Interactome
In molecular biology, an interactome is the whole set of molecular interactions in a particular cell. The term specifically refers to physical interactions among molecules (such as those among proteins, also known as protein–protein interactions, PPIs; or between small molecules and proteins[1]) but can also describe sets of indirect interactions among genes (genetic interactions).
The word "interactome" was originally coined in 1999 by a group of French scientists headed by Bernard Jacq.[3] Mathematically, interactomes are generally displayed as graphs. Though interactomes may be described as biological networks, they should not be confused with other networks such as neural networks or food webs.
Molecular interaction networks
Molecular interactions can occur between molecules belonging to different biochemical families (proteins, nucleic acids, lipids, carbohydrates, etc.) and also within a given family. Whenever such molecules are connected by physical interactions, they form molecular interaction networks that are generally classified by the nature of the compounds involved. Most commonly, interactome refers to protein–protein interaction (PPI) network (PIN) or subsets thereof. For instance, the Sirt-1 protein interactome and Sirt family second order interactome[4][5] is the network involving Sirt-1 and its directly interacting proteins where as second order interactome illustrates interactions up to second order of neighbors (Neighbors of neighbors). Another extensively studied type of interactome is the protein–DNA interactome, also called a gene-regulatory network, a network formed by transcription factors, chromatin regulatory proteins, and their target genes. Even metabolic networks can be considered as molecular interaction networks: metabolites, i.e. chemical compounds in a cell, are converted into each other by enzymes, which have to bind their substrates physically.
In fact, all interactome types are interconnected. For instance, protein interactomes contain many enzymes which in turn form biochemical networks. Similarly, gene regulatory networks overlap substantially with protein interaction networks and signaling networks.
Size
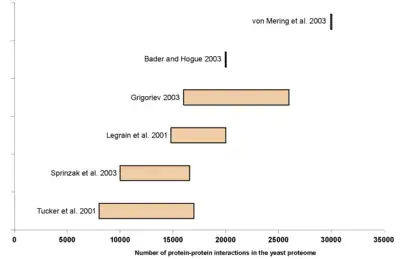
It has been suggested that the size of an organism's interactome correlates better than genome size with the biological complexity of the organism.[7] Although protein–protein interaction maps containing several thousand binary interactions are now available for several species, none of them is presently complete and the size of interactomes is still a matter of debate.
Yeast
The yeast interactome, i.e. all protein–protein interactions among proteins of Saccharomyces cerevisiae, has been estimated to contain between 10,000 and 30,000 interactions. A reasonable estimate may be on the order of 20,000 interactions. Larger estimates often include indirect or predicted interactions, often from affinity purification/mass spectrometry (AP/MS) studies.[6]
Genetic interaction networks
Genes interact in the sense that they affect each other's function. For instance, a mutation may be harmless, but when it is combined with another mutation, the combination may turn out to be lethal. Such genes are said to "interact genetically". Genes that are connected in such a way form genetic interaction networks. Some of the goals of these networks are: develop a functional map of a cell's processes, drug target identification using chemoproteomics, and to predict the function of uncharacterized genes.
In 2010, the most "complete" gene interactome produced to date was compiled from about 5.4 million two-gene comparisons to describe "the interaction profiles for ~75% of all genes in the budding yeast", with ~170,000 gene interactions. The genes were grouped based on similar function so as to build a functional map of the cell's processes. Using this method the study was able to predict known gene functions better than any other genome-scale data set as well as adding functional information for genes that hadn't been previously described. From this model genetic interactions can be observed at multiple scales which will assist in the study of concepts such as gene conservation. Some of the observations made from this study are that there were twice as many negative as positive interactions, negative interactions were more informative than positive interactions, and genes with more connections were more likely to result in lethality when disrupted.[8]
Interactomics
Interactomics is a discipline at the intersection of bioinformatics and biology that deals with studying both the interactions and the consequences of those interactions between and among proteins, and other molecules within a cell.[9] Interactomics thus aims to compare such networks of interactions (i.e., interactomes) between and within species in order to find how the traits of such networks are either preserved or varied.
Interactomics is an example of "top-down" systems biology, which takes an overhead view of a biosystem or organism. Large sets of genome-wide and proteomic data are collected, and correlations between different molecules are inferred. From the data new hypotheses are formulated about feedbacks between these molecules. These hypotheses can then be tested by new experiments.[10]
Experimental methods to map interactomes
The study of interactomes is called interactomics. The basic unit of a protein network is the protein–protein interaction (PPI). While there are numerous methods to study PPIs, there are relatively few that have been used on a large scale to map whole interactomes.
