Perceptual Evaluation of Audio Quality
Perceptual Evaluation of Audio Quality (PEAQ) is a standardized algorithm for objectively measuring perceived audio quality, developed in 1994-1998 by a joint venture of experts within Task Group 6Q of the International Telecommunication Union's Radiocommunication Sector (ITU-R). It was originally released as ITU-R Recommendation BS.1387 in 1998 and last updated in 2023. It utilizes software to simulate perceptual properties of the human ear and then integrates multiple model output variables into a single metric.
PEAQ characterizes the perceived audio quality as subjects would do in a listening test according to ITU-R BS.1116. PEAQ results principally model mean opinion scores that cover a scale from 1 (bad) to 5 (excellent). The Subjective Difference Grade (SDG), which measures the degree of compression damage (impairment) is defined as the difference between the opinion scores of tested version and the reference (source). The SDG typically ranges from 0 (no perceived impairment) to -4 (terrible impairment). The Objective Difference Grade (ODG) is the actual output of the algorithm, designed to match SDG.[1]
| Impairment description | BS.1284 Grade[2] | ODG |
|---|---|---|
| Imperceptible | 5.0 | 0.0 |
| Perceptible, but not annoying | 4.0 | −1.0 |
| Slightly annoying | 3.0 | −2.0 |
| Annoying | 2.0 | −3.0 |
| Very annoying | 1.0 | −4.0 |
Motivation
The need to conserve bandwidth has led to developments in the compression of the audio data to be transmitted. Various encoding methods remove both redundancy and perceptual irrelevancy in the audio signal so that the bit rate required to encode the signal is significantly reduced. They take into account knowledge of human auditory perception and typically achieve a reduced bit rate by ignoring audio information that is not likely to be heard by most listeners. Traditional audio measurements like frequency response based on sinusoidal sweeps, S/N, THD+N do not necessarily correlate well with the audio codec quality. A psychoacoustic model must be used to predict how the information is masked by louder audio content adjacent in time and frequency.
Since subjective listening tests are time-consuming, expensive and impractical for everyday use, it was beneficial to substitute listening tests with objective, computer-based methods. Steered by the ITU-R Task Group 6Q, a group of leading sound quality experts developed a new objective model for sound quality: PEAQ. These contributors were:
- OPTICOM GmbH, Erlangen, Germany
- the Fraunhofer Institute for Integrated Circuits, IIS-A, Erlangen, Germany
- Deutsche Telekom Berkom, Berlin, Germany
- the University of Berlin, Berlin, Germany
- the Institut für Rundfunktechnik, IRT, Munich, Germany
- KPN Research, Dr. Neher Laboratorium, Leidschendam, The Netherlands
- Centre commun d'études de télévision et télécommunications, France
- Communications Research Centre, CRC, Ottawa, Canada
Principles
In perceptual coding it is fundamental to determine the level of noise that can be introduced into a signal before it becomes audible. Because the human auditory system is highly non-linear, noise levels vary with time and frequency characteristics of the audio signal. Psychoacoustic studies can deliver threshold criteria for various acoustic events and the resulting perceived sounds. The key is masking, that describes the effect that a sound produces into another simultaneous sound. Masking depends on the spectral composition of both masker and masking signal, and on other variations with time. The basic block diagram of a perceptual coding system is shown in the figure.

The input signal is decomposed into subsampled spectral components. For each sample an estimation of the actual masked threshold is derived using rules known from psychoacoustics. This is the perceptual model of the encoding system. The spectral components are quantized and coded, keeping the quantization noise below the masked threshold. Finally, the bitstream is formed.
The analysis of the results are based on the Subjective Difference Grade. It compares the signal under test with the original reference signal.
Models
The model follows the fundamental properties of the auditory system and it differences stages of physiological and psychoacoustic effects. The first part models the construction of the signal with a Discrete Fourier transform and filter banks. The second part provides cognitive processing as the human brain does. The next image represents a simple block diagram of the relationship between the human audio system and an objective psychoacoustic model.
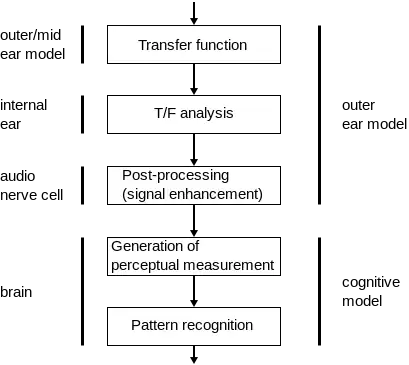
From the model comparison of the test signal with the (original) reference signal, a number of model output variables are derived. Each model output variable may measure different psychoacoustic dimensions. In the final stage the model output variables are combined using a neural network (weights defined in standard) to produce a result that copes with subjective quality assessment.
