicit Uses in Combinatorics
Prior to the popularization of randomized algorithms in computer science, Paul Erdős popularized the use of randomized constructions as a mathematical technique for establishing the existence of mathematical objects. This technique has become known as the probabilistic method.[16] Erdős gave his first application of the probabilistic method in 1947, when he used a simple randomized construction to establish the existence of Ramsey graphs.[17] He famously used a much more sophisticated randomized algorithm in 1959 to establish the existence of graphs with high girth and chromatic number.[18][16]
Examples
Quicksort
Quicksort is a familiar, commonly used algorithm in which randomness can be useful. Many deterministic versions of this algorithm require O(n2) time to sort n numbers for some well-defined class of degenerate inputs (such as an already sorted array), with the specific class of inputs that generate this behavior defined by the protocol for pivot selection. However, if the algorithm selects pivot elements uniformly at random, it has a provably high probability of finishing in O(n log n) time regardless of the characteristics of the input.
Randomized incremental constructions in geometry
In computational geometry, a standard technique to build a structure like a convex hull or Delaunay triangulation is to randomly permute the input points and then insert them one by one into the existing structure. The randomization ensures that the expected number of changes to the structure caused by an insertion is small, and so the expected running time of the algorithm can be bounded from above. This technique is known as randomized incremental construction.[19]
Min cut
Input: A graph G(V,E)
Output: A cut partitioning the vertices into L and R, with the minimum number of edges between L and R.
Recall that the contraction of two nodes, u and v, in a (multi-)graph yields a new node u ' with edges that are the union of the edges incident on either u or v, except from any edge(s) connecting u and v. Figure 1 gives an example of contraction of vertex A and B. After contraction, the resulting graph may have parallel edges, but contains no self loops.
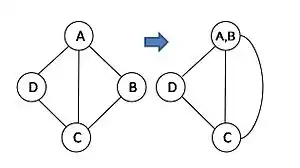
Karger's[20] basic algorithm:
begin
i = 1
repeat
repeat
Take a random edge (u,v) ∈ E in G
replace u and v with the contraction u'
until only 2 nodes remain
obtain the corresponding cut result Ci
i = i + 1
until i = m
output the minimum cut among C1, C2, ..., Cm.
end
In each execution of the outer loop, the algorithm repeats the inner loop until only 2 nodes remain, the corresponding cut is obtained. The run time of one execution is , and n denotes the number of vertices. After m times executions of the outer loop, we output the minimum cut among all the results. The figure 2 gives an example of one execution of the algorithm. After execution, we get a cut of size 3.

Lemma 1 — Let k be the min cut size, and let C = {e1, e2, ..., ek} be the min cut. If, during iteration i, no edge e ∈ C is selected for contraction, then Ci = C.
If G is not connected, then G can be partitioned into L and R without any edge between them. So the min cut in a disconnected graph is 0. Now, assume G is connected. Let V=L∪R be the partition of V induced by C : C = { {u,v} ∈ E : u ∈ L,v ∈ R} (well-defined since G is connected). Consider an edge {u,v} of C. Initially, u,v are distinct vertices. As long as we pick an edge , u and v do not get merged. Thus, at the end of the algorithm, we have two compound nodes covering the entire graph, one consisting of the vertices of L and the other consisting of the vertices of R. As in figure 2, the size of min cut is 1, and C = {(A,B)}. If we don't select (A,B) for contraction, we can get the min cut.

Lemma 2 — If G is a multigraph with p vertices and whose min cut has size k, then G has at least pk/2 edges.
Because the min cut is k, every vertex v must satisfy degree(v) ≥ k. Therefore, the sum of the degree is at least pk. But it is well known that the sum of vertex degrees equals 2|E|. The lemma follows.
Analysis of algorithm
The probability that the algorithm succeeds is 1 − the probability that all attempts fail. By independence, the probability that all attempts fail is

By lemma 1, the probability that Ci = C is the probability that no edge of C is selected during iteration i. Consider the inner loop and let Gj denote the graph after j edge contractions, where j ∈ {0, 1, …, n − 3}. Gj has n − j vertices. We use the chain rule of conditional possibilities. The probability that the edge chosen at iteration j is not in C, given that no edge of C has been chosen before, is . Note that Gj still has min cut of size k, so by Lemma 2, it still has at least edges.