The yeast two hybrid system (Y2H) is suited to explore the binary interactions among two proteins at a time. Affinity purification and subsequent mass spectrometry is suited to identify a protein complex. Both methods can be used in a high-throughput (HTP) fashion. Yeast two hybrid screens allow false positive interactions between proteins that are never expressed in the same time and place; affinity capture mass spectrometry does not have this drawback, and is the current gold standard. Yeast two-hybrid data better indicates non-specific tendencies towards sticky interactions rather while affinity capture mass spectrometry better indicates functional in vivo protein–protein interactions.[11][12]
Computational methods to study interactomes
Once an interactome has been created, there are numerous ways to analyze its properties. However, there are two important goals of such analyses. First, scientists try to elucidate the systems properties of interactomes, e.g. the topology of its interactions. Second, studies may focus on individual proteins and their role in the network. Such analyses are mainly carried out using bioinformatics methods and include the following, among many others:
Validation
First, the coverage and quality of an interactome has to be evaluated. Interactomes are never complete, given the limitations of experimental methods. For instance, it has been estimated that typical Y2H screens detect only 25% or so of all interactions in an interactome.[13] The coverage of an interactome can be assessed by comparing it to benchmarks of well-known interactions that have been found and validated by independent assays.[14] Other methods filter out false positives calculating the similarity of known annotations of the proteins involved or define a likelihood of interaction using the subcellular localization of these proteins.[15]
Predicting PPIs
Using experimental data as a starting point, homology transfer is one way to predict interactomes. Here, PPIs from one organism are used to predict interactions among homologous proteins in another organism ("interologs"). However, this approach has certain limitations, primarily because the source data may not be reliable (e.g. contain false positives and false negatives).[17] In addition, proteins and their interactions change during evolution and thus may have been lost or gained. Nevertheless, numerous interactomes have been predicted, e.g. that of Bacillus licheniformis.[18]
Some algorithms use experimental evidence on structural complexes, the atomic details of binding interfaces and produce detailed atomic models of protein–protein complexes[19][20] as well as other protein–molecule interactions.[21][22] Other algorithms use only sequence information, thereby creating unbiased complete networks of interaction with many mistakes.[23]
Some methods use machine learning to distinguish how interacting protein pairs differ from non-interacting protein pairs in terms of pairwise features such as cellular colocalization, gene co-expression, how closely located on a DNA are the genes that encode the two proteins, and so on.[16][24] Random Forest has been found to be most-effective machine learning method for protein interaction prediction.[25] Such methods have been applied for discovering protein interactions on human interactome, specifically the interactome of Membrane proteins[24] and the interactome of Schizophrenia-associated proteins.[16]
Text mining of PPIs
Some efforts have been made to extract systematically interaction networks directly from the scientific literature. Such approaches range in terms of complexity from simple co-occurrence statistics of entities that are mentioned together in the same context (e.g. sentence) to sophisticated natural language processing and machine learning methods for detecting interaction relationships.[26]
Protein function prediction
Protein interaction networks have been used to predict the function of proteins of unknown functions.[27][28] This is usually based on the assumption that uncharacterized proteins have similar functions as their interacting proteins (guilt by association). For example, YbeB, a protein of unknown function was found to interact with ribosomal proteins and later shown to be involved in bacterial and eukaryotic (but not archaeal) translation.[29] Although such predictions may be based on single interactions, usually several interactions are found. Thus, the whole network of interactions can be used to predict protein functions, given that certain functions are usually enriched among the interactors.[27] The term hypothome has been used to denote an interactome wherein at least one of the genes or proteins is a hypothetical protein.[30]
Perturbations and disease
The topology of an interactome makes certain predictions how a network reacts to the perturbation (e.g. removal) of nodes (proteins) or edges (interactions).[31] Such perturbations can be caused by mutations of genes, and thus their proteins, and a network reaction can manifest as a disease.[32] A network analysis can identify drug targets and biomarkers of diseases.[33]
Network structure and topology
Interaction networks can be analyzed using the tools of graph theory. Network properties include the degree distribution, clustering coefficients, betweenness centrality, and many others. The distribution of properties among the proteins of an interactome has revealed that the interactome networks often have scale-free topology[34] where functional modules within a network indicate specialized subnetworks.[35] Such modules can be functional, as in a signaling pathway, or structural, as in a protein complex. In fact, it is a formidable task to identify protein complexes in an interactome, given that a network on its own does not directly reveal the presence of a stable complex.
Studied interactomes
Viral interactomes
Viral protein interactomes consist of interactions among viral or phage proteins. They were among the first interactome projects as their genomes are small and all proteins can be analyzed with limited resources. Viral interactomes are connected to their host interactomes, forming virus-host interaction networks.[36] Some published virus interactomes include
Bacteriophage
- Escherichia coli bacteriophage lambda[37]
- Escherichia coli bacteriophage T7[38]
- Streptococcus pneumoniae bacteriophage Dp-1[39]
- Streptococcus pneumoniae bacteriophage Cp-1[40]
The lambda and VZV interactomes are not only relevant for the biology of these viruses but also for technical reasons: they were the first interactomes that were mapped with multiple Y2H vectors, proving an improved strategy to investigate interactomes more completely than previous attempts have shown.
Human (mammalian) viruses
- Human varicella zoster virus (VZV)[41]
- Chandipura virus[42]
- Epstein-Barr virus (EBV)[43]
- Hepatitis C virus (HPC),[44] Human-HCV interactions[45]
- Hepatitis E virus (HEV)[46]
- Herpes simplex virus 1 (HSV-1)[43]
- Kaposi's sarcoma-associated herpesvirus (KSHV)[43]
- Murine cytomegalovirus (mCMV)[43]
Bacterial interactomes
Relatively few bacteria have been comprehensively studied for their protein–protein interactions. However, none of these interactomes are complete in the sense that they captured all interactions. In fact, it has been estimated that none of them covers more than 20% or 30% of all interactions, primarily because most of these studies have only employed a single method, all of which discover only a subset of interactions.[13] Among the published bacterial interactomes (including partial ones) are
| Species | proteins total | interactions | type | reference |
| Helicobacter pylori | 1,553 | ~3,004 | Y2H | [47][48] |
| Campylobacter jejuni | 1,623 | 11,687 | Y2H | [49] |
| Treponema pallidum | 1,040 | 3,649 | Y2H | [50] |
| Escherichia coli | 4,288 | (5,993) | AP/MS | [51] |
| Escherichia coli | 4,288 | 2,234 | Y2H | [52] |
| Mesorhizobium loti | 6,752 | 3,121 | Y2H | [53] |
| Mycobacterium tuberculosis | 3,959 | >8000 | B2H | [54] |
| Mycoplasma genitalium | 482 | AP/MS | [55] | |
| Synechocystis sp. PCC6803 | 3,264 | 3,236 | Y2H | [56] |
| Staphylococcus aureus (MRSA) | 2,656 | 13,219 | AP/MS | [57] |
The E. coli and Mycoplasma interactomes have been analyzed using large-scale protein complex affinity purification and mass spectrometry (AP/MS), hence it is not easily possible to infer direct interactions. The others have used extensive yeast two-hybrid (Y2H) screens. The Mycobacterium tuberculosis interactome has been analyzed using a bacterial two-hybrid screen (B2H).
Note that numerous additional interactomes have been predicted using computational methods (see section above).
