Essential gene
Essential genes are indispensable genes for organisms to grow and reproduce offspring under certain environment.[1] However, being essential is highly dependent on the circumstances in which an organism lives. For instance, a gene required to digest starch is only essential if starch is the only source of energy. Recently, systematic attempts have been made to identify those genes that are absolutely required to maintain life, provided that all nutrients are available.[2] Such experiments have led to the conclusion that the absolutely required number of genes for bacteria is on the order of about 250–300. Essential genes of single-celled organisms encode proteins for three basic functions including genetic information processing, cell envelopes and energy production.[1] Those gene functions are used to maintain a central metabolism, replicate DNA, translate genes into proteins, maintain a basic cellular structure, and mediate transport processes into and out of the cell. Compared with single-celled organisms, multicellular organisms have more essential genes related to communication and development. Most of the essential genes in viruses are related to the processing and maintenance of genetic information. In contrast to most single-celled organisms, viruses lack many essential genes for metabolism,[1] which forces them to hijack the host's metabolism. Most genes are not essential but convey selective advantages and increased fitness. Hence, the vast majority of genes are not essential and many can be deleted without consequences, at least under most circumstances.
Bacteria: genome-wide studies
Two main strategies have been employed to identify essential genes on a genome-wide basis: directed deletion of genes and random mutagenesis using transposons. In the first case, annotated individual genes (or ORFs) are completely deleted from the genome in a systematic way. In transposon-mediated mutagenesis, transposons are randomly inserted in as many positions in a genome as possible, aiming to disrupt the function of the targeted genes (see figure below). Insertion mutants that are still able to survive or grow suggest the transposon inserted in a gene that is not essential for survival. The location of the transposon insertions can be determined through hybridization to microarrays [3] or through transposon sequencing . With the development of CRISPR, gene essentiality has also been determined through inhibition of gene expression through CRISPR interference. A summary of such screens is shown in the table.[2][4]
| Organism | Mutagenesis | Method | Readout | ORFs | Non-ess. | Essential | % Ess. | Notes | Ref. |
|---|---|---|---|---|---|---|---|---|---|
| Mycoplasma genitalium/pneumoniae | Random | Population | Sequencing | 482 | 130 | 265–350 | 55–73% | --- | [5] |
| Mycoplasma genitalium | Random | Clones | Sequencing | 482 | 100 | 382 | 79% | b,c | [6] |
| Staphylococcus aureus WCUH29 | Random | Clones | Sequencing | 2,600 | n/a | 168 | n/a | b,c | [7] |
| Staphylococcus aureus RN4220 | Random | Clones | Sequencing | 2,892 | n/a | 658 | 23% | --- | [8] |
| Haemophilus influenzae Rd | Random | Population | Footprint-PCR | 1,657 | 602 | 670 | 40% | --- | [9] |
| Streptococcus pneumoniae Rx-1 | Targeted | Clones | Colony formation | 2,043 | 234 | 113 | n/a | c | [10] |
| Streptococcus pneumoniae D39 | Targeted | Clones | Colony formation | 2,043 | 560 | 133 | n/a | c | [11] |
| Streptococcus pyogenes 5448 | Random | Transposon | Tn-seq | 1,865 | ? | 227 | 12% | --- | [12] |
| Streptococcus pyogenes NZ131 | Random | Transposon | Tn-seq | 1,700 | ? | 241 | 14% | --- | [12] |
| Streptococcus sanguinis SK36 | Targeted | Clones | Colony formation | 2,270 | 2,052 | 218 | 10% | a,j | [1][13] |
| Mycobacterium tuberculosis H37Rv | Random | Population | Microarray | 3,989 | 2,567 | 614 | 15% | --- | [14] |