There are two variations of the model. The Basic version (less processing intensive) was developed to be fast enough for real-time monitoring and only uses FFT. The Advanced version is computationally more demanding and may deliver slightly more accurate results; it uses FFT and filter banks to produce more MOVs for the neural network to work with.
License
The PEAQ technology as recommended by ITU-R Rec. BS.1387 is protected by several patents and is available under license together with the original code for commercial applications according to ITU fair, reasonable, and non-discriminatory terms.
Royalty-free implementations
- An early open-source implementation of the basic model, named EAQUAL, was discontinued in 2002 because of patent infringement claims.
- For educational use, there exists a free cross-platform program called Peaqb which accomplishes the same functions in a limited manner, as it has not been validated with the ITU data. Evaluation by GstPEAQ authors show an RMSE of 0.2063 for 16 ITU test vectors.[3]
- Another unvalidated implementation of the PEAQ basic model for educational use, PQevalAudio, is available from the TSP Lab of McGill University. Evaluation by GstPEAQ authors show an RMSE of 0.2329 for 16 ITU test vectors.[3]
- GstPEAQ implements both the basic and advanced models, but fails to conform to BS.1387-1 tolerances. Nevertheless, the difference from conformance (RMSE 0.2009 in basic mode) is smaller than previous open-source implementations. The author also found that the difference to be statistically insignificant in terms of using the ODG as an estimate of the SDG.[3]
See also
References
- Rec. ITU-R BS.1387-2, pages 10,11
- ITU Recommendation BS.1284
- Holters, Martin; Zölzer, Udo (2015). GstPEAQ - an Open Source Implementation of the PEAQ Algorithm. 18th Int. Conference on Digital Audio Effects (DAFx-15). Trondheim, Norway.
- ITU-R Recommendation BS.1387: Method for objective measurements of perceived audio quality (PEAQ)
- ITU-R Recommendation BS.1116: Methods for the subjective assessment of small impairments in audio systems including multichannel sound systems
- ITU-R Recommendation BS.1534: Method for the subjective assessment of intermediate quality levels of coding systems (MUSHRA)
Further reading
- Andreas Spanias; Ted Painter; Venkatraman Atti (2007). "Quality Measures for Perceptual Audio Coding". Audio Signal Processing and Coding. Wiley-Interscience. pp. 401. ISBN 9780471791478.
- Nedeljko Cvejic; Tapio Tapio Seppänen (2007). "Subjective and Objective Quality Evaluation of Watremarked Audio". Digital Audio Watermarking Techniques and Technologies. Idea Group Inc. p. 270. ISBN 9781599045153.
- Delgado, Pablo M.; Herre, Jürgen (May 2020). Can We Still Use PEAQ? A Performance Analysis of the ITU Standard for the Objective Assessment of Perceived Audio Quality. 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX). pp. 1–6. arXiv:2212.01467. doi:10.1109/QoMEX48832.2020.9123105. – finds PEAQ falling behind other objective methods in terms of accuracy, but retraining the MOV-to-ODG neural network produces a model surpassing other objective methods
External links
- http://www.peaq.org PEAQ official site
- https://web.archive.org/web/20061207095623/http://www.crc.ca/en/html/aas/home/peaq/peaq PEAQ at the CRC
- https://web.archive.org/web/20090423074959/http://www.opticom.de/technology/technology.html PEAQ information from OPTICOM
- http://elvera.nue.tu-berlin.de/files/0829Thiede1998.pdf PEAQ - der künftige ITU-Standard zur objektiven Messung der wahrgenommenen Audioqualität
- https://ieeexplore.ieee.org/document/1613524 IEEE - Estimating Perceptual Audio System Quality Using PEAQ Algorithm
- http://sourceforge.net/projects/peaqb/ Peaqb project
- http://www-mmsp.ece.mcgill.ca/Documents/Software/index.html PQevalAudio - Matlab and C implementation of PEAQ Basic Model.
- http://www.mp3-tech.org/programmer/sources/eaqual.tgz EAQUAL source code