Eukaryotic interactomes
There have been several efforts to map eukaryotic interactomes through HTP methods. While no biological interactomes have been fully characterized, over 90% of proteins in Saccharomyces cerevisiae have been screened and their interactions characterized, making it the best-characterized interactome.[27][58][59] Species whose interactomes have been studied in some detail include
Recently, the pathogen-host interactomes of Hepatitis C Virus/Human (2008),[62] Epstein Barr virus/Human (2008), Influenza virus/Human (2009) were delineated through HTP to identify essential molecular components for pathogens and for their host's immune system.[63]
Predicted interactomes
As described above, PPIs and thus whole interactomes can be predicted. While the reliability of these predictions is debatable, they are providing hypotheses that can be tested experimentally. Interactomes have been predicted for a number of species, e.g.
- Human (Homo sapiens)[64]
- Rice (Oryza sativa)[65]
- Xanthomonas oryzae[66]
- Arabidopsis thaliana[67]
- Tomato (Solanum lycopersicum)[68]
- Field mustard (Brassica rapa)[69]
- Maize, corn (Zea mays)[70]
- Poplar (Populus trichocarpa)[71]
- SARS-CoV-2[72]

Network properties
Protein interaction networks can be analyzed with the same tool as other networks. In fact, they share many properties with biological or social networks. Some of the main characteristics are as follows.

Degree distribution
The degree distribution describes the number of proteins that have a certain number of connections. Most protein interaction networks show a scale-free (power law) degree distribution where the connectivity distribution P(k) ~ k−γ with k being the degree. This relationship can also be seen as a straight line on a log-log plot since, the above equation is equal to log(P(k)) ~ —y•log(k). One characteristic of such distributions is that there are many proteins with few interactions and few proteins that have many interactions, the latter being called "hubs".
Hubs
Highly connected nodes (proteins) are called hubs. Han et al.[73] have coined the term "party hub" for hubs whose expression is correlated with its interaction partners. Party hubs also connect proteins within functional modules such as protein complexes. In contrast, "date hubs" do not exhibit such a correlation and appear to connect different functional modules. Party hubs are found predominantly in AP/MS data sets, whereas date hubs are found predominantly in binary interactome network maps.[74] Note that the validity of the date hub/party hub distinction was disputed.[75][76] Party hubs generally consist of multi-interface proteins whereas date hubs are more frequently single-interaction interface proteins.[77] Consistent with a role for date-hubs in connecting different processes, in yeast the number of binary interactions of a given protein is correlated to the number of phenotypes observed for the corresponding mutant gene in different physiological conditions.[74]
Modules
Nodes involved in the same biochemical process are highly interconnected.[33]
Evolution
The evolution of interactome complexity is delineated in a study published in Nature.[78] In this study it is first noted that the boundaries between prokaryotes, unicellular eukaryotes and multicellular eukaryotes are accompanied by orders-of-magnitude reductions in effective population size, with concurrent amplifications of the effects of random genetic drift. The resultant decline in the efficiency of selection seems to be sufficient to influence a wide range of attributes at the genomic level in a nonadaptive manner. The Nature study shows that the variation in the power of random genetic drift is also capable of influencing phylogenetic diversity at the subcellular and cellular levels. Thus, population size would have to be considered as a potential determinant of the mechanistic pathways underlying long-term phenotypic evolution. In the study it is further shown that a phylogenetically broad inverse relation exists between the power of drift and the structural integrity of protein subunits. Thus, the accumulation of mildly deleterious mutations in populations of small size induces secondary selection for protein–protein interactions that stabilize key gene functions, mitigating the structural degradation promoted by inefficient selection. By this means, the complex protein architectures and interactions essential to the genesis of phenotypic diversity may initially emerge by non-adaptive mechanisms.
Criticisms, challenges, and responses
Kiemer and Cesareni[9] raise the following concerns with the state (circa 2007) of the field especially with the comparative interactomic: The experimental procedures associated with the field are error prone leading to "noisy results". This leads to 30% of all reported interactions being artifacts. In fact, two groups using the same techniques on the same organism found less than 30% interactions in common. However, some authors have argued that such non-reproducibility results from the extraordinary sensitivity of various methods to small experimental variation. For instance, identical conditions in Y2H assays result in very different interactions when different Y2H vectors are used.[13]
Techniques may be biased, i.e. the technique determines which interactions are found. In fact, any method has built in biases, especially protein methods. Because every protein is different no method can capture the properties of each protein. For instance, most analytical methods that work fine with soluble proteins deal poorly with membrane proteins. This is also true for Y2H and AP/MS technologies.
Interactomes are not nearly complete with perhaps the exception of S. cerevisiae. This is not really a criticism as any scientific area is "incomplete" initially until the methodologies have been improved. Interactomics in 2015 is where genome sequencing was in the late 1990s, given that only a few interactome datasets are available (see table above).
While genomes are stable, interactomes may vary between tissues, cell types, and developmental stages. Again, this is not a criticism, but rather a description of the challenges in the field.
It is difficult to match evolutionarily related proteins in distantly related species. While homologous DNA sequences can be found relatively easily, it is much more difficult to predict homologous interactions ("interologs") because the homologs of two interacting proteins do not need to interact. For instance, even within a proteome two proteins may interact but their paralogs may not.
Each protein–protein interactome may represent only a partial sample of potential interactions, even when a supposedly definitive version is published in a scientific journal. Additional factors may have roles in protein interactions that have yet to be incorporated in interactomes. The binding strength of the various protein interactors, microenvironmental factors, sensitivity to various procedures, and the physiological state of the cell all impact protein–protein interactions, yet are usually not accounted for in interactome studies.[79]
See also
References
- Wang L, Eftekhari P, Schachner D, Ignatova ID, Palme V, Schilcher N, Ladurner A, Heiss EH, Stangl H, Dirsch VM, Atanasov AG. Novel interactomics approach identifies ABCA1 as direct target of evodiamine, which increases macrophage cholesterol efflux. Sci Rep. 2018 Jul 23;8(1):11061. doi: 10.1038/s41598-018-29281-1.