| Mycobacterium tuberculosis | Random | Transposon | ? | 3,989 | ? | 401 | 10% | --- | [15] |
| Mycobacterium tuberculosis H37Rv | Random | Transposon | NG-Sequencing | 3,989 | ? | 774 | 19% | --- | [16][17] |
| Mycobacterium tuberculosis H37Rv | Random | Transposon | NG-Sequencing | 3,989 | 3,364 | 625 | 16% | h,i | [18] |
| Mycobacterium tuberculosis | --- | Computational | Computational | 3,989 | ? | 283 | 7% | --- | [19] |
| Mycobacterium tuberculosis H37Rv | Targeted | CRISPRi | NG-Sequencing | 4,052 | 33,15 | 737 | 18% | --- | [20] |
| Bacillus subtilis 168 | Targeted | Clones | Colony formation | 4,105 | 3,830 | 261 | 7% | a,d,g | [21][22] |
| Escherichia coli K-12 MG1655 | Random | Population | Footprint-PCR | 4,308 | 3,126 | 620 | 14% | --- | [23] |
| Escherichia coli K-12 MG1655 | Targeted | Clones | Colony formation | 4,308 | 2,001 | n/a | n/a | a,e | [24] |
| Escherichia coli K-12 BW25113 | Targeted | Clones | Colony formation | 4,390 | 3,985 | 303 | 7% | a | [25] |
| Pseudomonas aeruginosa PAO1 | Random | Clones | Sequencing | 5,570 | 4,783 | 678 | 12% | a | [26] |
| Porphyromonas gingivalis | Random | Transposon | Sequencing | 1,990 | 1,527 | 463 | 23% | --- | [27] |
| Pseudomonas aeruginosa PA14 | Random | Clones | Sequencing | 5,688 | 4,469 | 335 | 6% | a,f | [28] |
| Salmonella typhimurium | Random | Clones | Sequencing | 4,425 | n/a | 257 | ~11% | b,c | [29] |
| Helicobacter pylori G27 | Random | Population | Microarray | 1,576 | 1,178 | 344 | 22% | --- | [30] |
| Corynebacterium glutamicum | Random | Population | ? | 3,002 | 2,352 | 650 | 22% | --- | [31] |
| Francisella novicida | Random | Transposon | ? | 1,719 | 1,327 | 392 | 23% | --- | [32] |
| Mycoplasma pulmonis UAB CTIP | Random | Transposon | ? | 782 | 472 | 310 | 40% | --- | [35] |
| Vibrio cholerae N16961 | Random | Transposon | ? | 3,890 | ? | 779 | 20% | --- | [36] |
| Salmonella Typhi | Random | Transposon | ? | 4,646 | ? | 353 | 8% | --- | [37] |
| Staphylococcus aureus | Random | Transposon | ? | ~2,600 | ? | 351 | 14% | --- | [38] |
| Caulobacter crescentus | Random | Transposon | Tn-Seq | 3,876 | 3,240 | 480 | 12.2% | --- | [39] |
| Neisseria meningitidis | Random | Transposon | ? | 2,158 | ? | 585 | 27% | --- | [40] |
| Desulfovibrio alaskensis | Random | Transposon | Sequencing | 3,258 | 2,871 | 387 | 12% | --- | [41] |
Table 1. Essential genes in bacteria. Mutagenesis: targeted mutants are gene deletions; random mutants are transposon insertions. Methods: Clones indicate single gene deletions, population indicates whole population mutagenesis, e.g. using transposons. Essential genes from population screens include genes essential for fitness (see text). ORFs: number of all open reading frames in that genome. Notes: (a) mutant collection available; (b) direct essentiality screening method (e.g. via antisense RNA) that does not provide information about nonessential genes. (c) Only partial dataset available. (d) Includes predicted gene essentiality and data compilation from published single-gene essentiality studies. (e) Project in progress. (f) Deduced by comparison of the two gene essentiality datasets obtained independently in the P. aeruginosa strains PA14 and PAO1. (g) The original result of 271 essential genes has been corrected to 261, with 31 genes that were thought to be essential being in fact non-essential whereas 20 novel essential genes have been described since then.[22] (h) Counting genes with essential domains and those that lead to growth-defects when disrupted as essential, and those who lead to growth-advantage when disrupted as non-essential. (i) Involved a fully saturated mutant library of 14 replicates, with 84.3% of possible insertion sites with at least one transposon insertion. (j) Each essential gene has been independently confirmed at least five times.
