Medoid
Medoids are representative objects of a data set or a cluster within a data set whose sum of dissimilarities to all the objects in the cluster is minimal.[1] Medoids are similar in concept to means or centroids, but medoids are always restricted to be members of the data set. Medoids are most commonly used on data when a mean or centroid cannot be defined, such as graphs. They are also used in contexts where the centroid is not representative of the dataset like in images, 3-D trajectories and gene expression[2] (where while the data is sparse the medoid need not be). These are also of interest while wanting to find a representative using some distance other than squared euclidean distance (for instance in movie-ratings).
For some data sets there may be more than one medoid, as with medians. A common application of the medoid is the k-medoids clustering algorithm, which is similar to the k-means algorithm but works when a mean or centroid is not definable. This algorithm basically works as follows. First, a set of medoids is chosen at random. Second, the distances to the other points are computed. Third, data are clustered according to the medoid they are most similar to. Fourth, the medoid set is optimized via an iterative process.
Note that a medoid is not equivalent to a median, a geometric median, or centroid. A median is only defined on 1-dimensional data, and it only minimizes dissimilarity to other points for metrics induced by a norm (such as the Manhattan distance or Euclidean distance). A geometric median is defined in any dimension, but unlike a medoid, it is not necessarily a point from within the original dataset.



Clustering with medoids
Medoids are a popular replacement for the cluster mean when the distance function is not (squared) Euclidean distance, or not even a metric (as the medoid does not require the triangle inequality). When partitioning the data set into clusters, the medoid of each cluster can be used as a representative of each cluster.
Clustering algorithms based on the idea of medoids include:
- Partitioning Around Medoids (PAM), the standard k-medoids algorithm
- Hierarchical Clustering Around Medoids (HACAM), which uses medoids in hierarchical clustering
Algorithms to compute the medoid of a set
From the definition above, it is clear that the medoid of a set can be computed after computing all pairwise distances between points in the ensemble. This would take distance evaluations (with ). In the worst case, one can not compute the medoid with fewer distance evaluations.[3][4] However, there are many approaches that allow us to compute medoids either exactly or approximately in sub-quadratic time under different statistical models.



If the points lie on the real line, computing the medoid reduces to computing the median which can be done in by Quick-select algorithm of Hoare.[5] However, in higher dimensional real spaces, no linear-time algorithm is known. RAND[6] is an algorithm that estimates the average distance of each point to all the other points by sampling a random subset of other points. It takes a total of distance computations to approximate the medoid within a factor of with high probability, where is the maximum distance between two points in the ensemble. Note that RAND is an approximation algorithm, and moreover may not be known apriori.




RAND was leveraged by TOPRANK [7] which uses the estimates obtained by RAND to focus on a small subset of candidate points, evaluates the average distance of these points exactly, and picks the minimum of those. TOPRANK needs distance computations to find the exact medoid with high probability under a distributional assumption on the average distances.

trimed [3] presents an algorithm to find the medoid with distance evaluations under a distributional assumption on the points. The algorithm uses the triangle inequality to cut down the search space.

Meddit[4] leverages a connection of the medoid computation with multi-armed bandits and uses an upper-Confidence-bound type of algorithm to get an algorithm which takes distance evaluations under statistical assumptions on the points.

