Masking threshold
Masking threshold within acoustics (a branch of physics that deals with topics such as vibration, sound, ultrasound , and infrasound), refers to a process where if there are two concurrent sounds and one sound is louder than the other, a person may be unable to hear the soft sound because it is masked by the louder sound.[1]
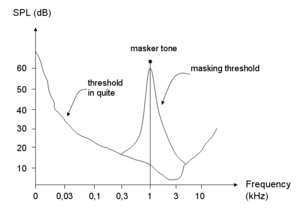
So the masking threshold is the sound pressure level of a sound needed to make the sound audible in the presence of another noise called a "masker". This threshold depends upon the frequency, the type of masker, and the kind of sound being masked. The effect is strongest between two sounds close in frequency.
In the context of audio transmission, there are some advantages to being unable to perceive a sound. In audio encoding , for example, better compression can be achieved by omitting the inaudible tones. This requires fewer bits to encode the sound and reduces the size of the final file.
Applications in audio compression
It is uncommon to work with only one tone. Most sounds are composed of multiple tones. There can be many possible maskers at the same frequency. In this situation, it would be necessary to compute the global masking threshold using a high resolution Fast Fourier transform via 512 or 1024 points to determine the frequencies that comprise the sound. Because there are bandwidths that humans are not able to hear, it is necessary to know the signal level, masker type, and the frequency band before computing the individual thresholds. To avoid having the masking threshold under the threshold in quiet, one adds the last one to the computation of partial thresholds. This allows computation of the signal-to-mask ratio (SMR).
The psychoacoustic model
The MPEG audio encoding process leverages the masking threshold. In this process, there is a block called "Psychoacoustic model". This is communicated with the band filter and the quantify block. The psychoacoustic model analyzes the samples sent to it by the filter band, computing the masking threshold in each frequency band using a Fast Fourier transform. The number of points used depends upon the MPEG layer. Using these thresholds, the signal-to-mask ratio is determined and sent to the quantifier. The quantifier assigns more or less bits in each block based upon the SMR. The block with the highest SMR will encode with the maximum number of bits.
References
- "Masking - Learn more about upward spread of masking | hear-it.org". www.hear-it.org. Retrieved 2022-04-21.