- Hennah W, Porteous D (2009). Reif A (ed.). "The DISC1 pathway modulates expression of neurodevelopmental, synaptogenic and sensory perception genes". PLOS ONE. 4 (3): e4906. Bibcode:2009PLoSO...4.4906H. doi:10.1371/journal.pone.0004906. PMC 2654149. PMID 19300510.

- Sanchez C; Lachaize C; Janody F; et al. (January 1999). "Grasping at molecular interactions and genetic networks in Drosophila melanogaster using FlyNets, an Internet database". Nucleic Acids Res. 27 (1): 89–94. doi:10.1093/nar/27.1.89. PMC 148104. PMID 9847149.
- Sharma, Ankush; Gautam VK; Costantini S; Paladino A; Colonna G (Feb 2012). "Interactomic and pharmacological insights on human Sirt-1". Front. Pharmacol. 3: 40. doi:10.3389/fphar.2012.00040. PMC 3311038. PMID 22470339.
- Sharma, Ankush; Costantini S; Colonna G (March 2013). "The protein–protein interaction network of human Sirtuin family". Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics. 1834 (10): 1998–2009. arXiv:1302.6423. Bibcode:2013arXiv1302.6423S. doi:10.1016/j.bbapap.2013.06.012. PMID 23811471. S2CID 15003130.
- Uetz P. & Grigoriev A. (2005) The yeast interactome. In Jorde, L.B., Little, P.F.R., Dunn, M.J. and Subramaniam, S. (Eds), Encyclopedia of Genetics, Genomics, Proteomics and Bioinformatics. John Wiley & Sons Ltd: Chichester, Volume 5, pp. 2033-2051
- Stumpf MP; Thorne T; de Silva E; et al. (May 2008). "Estimating the size of the human interactome". Proc. Natl. Acad. Sci. U.S.A. 105 (19): 6959–64. Bibcode:2008PNAS..105.6959S. doi:10.1073/pnas.0708078105. PMC 2383957. PMID 18474861.
- Costanzo M; Baryshnikova A; Bellay J; et al. (2010-01-22). "The genetic landscape of a cell". Science. 327 (5964): 425–431. Bibcode:2010Sci...327..425C. doi:10.1126/science.1180823. PMC 5600254. PMID 20093466.
- Kiemer, L; G Cesareni (2007). "Comparative interactomics: comparing apples and pears?". Trends in Biotechnology. 25 (10): 448–454. doi:10.1016/j.tibtech.2007.08.002. PMID 17825444.
- Bruggeman, F J; H V Westerhoff (2006). "The nature of systems biology". Trends in Microbiology. 15 (1): 45–50. doi:10.1016/j.tim.2006.11.003. PMID 17113776.
- Brettner, Leandra M.; Joanna Masel (2012). "Protein stickiness, rather than number of functional protein–protein interactions, predicts expression noise and plasticity in yeast". BMC Systems Biology. 6: 128. doi:10.1186/1752-0509-6-128. PMC 3527306. PMID 23017156.
- Mukherjee, K; Slawson; Christmann; Griffith (June 2014). "Neuron-specific protein interactions of Drosophila CASK-ß are revealed by mass spectrometry". Front. Mol. Neurosci. 7: 58. doi:10.3389/fnmol.2014.00058. PMC 4075472. PMID 25071438.
- Chen, Y. C.; Rajagopala, S. V.; Stellberger, T.; Uetz, P. (2010). "Exhaustive benchmarking of the yeast two-hybrid system". Nature Methods. 7 (9): 667–668, author 668 668. doi:10.1038/nmeth0910-667. PMC 10332476. PMID 20805792. S2CID 35834541.
- Rajagopala, S. V.; Hughes, K. T.; Uetz, P. (2009). "Benchmarking yeast two-hybrid systems using the interactions of bacterial motility proteins". Proteomics. 9 (23): 5296–5302. doi:10.1002/pmic.200900282. PMC 2818629. PMID 19834901.
- Yanay Ofran, Guy Yachdav, Eyal Mozes, Ta-tsen Soong, Rajesh Nair & Burkhard Rost (July 2006). "Create and assess protein networks through molecular characteristics of individual proteins". Bioinformatics. 22 (14): e402–e407. doi:10.1093/bioinformatics/btl258. PMID 16873500.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Ganapathiraju MK, Thahir M, Handen A, Sarkar SN, Sweet RA, Nimgaonkar VL, Loscher CE, Bauer EM, Chaparala S (April 2016). "Schizophrenia interactome with 504 novel protein–protein interactions". npj Schizophrenia. 2: 16012. doi:10.1038/npjschz.2016.12. PMC 4898894. PMID 27336055.
- Mika S, Rost B (2006). "Protein–Protein Interactions More Conserved within Species than across Species". PLOS Computational Biology. 2 (7): e79. Bibcode:2006PLSCB...2...79M. doi:10.1371/journal.pcbi.0020079. PMC 1513270. PMID 16854211.
- Han, Y.-C.; et al. (2016). "Prediction and characterization of protein–protein interaction network in Bacillus licheniformis WX-02". Sci. Rep. 6: 19486. Bibcode:2016NatSR...619486H. doi:10.1038/srep19486. PMC 4726086. PMID 26782814.
- Kittichotirat W, Guerquin M, Bumgarner RE, Samudrala R (2009). "Protinfo PPC: A web server for atomic level prediction of protein complexes". Nucleic Acids Research. 37 (Web Server issue): W519–W525. doi:10.1093/nar/gkp306. PMC 2703994. PMID 19420059.
- Tyagi, M; Hashimoto, K; Shoemaker, B. A.; Wuchty, S; Panchenko, A. R. (Mar 2012). "Large-scale mapping of human protein interactome using structural complexes". EMBO Rep. 13 (3): 266–71. doi:10.1038/embor.2011.261. PMC 3296913. PMID 22261719.