Thus, .

So by the chain rule, the probability of finding the min cut C is
![{\displaystyle \Pr[C_{i}=C]\geq \left({\frac {n-2}{n}}\right)\left({\frac {n-3}{n-1}}\right)\left({\frac {n-4}{n-2}}\right)\ldots \left({\frac {3}{5}}\right)\left({\frac {2}{4}}\right)\left({\frac {1}{3}}\right).}](../I/327acc4529b1f6daba99ac1e9938a7917f2bec82.svg)
Cancellation gives . Thus the probability that the algorithm succeeds is at least . For , this is equivalent to . The algorithm finds the min cut with probability , in time .
![{\displaystyle \Pr[C_{i}=C]\geq {\frac {2}{n(n-1)}}}](../I/f9a5ee0a8aef637a2522ae343d168d48bb739389.svg)




Derandomization
Randomness can be viewed as a resource, like space and time. Derandomization is then the process of removing randomness (or using as little of it as possible). It is not currently known if all algorithms can be derandomized without significantly increasing their running time. For instance, in computational complexity, it is unknown whether P = BPP, i.e., we do not know whether we can take an arbitrary randomized algorithm that runs in polynomial time with a small error probability and derandomize it to run in polynomial time without using randomness.
There are specific methods that can be employed to derandomize particular randomized algorithms:
- the method of conditional probabilities, and its generalization, pessimistic estimators
- discrepancy theory (which is used to derandomize geometric algorithms)
- the exploitation of limited independence in the random variables used by the algorithm, such as the pairwise independence used in universal hashing
- the use of expander graphs (or dispersers in general) to amplify a limited amount of initial randomness (this last approach is also referred to as generating pseudorandom bits from a random source, and leads to the related topic of pseudorandomness)
- changing the randomized algorithm to use a hash function as a source of randomness for the algorithm's tasks, and then derandomizing the algorithm by brute-forcing all possible parameters (seeds) of the hash function. This technique is usually used to exhaustively search a sample space and making the algorithm deterministic (e.g. randomized graph algorithms)
Where randomness helps
When the model of computation is restricted to Turing machines, it is currently an open question whether the ability to make random choices allows some problems to be solved in polynomial time that cannot be solved in polynomial time without this ability; this is the question of whether P = BPP. However, in other contexts, there are specific examples of problems where randomization yields strict improvements.
- Based on the initial motivating example: given an exponentially long string of 2k characters, half a's and half b's, a random-access machine requires 2k−1 lookups in the worst-case to find the index of an a; if it is permitted to make random choices, it can solve this problem in an expected polynomial number of lookups.
- The natural way of carrying out a numerical computation in embedded systems or cyber-physical systems is to provide a result that approximates the correct one with high probability (or Probably Approximately Correct Computation (PACC)). The hard problem associated with the evaluation of the discrepancy loss between the approximated and the correct computation can be effectively addressed by resorting to randomization[21]
- In communication complexity, the equality of two strings can be verified to some reliability using bits of communication with a randomized protocol. Any deterministic protocol requires bits if defending against a strong opponent.[22]
- The volume of a convex body can be estimated by a randomized algorithm to arbitrary precision in polynomial time.[23] Bárány and Füredi showed that no deterministic algorithm can do the same.[24] This is true unconditionally, i.e. without relying on any complexity-theoretic assumptions, assuming the convex body can be queried only as a black box.
- A more complexity-theoretic example of a place where randomness appears to help is the class IP. IP consists of all languages that can be accepted (with high probability) by a polynomially long interaction between an all-powerful prover and a verifier that implements a BPP algorithm. IP = PSPACE.[25] However, if it is required that the verifier be deterministic, then IP = NP.
- In a chemical reaction network (a finite set of reactions like A+B → 2C + D operating on a finite number of molecules), the ability to ever reach a given target state from an initial state is decidable, while even approximating the probability of ever reaching a given target state (using the standard concentration-based probability for which reaction will occur next) is undecidable. More specifically, a limited Turing machine can be simulated with arbitrarily high probability of running correctly for all time, only if a random chemical reaction network is used. With a simple nondeterministic chemical reaction network (any possible reaction can happen next), the computational power is limited to primitive recursive functions.[26]