Correlated Sequential Halving[8] also leverages multi-armed bandit techniques, improving upon Meddit. By exploiting the correlation structure in the problem, the algorithm is able to provably yield drastic improvement (usually around 1-2 orders of magnitude) in both number of distance computations needed and wall clock time.
Implementations
An implementation of RAND, TOPRANK, and trimed can be found here. An implementation of Meddit can be found here and here. An implementation of Correlated Sequential Halving can be found here.
Medoids in text and natural language processing (NLP)
Medoids can be applied to various text and NLP tasks to improve the efficiency and accuracy of analyses.[9] By clustering text data based on similarity, medoids can help identify representative examples within the dataset, leading to better understanding and interpretation of the data.
Text clustering
Text clustering is the process of grouping similar text or documents together based on their content. Medoid-based clustering algorithms can be employed to partition large amounts of text into clusters, with each cluster represented by a medoid document. This technique helps in organizing, summarizing, and retrieving information from large collections of documents, such as in search engines, social media analytics and recommendation systems.[10]
Text summarization
Text summarization aims to produce a concise and coherent summary of a larger text by extracting the most important and relevant information. Medoid-based clustering can be used to identify the most representative sentences in a document or a group of documents, which can then be combined to create a summary. This approach is especially useful for extractive summarization tasks, where the goal is to generate a summary by selecting the most relevant sentences from the original text.[11]
Sentiment analysis
Sentiment analysis involves determining the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral. Medoid-based clustering can be applied to group text data based on similar sentiment patterns. By analyzing the medoid of each cluster, researchers can gain insights into the predominant sentiment of the cluster, helping in tasks such as opinion mining, customer feedback analysis, and social media monitoring.[12]
Topic modeling
Topic modeling is a technique used to discover abstract topics that occur in a collection of documents. Medoid-based clustering can be applied to group documents with similar themes or topics. By analyzing the medoids of these clusters, researchers can gain an understanding of the underlying topics in the text corpus, facilitating tasks such as document categorization, trend analysis, and content recommendation.[13]
Techniques for measuring text similarity in medoid-based clustering
When applying medoid-based clustering to text data, it is essential to choose an appropriate similarity measure to compare documents effectively. Each technique has its advantages and limitations, and the choice of the similarity measure should be based on the specific requirements and characteristics of the text data being analyzed.[14] The following are common techniques for measuring text similarity in medoid-based clustering:

Cosine similarity
Cosine similarity is a widely used measure to compare the similarity between two pieces of text. It calculates the cosine of the angle between two document vectors in a high-dimensional space.[14] Cosine similarity ranges between -1 and 1, where a value closer to 1 indicates higher similarity, and a value closer to -1 indicates lower similarity. By visualizing two lines originating from the origin and extending to the respective points of interest, and then measuring the angle between these lines, one can determine the similarity between the associated points. Cosine similarity is less affected by document length, so it may be better at producing medoids that are representative of the content of a cluster instead of the length.
Jaccard similarity
Jaccard similarity, also known as the Jaccard coefficient, measures the similarity between two sets by comparing the ratio of their intersection to their union. In the context of text data, each document is represented as a set of words, and the Jaccard similarity is computed based on the common words between the two sets. The Jaccard similarity ranges between 0 and 1, where a higher value indicates a higher degree of similarity between the documents. [15]
Euclidean distance

Euclidean distance is a standard distance metric used to measure the dissimilarity between two points in a multi-dimensional space. In the context of text data, documents are often represented as high-dimensional vectors, such as TF vectors, and the Euclidean distance can be used to measure the dissimilarity between them. A lower Euclidean distance indicates a higher degree of similarity between the documents.[14] Using Euclidean distance may result in medoids that are more representative of the length of a document.
Edit distance
Edit distance, also known as the Levenshtein distance, measures the similarity between two strings by calculating the minimum number of operations (insertions, deletions, or substitutions) required to transform one string into the other. In the context of text data, edit distance can be used to compare the similarity between short text documents or individual words. A lower edit distance indicates a higher degree of similarity between the strings.[16]
Medoids for analyzing large language model embeddings