- McDermott J, Guerquin M, Frazier Z, Chang AN, Samudrala R (2005). "BIOVERSE: Enhancements to the framework for structural, functional, and contextual annotations of proteins and proteomes". Nucleic Acids Research. 33 (Web Server issue): W324–W325. doi:10.1093/nar/gki401. PMC 1160162. PMID 15980482.
- Shoemaker, B. A.; Zhang, D; Tyagi, M; Thangudu, R. R.; Fong, J. H.; Marchler-Bauer, A; Bryant, S. H.; Madej, T; Panchenko, A. R. (Jan 2012). "IBIS (Inferred Biomolecular Interaction Server) reports, predicts and integrates multiple types of conserved interactions for proteins". Nucleic Acids Res. 40 (Database issue): D834–40. doi:10.1093/nar/gkr997. PMC 3245142. PMID 22102591. Hopf TA, Schaerfe CP, Rodrigues JP, Green AG, Kohlbacher O, Sander C, Bonvin AM, Marks DS (2014). "Sequence co-evolution gives 3D contacts and structures of protein complexes". eLife. 3: e03430. arXiv:1405.0929. Bibcode:2014arXiv1405.0929H. doi:10.7554/eLife.03430. PMC 4360534. PMID 25255213.
- Kotlyar M, Pastrello C, Pivetta F, Lo Sardo A, Cumbaa C, Li H, Naranian T, Niu Y, Ding Z, Vafaee F, Broackes-Carter F, Petschnigg J, Mills GB, Jurisicova A, Stagljar I, Maestro R, Jurisica I (2015). "In silico prediction of physical protein interactions and characterization of interactome orphans". Nature Methods. 12 (1): 79–84. doi:10.1038/nmeth.3178. PMID 25402006. S2CID 5287489. Hamp T, Rost B (2015). "Evolutionary profiles improve protein–protein interaction prediction from sequence". Bioinformatics. 31 (12): 1945–1950. doi:10.1093/bioinformatics/btv077. PMID 25657331. Pitre S, Hooshyar M, Schoenrock A, Samanfar B, Jessulat M, Green JR, Dehne F, Golshani A (2012). "Short Co-occurring Polypeptide Regions Can Predict Global Protein Interaction Maps". Scientific Reports. 2: 239. Bibcode:2012NatSR...2E.239P. doi:10.1038/srep00239. PMC 3269044. PMID 22355752. Pitre S, Hooshyar M, Schoenrock A, Samanfar B, Jessulat M, Green JR, Dehne F, Golshani A (2012). "Short co-occurring polypeptide regions can predict global protein interaction maps". Scientific Reports. 2: 239. Bibcode:2012NatSR...2E.239P. doi:10.1038/srep00239. PMC 3269044. PMID 22355752.
- Qi Y, Dhiman HK, Bhola N, Budyak I, Kar S, Man D, Dutta A, Tirupula K, Carr BI, Grandis J, Bar-Joseph Z, Klein-Seetharaman J (December 2009). "Systematic prediction of human membrane receptor interactions". Proteomics. 9 (23): 5243–55. doi:10.1002/pmic.200900259. PMC 3076061. PMID 19798668.
- Qi Y, Bar-Joseph Z, Klein-Seetharaman J (May 2006). "Evaluation of different biological data and computational classification methods for use in protein interaction prediction". Proteins. 63 (3): 490–500. doi:10.1002/prot.20865. PMC 3250929. PMID 16450363.
- Hoffmann, R; Krallinger, M; Andres, E; Tamames, J; Blaschke, C; Valencia, A (2005). "Text mining for metabolic pathways, signaling cascades, and protein networks". Science Signaling. 2005 (283): pe21. doi:10.1126/stke.2832005pe21. PMID 15886388. S2CID 15301069.
- Schwikowski, B.; Uetz, P.; Fields, S. (2000). "A network of protein–protein interactions in yeast". Nature Biotechnology. 18 (12): 1257–1261. doi:10.1038/82360. PMID 11101803. S2CID 3009359.
- McDermott J, Bumgarner RE, Samudrala R (2005). "Functional annotation from predicted protein interaction networks". Bioinformatics. 21 (15): 3217–3226. doi:10.1093/bioinformatics/bti514. PMID 15919725.
- Rajagopala, S. V.; Sikorski, P.; Caufield, J. H.; Tovchigrechko, A.; Uetz, P. (2012). "Studying protein complexes by the yeast two-hybrid system". Methods. 58 (4): 392–399. doi:10.1016/j.ymeth.2012.07.015. PMC 3517932. PMID 22841565.
- Desler C, Zambach S, Suravajhala P, Rasmussen LJ (2014). "Introducing the hypothome: a way to integrate predicted proteins in interactomes". International Journal of Bioinformatics Research and Applications. 10 (6): 647–52. doi:10.1504/IJBRA.2014.065247. PMID 25335568.
- Barab, A. -L.; Oltvai, Z. (2004). "Network biology: understanding the cell's functional organization". Nature Reviews Genetics. 5 (2): 101–113. doi:10.1038/nrg1272. PMID 14735121. S2CID 10950726.
- Goh, K. -I.; Choi, I. -G. (2012). "Exploring the human diseasome: The human disease network". Briefings in Functional Genomics. 11 (6): 533–542. doi:10.1093/bfgp/els032. PMID 23063808.
- Barabási, A. L.; Gulbahce, N; Loscalzo, J (2011). "Network medicine: A network-based approach to human disease". Nature Reviews Genetics. 12 (1): 56–68. doi:10.1038/nrg2918. PMC 3140052. PMID 21164525.
- Albert-László Barabási & Zoltan N. Oltvai (February 2004). "Network biology: understanding the cell's functional organization". Nature Reviews. Genetics. 5 (2): 101–113. doi:10.1038/nrg1272. PMID 14735121. S2CID 10950726.