See also
Notes
- Hoare, C. A. R. (July 1961). "Algorithm 64: Quicksort". Commun. ACM. 4 (7): 321–. doi:10.1145/366622.366644. ISSN 0001-0782.
- Kudelić, Robert (2016-04-01). "Monte-Carlo randomized algorithm for minimal feedback arc set problem". Applied Soft Computing. 41: 235–246. doi:10.1016/j.asoc.2015.12.018.
- "In testing primality of very large numbers chosen at random, the chance of stumbling upon a value that fools the Fermat test is less than the chance that cosmic radiation will cause the computer to make an error in carrying out a 'correct' algorithm. Considering an algorithm to be inadequate for the first reason but not for the second illustrates the difference between mathematics and engineering." Hal Abelson and Gerald J. Sussman (1996). Structure and Interpretation of Computer Programs. MIT Press, section 1.2.
- Hoare, C. A. R. (July 1961). "Algorithm 64: Quicksort". Communications of the ACM. 4 (7): 321. doi:10.1145/366622.366644. ISSN 0001-0782.
- Hoare, C. A. R. (July 1961). "Algorithm 65: find". Communications of the ACM. 4 (7): 321–322. doi:10.1145/366622.366647. ISSN 0001-0782.
- Blum, Manuel; Floyd, Robert W.; Pratt, Vaughan; Rivest, Ronald L.; Tarjan, Robert E. (August 1973). "Time bounds for selection". Journal of Computer and System Sciences. 7 (4): 448–461. doi:10.1016/S0022-0000(73)80033-9.
- Williams, H. C.; Shallit, J. O. (1994), "Factoring integers before computers", in Gautschi, Walter (ed.), Mathematics of Computation 1943–1993: a half-century of computational mathematics; Papers from the Symposium on Numerical Analysis and the Minisymposium on Computational Number Theory held in Vancouver, British Columbia, August 9–13, 1993, Proceedings of Symposia in Applied Mathematics, vol. 48, Amer. Math. Soc., Providence, RI, pp. 481–531, doi:10.1090/psapm/048/1314885, MR 1314885; see p. 504, "Perhaps Pocklington also deserves credit as the inventor of the randomized algorithm".
- Berlekamp, E. R. (1971). "Factoring polynomials over large finite fields". Proceedings of the second ACM symposium on Symbolic and algebraic manipulation - SYMSAC '71. Los Angeles, California, United States: ACM Press. p. 223. doi:10.1145/800204.806290. ISBN 9781450377867. S2CID 6464612.
- Knuth, Donald E. (1998). The art of computer programming, volume 3: (2nd ed.) sorting and searching. USA: Addison Wesley Longman Publishing Co., Inc. pp. 536–549. ISBN 978-0-201-89685-5.
- Knuth, Donald (1963), Notes on "Open" Addressing, archived from the original on 2016-03-03
- Konheim, Alan G.; Weiss, Benjamin (November 1966). "An Occupancy Discipline and Applications". SIAM Journal on Applied Mathematics. 14 (6): 1266–1274. doi:10.1137/0114101. ISSN 0036-1399.
- Carter, J. Lawrence; Wegman, Mark N. (1979-04-01). "Universal classes of hash functions". Journal of Computer and System Sciences. 18 (2): 143–154. doi:10.1016/0022-0000(79)90044-8. ISSN 0022-0000.
- Bloom, Burton H. (July 1970). "Space/time trade-offs in hash coding with allowable errors". Communications of the ACM. 13 (7): 422–426. doi:10.1145/362686.362692. ISSN 0001-0782. S2CID 7931252.
- Aragon, C.R.; Seidel, R.G. (October 1989). "Randomized search trees". 30th Annual Symposium on Foundations of Computer Science. pp. 540–545. doi:10.1109/SFCS.1989.63531. ISBN 0-8186-1982-1.
- Pugh, William (April 1989). Concurrent Maintenance of Skip Lists (PS, PDF) (Technical report). Dept. of Computer Science, U. Maryland. CS-TR-2222.