On the basis of genome-wide experimental studies and systems biology analysis, an essential gene database has been developed by Kong et al. (2019) for predicting > 4000 bacterial species.[42]
Eukaryotes
In Saccharomyces cerevisiae (budding yeast) 15-20% of all genes are essential. In Schizosaccharomyces pombe (fission yeast) 4,836 heterozygous deletions covering 98.4% of the 4,914 protein coding open reading frames have been constructed. 1,260 of these deletions turned out to be essential.[43]
Similar screens are more difficult to carry out in other multicellular organisms, including mammals (as a model for humans), due to technical reasons, and their results are less clear. However, various methods have been developed for the nematode worm C. elegans,[44] the fruit fly,[45] and zebrafish[46] (see table). A recent study of 900 mouse genes concluded that 42% of them were essential although the selected genes were not representative.[47]
Gene knockout experiments are not possible or at least not ethical in humans. However, natural mutations have led to the identification of mutations that lead to early embryonic or later death.[48] Note that many genes in humans are not absolutely essential for survival but can cause severe disease when mutated. Such mutations are catalogued in the Online Mendelian Inheritance in Man (OMIM) database. In a computational analysis of genetic variation and mutations in 2,472 human orthologs of known essential genes in the mouse, Georgi et al. found strong, purifying selection and comparatively reduced levels of sequence variation, indicating that these human genes are essential too.[49]
While it may be difficult to prove that a gene is essential in humans, it can be demonstrated that a gene is not essential or not even causing disease. For instance, sequencing the genomes of 2,636 Icelandic citizens and the genotyping of 101,584 additional subjects found 8,041 individuals who had 1 gene completely knocked out (i.e. these people were homozygous for a non-functional gene).[50] Of the 8,041 individuals with complete knock-outs, 6,885 were estimated to be homozygotes, 1,249 were estimated to be compound heterozygotes (i.e. they had both alleles of a gene knocked out but the two alleles had different mutations). In these individuals, a total of 1,171 of the 19,135 human (RefSeq) genes (6.1%) were completely knocked out. It was concluded that these 1,171 genes are non-essential in humans — at least no associated diseases were reported.[50] Similarly, the exome sequences of 3222 British Pakistani-heritage adults with high parental relatedness revealed 1111 rare-variant homozygous genotypes with predicted loss of gene function (LOF = knockouts) in 781 genes.[51] This study found an average of 140 predicted LOF genotypes (per subject), including 16 rare (minor allele frequency <1%) heterozygotes, 0.34 rare homozygotes, 83.2 common heterozygotes and 40.6 common homozygotes. Nearly all rare homozygous LOF genotypes were found within autozygous segments (94.9%).[51] Even though most of these individuals had no obvious health issue arising from their defective genes, it is possible that minor health issues may be found upon more detailed examination.