- Gao, L.; Sun, P. G.; Song, J. (2009). "Clustering algorithms for detecting functional modules in protein interaction networks". Journal of Bioinformatics and Computational Biology. 7 (1): 217–242. doi:10.1142/S0219720009004023. PMID 19226668.
- Navratil V.; et al. (2009). "VirHostNet: a knowledge base for the management and the analysis of proteome-wide virus-host interaction networks". Nucleic Acids Res. 37 (Database issue): D661–8. doi:10.1093/nar/gkn794. PMC 2686459. PMID 18984613.
- Rajagopala SV.; et al. (2011). "The protein interaction map of bacteriophage lambda". BMC Microbiol. 11: 213. doi:10.1186/1471-2180-11-213. PMC 3224144. PMID 21943085.
- Bartel PL, Roecklein JA, SenGupta D, Fields S (1996). "A protein linkage map of Escherichia coli bacteriophage T7". Nat. Genet. 12 (1): 72–7. doi:10.1038/ng0196-72. PMID 8528255. S2CID 37155819.
- Sabri M.; et al. (2011). "Genome annotation and intraviral interactome for the Streptococcus pneumoniae virulent phage Dp-1". J. Bacteriol. 193 (2): 551–62. doi:10.1128/JB.01117-10. PMC 3019816. PMID 21097633.
- Häuser R.; et al. (2011). "The proteome and interactome of Streptococcus pneumoniae phage Cp-1". J. Bacteriol. 193 (12): 3135–8. doi:10.1128/JB.01481-10. PMC 3133188. PMID 21515781.
- Stellberger, T.; et al. (2010). "Improving the yeast two-hybrid system with permutated fusions proteins: the Varicella Zoster Virus interactome". Proteome Sci. 8: 8. doi:10.1186/1477-5956-8-8. PMC 2832230. PMID 20205919.
- Kumar, K.; Rana, J.; Sreejith, R.; Gabrani, R.; Sharma, S. K.; Gupta, A.; Chaudhary, V. K.; Gupta, S. (2012). "Intraviral protein interactions of Chandipura virus". Archives of Virology. 157 (10): 1949–1957. doi:10.1007/s00705-012-1389-5. PMID 22763614. S2CID 17714252.
- Fossum, E; et al. (2009). Sun, Ren (ed.). "Evolutionarily conserved herpesviral protein interaction networks". PLOS Pathog. 5 (9): e1000570. doi:10.1371/journal.ppat.1000570. PMC 2731838. PMID 19730696.
- Hagen, N; Bayer, K; Roesch, K; Schindler, M (2014). "The intra viral protein interaction network of hepatitis C virus". Molecular & Cellular Proteomics. 13 (7): 1676–89. doi:10.1074/mcp.M113.036301. PMC 4083108. PMID 24797426.
- Han, Y; Niu, J; Wang, D; Li, Y (2016). "Hepatitis C Virus Protein Interaction Network Analysis Based on Hepatocellular Carcinoma". PLOS ONE. 11 (4): e0153882. Bibcode:2016PLoSO..1153882H. doi:10.1371/journal.pone.0153882. PMC 4846009. PMID 27115606.
- Osterman A, Stellberger T, Gebhardt A, Kurz M, Friedel CC, Uetz P, Nitschko H, Baiker A, Vizoso-Pinto MG (2015). "The Hepatitis E virus intraviral interactome". Sci Rep. 5: 13872. Bibcode:2015NatSR...513872O. doi:10.1038/srep13872. PMC 4604457. PMID 26463011.
- Rain, J. C.; Selig, L.; De Reuse, H.; Battaglia, V. R.; Reverdy, C. L.; Simon, S. P.; Lenzen, G.; Petel, F.; Wojcik, J. R. M.; Schächter, V.; Chemama, Y.; Labigne, A. S.; Legrain, P. (2001). "The protein–protein interaction map of Helicobacter pylori". Nature. 409 (6817): 211–215. Bibcode:2001Natur.409..211R. doi:10.1038/35051615. PMID 11196647. S2CID 4400094.
- Häuser, R; Ceol, A; Rajagopala, S. V.; Mosca, R; Siszler, G; Wermke, N; Sikorski, P; Schwarz, F; Schick, M; Wuchty, S; Aloy, P; Uetz, P (2014). "A Second-generation Protein–Protein Interaction Network of Helicobacter pylori". Molecular & Cellular Proteomics. 13 (5): 1318–29. doi:10.1074/mcp.O113.033571. PMC 4014287. PMID 24627523.
- Parrish, JR; et al. (2007). "A proteome-wide protein interaction map for Campylobacter jejuni". Genome Biol. 8 (7): R130. doi:10.1186/gb-2007-8-7-r130. PMC 2323224. PMID 17615063.
- Rajagopala, S. V.; Titz, B. R.; Goll, J.; Häuser, R.; McKevitt, M. T.; Palzkill, T.; Uetz, P. (2008). Hall, Neil (ed.). "The Binary Protein Interactome of Treponema pallidum – the Syphilis Spirochete". PLOS ONE. 3 (5): e2292. Bibcode:2008PLoSO...3.2292T. doi:10.1371/journal.pone.0002292. PMC 2386257. PMID 18509523.
- Hu, P; et al. (2009). Levchenko, Andre (ed.). "Global functional atlas of Escherichia coli encompassing previously uncharacterized proteins". PLOS Biol. 7 (4): e96. doi:10.1371/journal.pbio.1000096. PMC 2672614. PMID 19402753.
- Rajagopala, S. V.; Sikorski, P; Kumar, A; Mosca, R; Vlasblom, J; Arnold, R; Franca-Koh, J; Pakala, S. B.; Phanse, S; Ceol, A; Häuser, R; Siszler, G; Wuchty, S; Emili, A; Babu, M; Aloy, P; Pieper, R; Uetz, P (2014). "The binary protein–protein interaction landscape of Escherichia coli". Nature Biotechnology. 32 (3): 285–90. doi:10.1038/nbt.2831. PMC 4123855. PMID 24561554.
