Neural network Gaussian process
A Neural Network Gaussian Process (NNGP) is a Gaussian process obtained as the limit (in the sense of convergence in distribution) of a sequence of neural networks,[1][2][3][4][5][6][7][8][9] and provide a closed form way to evaluate many kinds of neural networks.


Mathematically, an NNGP is just a gaussian process. It is distinguished only by how it is obtained (it is an intensional definition): a NNGP is a GP obtained as the limit of a sequence of neural networks, with limit taken in the sense of convergence in distribution.
A wide variety of neural network architectures converges in distribution to a gaussian process at the infinitely wide limit. This is proven for: single hidden layer Bayesian neural networks;[1] deep[3][4] fully connected networks as the number of units per layer is taken to infinity; convolutional neural networks as the number of channels is taken to infinity;[5][6][7] transformer networks as the number of attention heads is taken to infinity;[10] recurrent networks as the number of units is taken to infinity.[9]
In fact, this NNGP correspondence holds for almost any architecture: Generally, if an architecture can be expressed solely via matrix multiplication and coordinatewise nonlinearities (i.e. a tensor program), then it has an infinite-width GP.[9] This in particular includes all feedforward or recurrent neural networks composed of multilayer perceptron, recurrent neural networks (e.g. LSTMs, GRUs), (nD or graph) convolution, pooling, skip connection, attention, batch normalization, and/or layer normalization.
Motivation
Computation in artificial neural networks is usually organized into sequential layers of artificial neurons. The number of neurons in a layer is called the layer width. When we consider a sequence of Bayesian neural networks with increasingly wide layers (see figure), they converge in distribution to a NNGP. This large width limit is of practical interest, since neural networks often improve as layers get wider.[11][12][5][13]
Bayesian networks are a modeling tool for assigning probabilities to events, and thereby characterizing the uncertainty in a model's predictions. Deep learning and artificial neural networks are approaches used in machine learning to build computational models which learn from training examples. Bayesian neural networks merge these fields. They are a type of artificial neural network whose parameters and predictions are both probabilistic.[14][15] While standard artificial neural networks often assign high confidence even to incorrect predictions,[16] Bayesian neural networks can more accurately evaluate how likely their predictions are to be correct.
The NNGP also appears in several other contexts: it describes the distribution over predictions made by wide non-Bayesian artificial neural networks after random initialization of their parameters, but before training; it appears as a term in neural tangent kernel prediction equations; it is used in deep information propagation to characterize whether hyperparameters and architectures will be trainable.[17] It is related to other large width limits of neural networks.
A cartoon illustration



Every setting of a neural network's parameters corresponds to a specific function computed by the neural network. A prior distribution over neural network parameters therefore corresponds to a prior distribution over functions computed by the network. As neural networks are made infinitely wide, this distribution over functions converges to a Gaussian process for many architectures.
The figure to the right plots the one-dimensional outputs of a neural network for two inputs and against each other. The black dots show the function computed by the neural network on these inputs for random draws of the parameters from . The red lines are iso-probability contours for the joint distribution over network outputs and induced by . This is the distribution in function space corresponding to the distribution in parameter space, and the black dots are samples from this distribution. For infinitely wide neural networks, since the distribution over functions computed by the neural network is a Gaussian process, the joint distribution over network outputs is a multivariate Gaussian for any finite set of network inputs.





The notation used in this section is the same as the notation used below to derive the correspondence between NNGPs and fully connected networks, and more details can be found there.
Infinitely wide fully connected network
This section expands on the correspondence between infinitely wide neural networks and Gaussian processes for the specific case of a fully connected architecture. It provides a proof sketch outlining why the correspondence holds, and introduces the specific functional form of the NNGP for fully connected networks. The proof sketch closely follows the approach in Novak, et al., 2018.[5]
Network architecture specification
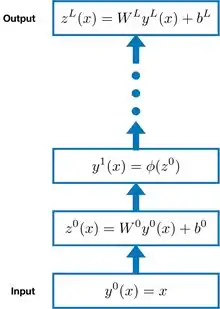
Consider a fully connected artificial neural network with inputs , parameters consisting of weights and biases for each layer in the network, pre-activations (pre-nonlinearity) , activations (post-nonlinearity) , pointwise nonlinearity , and layer widths . For simplicity, the width of the readout vector is taken to be 1. The parameters of this network have a prior distribution , which consists of an isotropic Gaussian for each weight and bias, with the variance of the weights scaled inversely with layer width. This network is illustrated in the figure to the right, and described by the following set of equations:










is a Gaussian process

We first observe that the pre-activations are described by a Gaussian process conditioned on the preceding activations . This result holds even at finite width. Each pre-activation is a weighted sum of Gaussian random variables, corresponding to the weights and biases , where the coefficients for each of those Gaussian variables are the preceding activations . Because they are a weighted sum of zero-mean Gaussians, the are themselves zero-mean Gaussians (conditioned on the coefficients ). Since the are jointly Gaussian for any set of , they are described by a Gaussian process conditioned on the preceding activations . The covariance or kernel of this Gaussian process depends on the weight and bias variances and , as well as the second moment matrix of the preceding activations ,








The effect of the weight scale is to rescale the contribution to the covariance matrix from , while the bias is shared for all inputs, and so makes the for different datapoints more similar and makes the covariance matrix more like a constant matrix.
is a Gaussian process

The pre-activations only depend on through its second moment matrix . Because of this, we can say that is a Gaussian process conditioned on , rather than conditioned on ,

As layer width , becomes deterministic


As previously defined, is the second moment matrix of . Since is the activation vector after applying the nonlinearity , it can be replaced by , resulting in a modified equation expressing for in terms of ,





We have already determined that is a Gaussian process. This means that the sum defining is an average over samples from a Gaussian process which is a function of ,



As the layer width goes to infinity, this average over samples from the Gaussian process can be replaced with an integral over the Gaussian process:
![{\displaystyle {\begin{aligned}\lim _{n^{l}\rightarrow \infty }K^{l}(x,x')&=\int dzdz'\phi (z)\phi (z'){\mathcal {N}}\left(\left[{\begin{array}{c}z\\z'\end{array}}\right];0,\sigma _{w}^{2}\left[{\begin{array}{cc}K^{l-1}(x,x)&K^{l-1}(x,x')\\K^{l-1}(x',x)&K^{l-1}(x',x')\end{array}}\right]+\sigma _{b}^{2}\right)\end{aligned}}}](../I/f28ed148243a41818669a6f91f242ca4fd1c521a.svg)
So, in the infinite width limit the second moment matrix for each pair of inputs and can be expressed as an integral over a 2d Gaussian, of the product of and . There are a number of situations where this has been solved analytically, such as when is a ReLU,[18] ELU, GELU,[19] or error function[2] nonlinearity. Even when it can't be solved analytically, since it is a 2d integral it can generally be efficiently computed numerically.[3] This integral is deterministic, so is deterministic.




For shorthand, we define a functional , which corresponds to computing this 2d integral for all pairs of inputs, and which maps into ,


is an NNGP

By recursively applying the observation that is deterministic as , can be written as a deterministic function of ,



where indicates applying the functional sequentially times. By combining this expression with the further observations that the input layer second moment matrix is a deterministic function of the input , and that is a Gaussian process, the output of the neural network can be expressed as a Gaussian process in terms of its input,