Medoids can be employed to analyze and understand the vector space representations generated by large language models (LLMs), such as BERT, GPT, or RoBERTa. By applying medoid-based clustering on the embeddings produced by these models for words, phrases, or sentences, researchers can explore the semantic relationships captured by LLMs. This approach can help identify clusters of semantically similar entities, providing insights into the structure and organization of the high-dimensional embedding spaces generated by these models.[17]
Medoids for data selection and active learning
Active learning involves choosing data points from a training pool that will maximize model performance. Medoids can play a crucial role in data selection and active learning with LLMs. Medoid-based clustering can be used to identify representative and diverse samples from a large text dataset, which can then be employed to fine-tune LLMs more efficiently or to create better training sets. By selecting medoids as training examples, researchers can may have a more balanced and informative training set, potentially improving the generalization and robustness of the fine-tuned models.[18]
Medoids for model interpretability and safety
Applying medoids in the context of LLMs can contribute to improving model interpretability. By clustering the embeddings generated by LLMs and selecting medoids as representatives of each cluster, researchers can provide a more interpretable summary of the model's behavior.[19] This approach can help in understanding the model's decision-making process, identifying potential biases, and uncovering the underlying structure of the LLM-generated embeddings. As the discussion around interpretability and safety of LLMs continues to ramp up, using medoids may serve as a valuable tool for achieving this goal.
Real-world applications
As a versatile clustering method, medoids can be applied to a variety of real-world issues in numerous fields, stretching from biology and medicine to advertising and marketing, and social networks. Its potential to handle complex data sets with a high degree of perplexity makes it a powerful device in modern-day data analytics.
Gene expression analysis
In gene expression analysis,[20] researchers utilize advanced technologies consisting of microarrays and RNA sequencing to measure the expression levels of numerous genes in biological samples, which results in multi-dimensional data that can be complex and difficult to analyze. Medoids are a potential solution by clustering genes primarily based on their expression profiles, enabling researchers to discover co-expressed groups of genes that could provide valuable insights into the molecular mechanisms of biological processes and diseases.
Social network analysis
For social network evaluation,[21] medoids can be an exceptional tool for recognizing central or influential nodes in a social network. Researchers can cluster nodes based on their connectivity styles and identify nodes which are most likely to have a substantial impact on the network’s function and structure. One popular approach to making use of medoids in social network analysis is to compute a distance or similarity metric between pairs of nodes based on their properties.
Market segmentation
Medoids also can be employed for market segmentation,[22] which is an analytical procedure that includes grouping clients primarily based on their purchasing behavior, demographic traits, and various other attributes. Clustering clients into segments using medoids allows companies to tailor their advertising and marketing techniques in a manner that aligns with the needs of each group of customers. The medoids serve as representative factors within every cluster, encapsulating the primary characteristics of the customers in that group.
The Within-Groups Sum of Squared Error (WGSS) is a formula employed in market segmentation that aims to quantify the concentration of squared errors within clusters. It seeks to capture the distribution of errors within groups by squaring them and aggregating the results.The WGSS metric quantifies the cohesiveness of samples within clusters, indicating tighter clusters with lower WGSS values and a correspondingly superior clustering effect. The formula for WGSS is:
![{\displaystyle {\text{WGSS}}={\frac {1}{2}}\left[(m_{1}-1){\overline {d_{1}^{2}}}+\cdots +(m_{k}-1){\overline {d_{k}^{2}}}\right]}](../I/7ad19657ee425e259ef4da7dd36527452c25a440.svg)
Where is the average distance of samples within the k-th cluster and is the number of samples in the k-th cluster.