- Shimoda, Y.; Shinpo, S.; Kohara, M.; Nakamura, Y.; Tabata, S.; Sato, S. (2008). "A Large Scale Analysis of Protein–Protein Interactions in the Nitrogen-fixing Bacterium Mesorhizobium loti". DNA Research. 15 (1): 13–23. doi:10.1093/dnares/dsm028. PMC 2650630. PMID 18192278.
- Wang, Y.; Cui, T.; Zhang, C.; Yang, M.; Huang, Y.; Li, W.; Zhang, L.; Gao, C.; He, Y.; Li, Y.; Huang, F.; Zeng, J.; Huang, C.; Yang, Q.; Tian, Y.; Zhao, C.; Chen, H.; Zhang, H.; He, Z. G. (2010). "Global Protein−Protein Interaction Network in the Human PathogenMycobacterium tuberculosisH37Rv". Journal of Proteome Research. 9 (12): 6665–6677. doi:10.1021/pr100808n. PMID 20973567.
- Kuhner, S.; Van Noort, V.; Betts, M. J.; Leo-Macias, A.; Batisse, C.; Rode, M.; Yamada, T.; Maier, T.; Bader, S.; Beltran-Alvarez, P.; Castaño-Diez, D.; Chen, W. -H.; Devos, D.; Güell, M.; Norambuena, T.; Racke, I.; Rybin, V.; Schmidt, A.; Yus, E.; Aebersold, R.; Herrmann, R.; Böttcher, B.; Frangakis, A. S.; Russell, R. B.; Serrano, L.; Bork, P.; Gavin, A. -C. (2009). "Proteome Organization in a Genome-Reduced Bacterium". Science. 326 (5957): 1235–1240. Bibcode:2009Sci...326.1235K. doi:10.1126/science.1176343. PMID 19965468. S2CID 19334426.
- Sato, S.; Shimoda, Y.; Muraki, A.; Kohara, M.; Nakamura, Y.; Tabata, S. (2007). "A Large-scale Protein protein Interaction Analysis in Synechocystis sp. PCC6803". DNA Research. 14 (5): 207–216. doi:10.1093/dnares/dsm021. PMC 2779905. PMID 18000013.
- Cherkasov, A; Hsing, M; Zoraghi, R; Foster, L. J.; See, R. H.; Stoynov, N; Jiang, J; Kaur, S; Lian, T; Jackson, L; Gong, H; Swayze, R; Amandoron, E; Hormozdiari, F; Dao, P; Sahinalp, C; Santos-Filho, O; Axerio-Cilies, P; Byler, K; McMaster, W. R.; Brunham, R. C.; Finlay, B. B.; Reiner, N. E. (2011). "Mapping the protein interaction network in methicillin-resistant Staphylococcus aureus". Journal of Proteome Research. 10 (3): 1139–50. doi:10.1021/pr100918u. PMID 21166474.
- Uetz, P.; Giot, L.; Cagney, G.; Mansfield, T. A.; Judson, R. S.; Knight, J. R.; Lockshon, D.; Narayan, V. (2000). "A comprehensive analysis of protein–protein interactions in Saccharomyces cerevisiae". Nature. 403 (6770): 623–627. Bibcode:2000Natur.403..623U. doi:10.1038/35001009. PMID 10688190. S2CID 4352495.
- Krogan, NJ; et al. (2006). "Global landscape of protein complexes in the yeast Saccharomyeses Cerivisiae ". Nature. 440 (7084): 637–643. Bibcode:2006Natur.440..637K. doi:10.1038/nature04670. PMID 16554755. S2CID 72422.
- Pancaldi V, Saraç OS, Rallis C, McLean JR, Převorovský M, Gould K, Beyer A, Bähler J (2012). "Predicting the fission yeast protein interaction network". G3: Genes, Genomes, Genetics. 2 (4): 453–67. doi:10.1534/g3.111.001560. PMC 3337474. PMID 22540037.
- Vo, T.V.; et al. (2016). "A Proteome-wide Fission Yeast Interactome Reveals Network Evolution Principles from Yeasts to Human". Cell. 164 (1–2): 310–323. doi:10.1016/j.cell.2015.11.037. PMC 4715267. PMID 26771498.
- de Chassey B; Navratil V; Tafforeau L; et al. (2008-11-04). "Hepatitis C virus infection protein network". Molecular Systems Biology. 4 (4): 230. doi:10.1038/msb.2008.66. PMC 2600670. PMID 18985028.
- Navratil V; de Chassey B; et al. (2010-11-05). "Systems-level comparison of protein–protein interactions between viruses and the human type I interferon system network". Journal of Proteome Research. 9 (7): 3527–36. doi:10.1021/pr100326j. PMID 20459142.
- Brown KR, Jurisica I (2005). "Online predicted human interaction database". Bioinformatics. 21 (9): 2076–82. doi:10.1093/bioinformatics/bti273. PMID 15657099.
- Gu H, Zhu P, Jiao Y, Meng Y, Chen M (2011). "PRIN: a predicted rice interactome network". BMC Bioinformatics. 12: 161. doi:10.1186/1471-2105-12-161. PMC 3118165. PMID 21575196.
- Guo J, Li H, Chang JW, Lei Y, Li S, Chen LL (2013). "Prediction and characterization of protein–protein interaction network in Xanthomonas oryzae pv. oryzae PXO99 A". Res. Microbiol. 164 (10): 1035–44. doi:10.1016/j.resmic.2013.09.001. PMID 24113387.
- Geisler-Lee J, O'Toole N, Ammar R, Provart NJ, Millar AH, Geisler M (2007). "A predicted interactome for Arabidopsis". Plant Physiol. 145 (2): 317–29. doi:10.1104/pp.107.103465. PMC 2048726. PMID 17675552.