- Alon, Noga (2016). The probabilistic method. Joel H. Spencer (Fourth ed.). Hoboken, New Jersey. ISBN 978-1-119-06195-3. OCLC 910535517.
{{cite book}}: CS1 maint: location missing publisher (link) - P. Erdős: Some remarks on the theory of graphs, Bull. Amer. Math. Soc. 53 (1947), 292--294 MR8,479d; Zentralblatt 32,192.
- Erdös, P. (1959). "Graph Theory and Probability". Canadian Journal of Mathematics. 11: 34–38. doi:10.4153/CJM-1959-003-9. ISSN 0008-414X. S2CID 122784453.
- Seidel R. Backwards Analysis of Randomized Geometric Algorithms.
- A. A. Tsay, W. S. Lovejoy, David R. Karger, Random Sampling in Cut, Flow, and Network Design Problems, Mathematics of Operations Research, 24(2):383–413, 1999.
- Alippi, Cesare (2014), Intelligence for Embedded Systems, Springer, ISBN 978-3-319-05278-6.
- Kushilevitz, Eyal; Nisan, Noam (2006), Communication Complexity, Cambridge University Press, ISBN 9780521029834. For the deterministic lower bound see p. 11; for the logarithmic randomized upper bound see pp. 31–32.
- Dyer, M.; Frieze, A.; Kannan, R. (1991), "A random polynomial-time algorithm for approximating the volume of convex bodies" (PDF), Journal of the ACM, 38 (1): 1–17, doi:10.1145/102782.102783, S2CID 13268711
- Füredi, Z.; Bárány, I. (1986), "Computing the volume is difficult", Proc. 18th ACM Symposium on Theory of Computing (Berkeley, California, May 28–30, 1986) (PDF), New York, NY: ACM, pp. 442–447, CiteSeerX 10.1.1.726.9448, doi:10.1145/12130.12176, ISBN 0-89791-193-8, S2CID 17867291
- Shamir, A. (1992), "IP = PSPACE", Journal of the ACM, 39 (4): 869–877, doi:10.1145/146585.146609, S2CID 315182
- Cook, Matthew; Soloveichik, David; Winfree, Erik; Bruck, Jehoshua (2009), "Programmability of chemical reaction networks", in Condon, Anne; Harel, David; Kok, Joost N.; Salomaa, Arto; Winfree, Erik (eds.), Algorithmic Bioprocesses (PDF), Natural Computing Series, Springer-Verlag, pp. 543–584, doi:10.1007/978-3-540-88869-7_27.
References
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw–Hill, 1990. ISBN 0-262-03293-7. Chapter 5: Probabilistic Analysis and Randomized Algorithms, pp. 91–122.
- Dirk Draheim. "Semantics of the Probabilistic Typed Lambda Calculus (Markov Chain Semantics, Termination Behavior, and Denotational Semantics)." Springer, 2017.
- Jon Kleinberg and Éva Tardos. Algorithm Design. Chapter 13: "Randomized algorithms".
- Fallis, D. (2000). "The reliability of randomized algorithms". The British Journal for the Philosophy of Science. 51 (2): 255–271. doi:10.1093/bjps/51.2.255.
- M. Mitzenmacher and E. Upfal. Probability and Computing: Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, New York (NY), 2005.
- Rajeev Motwani and P. Raghavan. Randomized Algorithms. Cambridge University Press, New York (NY), 1995.
- Rajeev Motwani and P. Raghavan. Randomized Algorithms. A survey on Randomized Algorithms.
- Christos Papadimitriou (1993), Computational Complexity (1st ed.), Addison Wesley, ISBN 978-0-201-53082-7 Chapter 11: Randomized computation, pp. 241–278.
- Rabin, Michael O. (1980). "Probabilistic algorithm for testing primality". Journal of Number Theory. 12: 128–138. doi:10.1016/0022-314X(80)90084-0.
- A. A. Tsay, W. S. Lovejoy, David R. Karger, Random Sampling in Cut, Flow, and Network Design Problems, Mathematics of Operations Research, 24(2):383–413, 1999.
- "Randomized Algorithms for Scientific Computing" (RASC), OSTI.GOV (July 10th, 2021).