Anomaly detection
Medoids can also be instrumental in identifying anomalies,[23] and one efficient method is through cluster-based anomaly detection. They can be used to discover clusters of data points that deviate significantly from the rest of the data. By clustering the data into groups using medoids and comparing the properties of every cluster to the data, researchers can clearly detect clusters that are anomalous.
Visualization of the medoid-based clustering process
Purpose
Visualization of medoid-based clustering can be helpful when trying to understand how medoid-based clustering work. Studies have shown that people learn better with visual information.[24] In medoid-based clustering, the medoid is the center of the cluster. This is different from k-means clustering, where the center isn't a real data point, but instead can lie between data points. We use the medoid to group “clusters” of data, which is obtained by finding the element with minimal average dissimilarity to all other objects in the cluster.[25] Although the visualization example used utilizes k-medoids clustering, the visualization can be applied to k-means clustering as well by swapping out average dissimilarity with the mean of the dataset being used.
Distance matrix
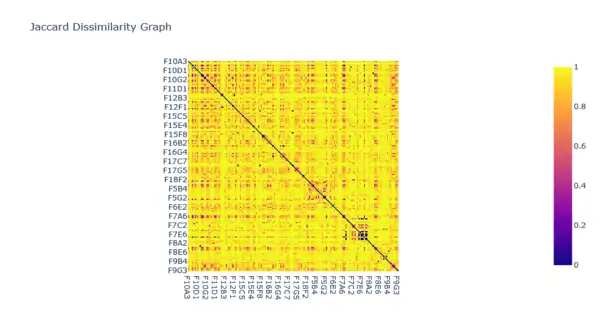
A distance matrix is required for medoid-based clustering, which is generated using Jaccard Dissimilarity (which is 1 - the Jaccard Index). This distance matrix is used to calculate the distance between two points on a one-dimensional graph. The above image shows an example of a Jaccard Dissimilarity graph.
Clustering
- Step 1
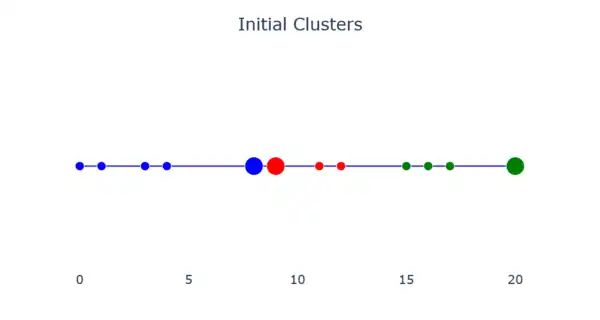
Medoid-based clustering is used to find clusters within a dataset. An initial one-dimensional dataset which contains clusters that need to be discovered is used for the process of medoid-based clustering. In the image below, there are twelve different objects in the dataset at varying x-positions.

- Step 2
K random points are chosen to be the initial centers. The value chosen for K is known as the K-value. In the image below, 3 has been chosen as the K-value. The process for finding the optimal K-value will be discussed in step 7.

- Step 3
Each non-center object is assigned to its nearest center. This is done using a distance matrix. The lower the dissimilarity, the closer the points are. In the image below, there are 5 objects in cluster 1, 3 in cluster 2, and 4 in cluster 3.
- Step 4
The new center for each cluster is found by finding the object whose average dissimilarity to all other objects in the cluster is minimal. The center selected during this step is called the medoid. The image below shows the results of medoid selection.