- Yue, Junyang; Xu, Wei; Ban, Rongjun; Huang, Shengxiong; Miao, Min; Tang, Xiaofeng; Liu, Guoqing; Liu, Yongsheng (2016-01-01). "PTIR: Predicted Tomato Interactome Resource". Scientific Reports. 6: 25047. Bibcode:2016NatSR...625047Y. doi:10.1038/srep25047. ISSN 2045-2322. PMC 4848565. PMID 27121261.
- Yang, Jianhua; Osman, Kim; Iqbal, Mudassar; Stekel, Dov J.; Luo, Zewei; Armstrong, Susan J.; Franklin, F. Chris H. (2012-01-01). "Inferring the Brassica rapa Interactome Using Protein–Protein Interaction Data from Arabidopsis thaliana". Frontiers in Plant Science. 3: 297. doi:10.3389/fpls.2012.00297. ISSN 1664-462X. PMC 3537189. PMID 23293649.
- Zhu, Guanghui; Wu, Aibo; Xu, Xin-Jian; Xiao, Pei-Pei; Lu, Le; Liu, Jingdong; Cao, Yongwei; Chen, Luonan; Wu, Jun (2016-02-01). "PPIM: A Protein–Protein Interaction Database for Maize". Plant Physiology. 170 (2): 618–626. doi:10.1104/pp.15.01821. ISSN 1532-2548. PMC 4734591. PMID 26620522.
- Rodgers-Melnick, Eli; Culp, Mark; DiFazio, Stephen P. (2013-01-01). "Predicting whole genome protein interaction networks from primary sequence data in model and non-model organisms using ENTS". BMC Genomics. 14: 608. doi:10.1186/1471-2164-14-608. ISSN 1471-2164. PMC 3848842. PMID 24015873.
- Guzzi PH, Mercatelli D, Ceraolo C, Giorgi FM (2020). "Master Regulator Analysis of the SARS-CoV-2/Human Interactome". Journal of Clinical Medicine. 9 (4): 982–988. doi:10.3390/jcm9040982. PMC 7230814. PMID 32244779.
- Han, J. D.; Bertin, N; Hao, T; Goldberg, D. S.; Berriz, G. F.; Zhang, L. V.; Dupuy, D; Walhout, A. J.; Cusick, M. E.; Roth, F. P.; Vidal, M (2004). "Evidence for dynamically organized modularity in the yeast protein–protein interaction network". Nature. 430 (6995): 88–93. Bibcode:2004Natur.430...88H. doi:10.1038/nature02555. PMID 15190252. S2CID 4426721.
- Yu, H; Braun, P; Yildirim, M. A.; Lemmens, I; Venkatesan, K; Sahalie, J; Hirozane-Kishikawa, T; Gebreab, F; Li, N; Simonis, N; Hao, T; Rual, J. F.; Dricot, A; Vazquez, A; Murray, R. R.; Simon, C; Tardivo, L; Tam, S; Svrzikapa, N; Fan, C; De Smet, A. S.; Motyl, A; Hudson, M. E.; Park, J; Xin, X; Cusick, M. E.; Moore, T; Boone, C; Snyder, M; Roth, F. P. (2008). "High-quality binary protein interaction map of the yeast interactome network". Science. 322 (5898): 104–10. Bibcode:2008Sci...322..104Y. doi:10.1126/science.1158684. PMC 2746753. PMID 18719252.
- Batada, N. N.; Reguly, T; Breitkreutz, A; Boucher, L; Breitkreutz, B. J.; Hurst, L. D.; Tyers, M (2006). "Stratus not altocumulus: A new view of the yeast protein interaction network". PLOS Biology. 4 (10): e317. doi:10.1371/journal.pbio.0040317. PMC 1569888. PMID 16984220.
- Bertin, N; Simonis, N; Dupuy, D; Cusick, M. E.; Han, J. D.; Fraser, H. B.; Roth, F. P.; Vidal, M (2007). "Confirmation of organized modularity in the yeast interactome". PLOS Biology. 5 (6): e153. doi:10.1371/journal.pbio.0050153. PMC 1892830. PMID 17564493.
- Kim, P. M.; Lu, L. J.; Xia, Y; Gerstein, M. B. (2006). "Relating three-dimensional structures to protein networks provides evolutionary insights". Science. 314 (5807): 1938–41. Bibcode:2006Sci...314.1938K. doi:10.1126/science.1136174. PMID 17185604. S2CID 2489619.
- Fernandez, A; M Lynch (2011). "Non-adaptive origins of interactome complexity". Nature. 474 (7352): 502–505. doi:10.1038/nature09992. PMC 3121905. PMID 21593762.
- Welch, G. Rickey (January 2009). "The 'fuzzy' interactome". Trends in Biochemical Sciences. 34 (1): 1–2. doi:10.1016/j.tibs.2008.10.007. PMID 19028099.
Further reading
- Park J, Lappe M, Teichmann SA (Mar 2001). "Mapping protein family interactions: intramolecular and intermolecular protein family interaction repertoires in the PDB and yeast". J Mol Biol. 307 (3): 929–38. doi:10.1006/jmbi.2001.4526. PMID 11273711.
External links
Interactome web servers
- Protinfo PPC predicts the atomic 3D structure of protein protein complexes.Kittichotirat W, Guerquin M, Bumgarner R, Samudrala R (2009). "Protinfo PPC: A web server for atomic level prediction of protein complexes". Nucleic Acids Research. 37 (Web Server issue): W519–W525. doi:10.1093/nar/gkp306. PMC 2703994. PMID 19420059.
- IBIS (server) reports, predicts and integrates multiple types of conserved interactions for proteins.
Interactome visualization tools
- GPS-Prot Web-based data visualization for protein interactions
- PINV - Protein Interaction Network Visualizer
Interactome databases
- BioGRID database
- mentha the interactome browser Calderone; et al. (2013). "mentha: a resource for browsing integrated protein-interaction networks". Nature Methods. 10 (8): 690–691. doi:10.1038/nmeth.2561. PMID 23900247. S2CID 9733108.
- IntAct: The Molecular Interaction Database
- Interactome.org — a dedicated interactome web site.