Software libraries
Neural Tangents is a free and open-source Python library used for computing and doing inference with the NNGP and neural tangent kernel corresponding to various common ANN architectures.[20]
References
- Neal, Radford M. (1996), "Priors for Infinite Networks", Bayesian Learning for Neural Networks, Lecture Notes in Statistics, vol. 118, Springer New York, pp. 29–53, doi:10.1007/978-1-4612-0745-0_2, ISBN 978-0-387-94724-2
- Williams, Christopher K. I. (1997). "Computing with infinite networks". Neural Information Processing Systems.
- Lee, Jaehoon; Bahri, Yasaman; Novak, Roman; Schoenholz, Samuel S.; Pennington, Jeffrey; Sohl-Dickstein, Jascha (2017). "Deep Neural Networks as Gaussian Processes". International Conference on Learning Representations. arXiv:1711.00165. Bibcode:2017arXiv171100165L.
- G. de G. Matthews, Alexander; Rowland, Mark; Hron, Jiri; Turner, Richard E.; Ghahramani, Zoubin (2017). "Gaussian Process Behaviour in Wide Deep Neural Networks". International Conference on Learning Representations. arXiv:1804.11271. Bibcode:2018arXiv180411271M.
- Novak, Roman; Xiao, Lechao; Lee, Jaehoon; Bahri, Yasaman; Yang, Greg; Abolafia, Dan; Pennington, Jeffrey; Sohl-Dickstein, Jascha (2018). "Bayesian Deep Convolutional Networks with Many Channels are Gaussian Processes". International Conference on Learning Representations. arXiv:1810.05148. Bibcode:2018arXiv181005148N.
- Garriga-Alonso, Adrià; Aitchison, Laurence; Rasmussen, Carl Edward (2018). "Deep Convolutional Networks as shallow Gaussian Processes". International Conference on Learning Representations. arXiv:1808.05587. Bibcode:2018arXiv180805587G.
- Borovykh, Anastasia (2018). "A Gaussian Process perspective on Convolutional Neural Networks". arXiv:1810.10798 [stat.ML].
- Tsuchida, Russell; Pearce, Tim; van der Heide, Christopher; Roosta, Fred; Gallagher, Marcus (2020). "Avoiding Kernel Fixed Points: Computing with ELU and GELU Infinite Networks". arXiv:2002.08517 [cs.LG].
- Yang, Greg (2019). "Tensor Programs I: Wide Feedforward or Recurrent Neural Networks of Any Architecture are Gaussian Processes" (PDF). Advances in Neural Information Processing Systems. arXiv:1910.12478. Bibcode:2019arXiv191012478Y.
- Hron, Jiri; Bahri, Yasaman; Sohl-Dickstein, Jascha; Novak, Roman (2020-06-18). "Infinite attention: NNGP and NTK for deep attention networks". International Conference on Machine Learning. 2020. arXiv:2006.10540. Bibcode:2020arXiv200610540H.
- Novak, Roman; Bahri, Yasaman; Abolafia, Daniel A.; Pennington, Jeffrey; Sohl-Dickstein, Jascha (2018-02-15). "Sensitivity and Generalization in Neural Networks: an Empirical Study". International Conference on Learning Representations. arXiv:1802.08760. Bibcode:2018arXiv180208760N.
-
Canziani, Alfredo; Paszke, Adam; Culurciello, Eugenio (2016-11-04). "An Analysis of Deep Neural Network Models for Practical Applications". arXiv:1605.07678. Bibcode:2016arXiv160507678C.
{{cite journal}}: Cite journal requires|journal=(help) - Neyshabur, Behnam; Li, Zhiyuan; Bhojanapalli, Srinadh; LeCun, Yann; Srebro, Nathan (2019). "Towards understanding the role of over-parametrization in generalization of neural networks". International Conference on Learning Representations. arXiv:1805.12076. Bibcode:2018arXiv180512076N.
- MacKay, David J. C. (1992). "A Practical Bayesian Framework for Backpropagation Networks". Neural Computation. 4 (3): 448–472. doi:10.1162/neco.1992.4.3.448. ISSN 0899-7667. S2CID 16543854.
- Neal, Radford M. (2012). Bayesian Learning for Neural Networks. Springer Science and Business Media.
- Guo, Chuan; Pleiss, Geoff; Sun, Yu; Weinberger, Kilian Q. (2017). "On calibration of modern neural networks". Proceedings of the 34th International Conference on Machine Learning-Volume 70. arXiv:1706.04599.
- Schoenholz, Samuel S.; Gilmer, Justin; Ganguli, Surya; Sohl-Dickstein, Jascha (2016). "Deep information propagation". International Conference on Learning Representations. arXiv:1611.01232.
- Cho, Youngmin; Saul, Lawrence K. (2009). "Kernel Methods for Deep Learning". Neural Information Processing Systems. 22: 342–350.
- Tsuchida, Russell; Pearce, Tim; van der Heide, Christopher; Roosta, Fred; Gallagher, Marcus (2020). "Avoiding Kernel Fixed Points: Computing with ELU and GELU Infinite Networks". arXiv:2002.08517 [cs.LG].
- Novak, Roman; Xiao, Lechao; Hron, Jiri; Lee, Jaehoon; Alemi, Alexander A.; Sohl-Dickstein, Jascha; Schoenholz, Samuel S. (2019-12-05), "Neural Tangents: Fast and Easy Infinite Neural Networks in Python", International Conference on Learning Representations (ICLR), vol. 2020, arXiv:1912.02803, Bibcode:2019arXiv191202803N