- Step 5
Steps 3-4 are repeated until the centers no longer move, as in the images below.
- Repeating Steps 3-4 (from left to right)
 The second clusters.
The second clusters. Medoid selection.
Medoid selection.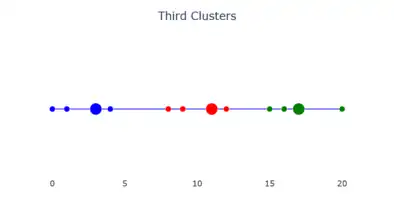 The third clusters.
The third clusters.- Final medoid selection.
- Step 6
The final clusters are obtained when the centers no longer move between steps. The image below shows what a final cluster can look like.
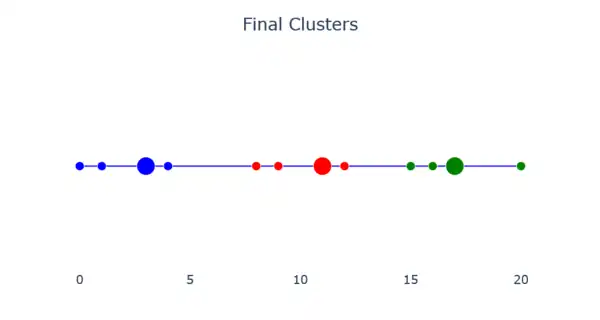
- Step 7
The variation is added up within each cluster to see how accurate the centers are. By running this test with different K-values, an "elbow" of the variation graph can be acquired, where the graph's variation levels out. The "elbow" of the graph is the optimal K-value for the dataset.
Medoids in high dimensions
A common problem with k-medoids clustering and other medoid-based clustering algorithms is the "curse of dimensionality," in which the data points contain too many dimensions or features. As dimensions are added to the data, the distance between them becomes sparse,[26] and it becomes difficult to characterize clustering by Euclidean distance alone. As a result, distance based similarity measures converge to a constant [27] and we have a characterization of distance between points which may not be reflect our data set in meaningful ways.
One way to mitigate the affects of the curse of dimensionality is by using spectral clustering. Spectral clustering achieves a more appropriate analysis by reducing the dimensionality of then data using principle component analysis, projecting the data points into the lower dimensional subspace, and then running the chosen clustering algorithm as before. One thing to note, however, is that as with any dimension reduction we lose information,[28] so it must be weighed against clustering in advanced how much reduction is necessary before too much data is lost.
High dimensionality doesn't only affect distance metrics however, as the time complexity also increases with the number of features. k-medoids is sensitive to initial choice of medoids, as they are usually selected randomly. Depending on how such medoids are initialized, k-medoids may converge to different local optima, resulting in different clusters and quality measures,[29] meaning k-medoids might need to run multiple times with different initializations, resulting in a much higher run time. One way to counterbalance this is to use k-medoids++,[30] an alternative to k-medoids similar to its k-means counterpart, k-means++ which chooses initial medoids to begin with based on a probability distribution, as a sort of "informed randomness" or educated guess if you will. If such medoids are chosen with this rationale, the result is an improved runtime and better performance in clustering. The k-medoids++ algorithm is described as follows:[31]
- The initial medoid is chosen randomly among all of the spatial points.
- For each spatial point 𝑝, compute the distance between 𝑝 and the nearest medoids which is termed as D(𝑝) and sum all the distances to 𝑆 .
- The next medoid is determined by using weighted probability distribution. Specifically, a random number 𝑅 between zero and the summed distance 𝑆 is chosen and the corresponding spatial point is the next medoid.
- Step (2) and Step (3) are repeated until 𝑘 medoids have been chosen.
Now that we have appropriate first selections for medoids, the normal variation of k-medoids can be run.
References
- Struyf, Anja; Hubert, Mia; Rousseeuw, Peter (1997). "Clustering in an Object-Oriented Environment". Journal of Statistical Software. 1 (4): 1–30.
- van der Laan, Mark J.; Pollard, Katherine S.; Bryan, Jennifer (2003). "A New Partitioning Around Medoids Algorithm". Journal of Statistical Computation and Simulation. Taylor & Francis Group. 73 (8): 575–584. doi:10.1080/0094965031000136012. S2CID 17437463.
- Newling, James; & Fleuret, François (2016); "A sub-quadratic exact medoid algorithm", in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR 54:185-193, 2017 Available online.
- Bagaria, Vivek; Kamath, Govinda M.; Ntranos, Vasilis; Zhang, Martin J.; Tse, David (2017). "Medoids in almost linear time via multi-armed bandits". arXiv:1711.00817.
{{cite journal}}: Cite journal requires|journal=(help) - Hoare, Charles Antony Richard (1961); "Algorithm 65: find", in Communications of the ACM, 4(7), 321-322
- Eppstein, David; & Wang, Joseph (2006); "Fast approximation of centrality", in Graph Algorithms and Applications, 5, pp. 39-45
- Okamoto, Kazuya; Chen, Wei; Li, Xiang-Yang (2008). "Ranking of Closeness Centrality for Large-Scale Social Networks". Frontiers in Algorithmics. Lecture Notes in Computer Science. Vol. 5059. pp. 186–195. doi:10.1007/978-3-540-69311-6_21. ISBN 978-3-540-69310-9.
- Baharav, Tavor Z.; & Tse, David N. (2019); "Ultra Fast Medoid Identification via Correlated Sequential Halving", in Advances in Neural Information Processing Systems, available online
- Dai, Qiongjie; Liu, Jicheng (July 2019). "The Exploration and Application of K-medoids in Text Clustering" (PDF). Retrieved 25 April 2023.
- "What is Natural Language Processing?".
- Hu, Po; He, Tingting; Ji, Donghong. "Chinese Text Summarization Based on Thematic Area Detection" (PDF).
- Pessutto, Lucas; Vargas, Danny; Moreira, Viviane (24 February 2020). "Multilingual aspect clustering for sentiment analysis". Knowledge-Based Systems. 192: 105339. doi:10.1016/j.knosys.2019.105339. S2CID 211830280.
- Preud'homme, Gregoire; Duarte, Kevin (18 February 2021). "Head-to-head comparison of clustering methods for heterogeneous data: a simulation-driven benchmark". Scientific Reports. 11 (1): 4202. Bibcode:2021NatSR..11.4202P. doi:10.1038/s41598-021-83340-8. PMC 7892576. PMID 33603019.
- Amer, Ali; Abdalla, Hassan (14 September 2020). "A set theory based similarity measure for text clustering and classification". Journal of Big Data. 7. doi:10.1186/s40537-020-00344-3. S2CID 256403960.
- Leo, Marie (25 April 2022). "Semantic Textual Similarity".
- Wu, Gang (17 December 2022). "String Similarity Metrics – Edit Distance".
- Mokhtarani, Shabnam (26 August 2021). "Embeddings in Machine Learning: Everything You Need to Know".
- Wu, Yuexin; Xu, Yichong; Singh, Aarti; Yang, Yiming; Dubrawski, Artur (2019). "Active Learning for Graph Neural Networks via Node Feature Propagation". arXiv:1910.07567 [cs.LG].
- Tiwari, Mo; Mayclin, James; Piech, Chris; Zhang, Martin; Thrun, Sebastian; Shomorony, Ilan (2020). "BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits". arXiv:2006.06856 [cs.LG].
- Zhang, Yan; Shi, Weiyu; Sun, Yeqing (2023-02-17). "A functional gene module identification algorithm in gene expression data based on genetic algorithm and gene ontology". BMC Genomics. 24 (1): 76. doi:10.1186/s12864-023-09157-z. ISSN 1471-2164. PMC 9936134. PMID 36797662.
- Saha, Sanjit Kumar; Schmitt, Ingo (2020-01-01). "Non-TI Clustering in the Context of Social Networks". Procedia Computer Science. The 11th International Conference on Ambient Systems, Networks and Technologies (ANT) / The 3rd International Conference on Emerging Data and Industry 4.0 (EDI40) / Affiliated Workshops. 170: 1186–1191. doi:10.1016/j.procs.2020.03.031. ISSN 1877-0509. S2CID 218812939.
- Wu, Zengyuan; Jin, Lingmin; Zhao, Jiali; Jing, Lizheng; Chen, Liang (18 June 2022). "Research on Segmenting E-Commerce Customer through an Improved K-Medoids Clustering Algorithm". Computational Intelligence and Neuroscience. 2022: 1–10. doi:10.1155/2022/9930613. PMC 9233613. PMID 35761867.
- Gumbao, María García (2019-06-04). "Best clustering algorithms for anomaly detection". Medium. Retrieved 2023-04-27.
- Midway, Stephen R. (December 2020). "Principles of Effective Data Visualization". Patterns. 1 (9): 100141. doi:10.1016/j.patter.2020.100141. PMC 7733875. PMID 33336199.
- https://www.researchgate.net/publication/243777819_Clustering_by_Means_of_Medoids
- "Curse of Dimensionality". 17 May 2019.
- "K-Means Advantages and Disadvantages | Machine Learning".
- "K Means Clustering on High Dimensional Data". 10 April 2022.
- "What are the main drawbacks of using k-means for high-dimensional data?".
- Yue, Xia (2015). "Parallel K-Medoids++ Spatial Clustering Algorithm Based on MapReduce". arXiv:1608.06861 [cs.DC].
- Yue, Xia (2015). "Parallel K-Medoids++ Spatial Clustering Algorithm Based on MapReduce". arXiv:1608.06861 [cs.DC].
External links
- StatQuest k-means video used for visual reference in #Visualization_of_the_medoid-based_clustering_process section