A summary of essentiality screens is shown in the table below (mostly based on the Database of Essential Genes.[52]
| Organism | Method | Essential genes | Ref. |
| Arabidopsis thaliana | T-DNA insertion | 777 | [53] |
| Caenorhabditis elegans (worm) | RNA interference | 294 | [44] |
| Danio rerio (zebrafish) | Insertion mutagenesis | 288 | [46] |
| Drosophila melanogaster (fruit fly) | P-element insertion mutagenesis | 339 | [45] |
| Homo sapiens (human) | Literature search | 118 | [48] |
| Homo sapiens (human) | CRISPR/Cas9-based screen | 1,878 | [54] |
| Homo sapiens (human) | Haploid gene-trap screen | ~2,000 | [55] |
| Homo sapiens (human) | mouse orthologs | 2,472 | [56] |
| Mus musculus (mouse) | Literature search | 2114 | [57] |
| Saccharomyces cerevisiae (yeast) | Single-gene deletions | 878 | [58] |
| Saccharomyces cerevisiae (yeast) | Single-gene deletions | 1,105 | [59] |
| Schizosaccharomyces pombe (yeast) | Single-gene deletions | 1,260 | [43] |
Viruses
Viruses lack many genes necessary for metabolism,[1] forcing them to hijack the host's metabolism. Screens for essential genes have been carried out in a few viruses. For instance, human cytomegalovirus (CMV) was found to have 41 essential, 88 nonessential, and 27 augmenting ORFs (150 total ORFs). Most essential and augmenting genes are located in the central region, and nonessential genes generally cluster near the ends of the viral genome.[60]
Tscharke and Dobson (2015) compiled a comprehensive survey of essential genes in Vaccinia Virus and assigned roles to each of the 223 ORFs of the Western Reserve (WR) strain and 207 ORFs of the Copenhagen strain, assessing their role in replication in cell culture. According to their definition, a gene is considered essential (i.e. has a role in cell culture) if its deletion results in a decrease in virus titre of greater than 10-fold in either a single or multiple step growth curve. All genes involved in wrapped virion production, actin tail formation, and extracellular virion release were also considered as essential. Genes that influence plaque size, but not replication were defined as non-essential. By this definition 93 genes are required for Vaccinia Virus replication in cell culture, while 108 and 94 ORFs, from WR and Copenhagen respectively, are non-essential.[61] Vaccinia viruses with deletions at either end of the genome behaved as expected, exhibiting only mild or host range defects. In contrast, combining deletions at both ends of the genome for VACV strain WR caused a devastating growth defect on all cell lines tested. This demonstrates that single gene deletions are not sufficient to assess the essentiality of genes and that more genes are essential in Vaccinia virus than originally thought.[61]
One of the bacteriophages screened for essential genes includes mycobacteriophage Giles. At least 35 of the 78 predicted Giles genes (45%) are non-essential for lytic growth. 20 genes were found to be essential.[62] A major problem with phage genes is that a majority of their genes remain functionally unknown, hence their role is difficult to assess. A screen of Salmonella enterica phage SPN3US revealed 13 essential genes although it remains a bit obscure how many genes were really tested.[63]
Quantitative gene essentiality analysis
In theory, essential genes are qualitative.[1] However, depending on the surrounding environment, certain essential gene mutants may show partial functions, which can be quantitatively determined in some studies. For instance, a particular gene deletion may reduce growth rate (or fertility rate or other characters) to 90% of the wild-type. If there are isozymes or alternative pathways for the essential genes, they can be deleted completely.[1] Using CRISPR interference, the expression of essential genes can be modulated or "tuned", leading to quantitative (or continuous) relationships between the level of gene-expression and the magnitude of fitness cost exhibited by a given mutant.[20]
Synthetic lethality
Two genes are synthetic lethal if neither one is essential but when both are mutated the double-mutant is lethal. Some studies have estimated that the number of synthetic lethal genes may be on the order of 45% of all genes.[64][65]
Conditionally essential genes

Many genes are essential only under certain circumstances. For instance, if the amino acid lysine is supplied to a cell any gene that is required to make lysine is non-essential. However, when there is no lysine supplied, genes encoding enzymes for lysine biosynthesis become essential, as no protein synthesis is possible without lysine.[4]
Streptococcus pneumoniae appears to require 147 genes for growth and survival in saliva,[66] more than the 113-133 that have been found in previous studies.
The deletion of a gene may result in death or in a block of cell division. While the latter case may implicate "survival" for some time, without cell division the cell may still die eventually. Similarly, instead of blocked cell division a cell may have reduced growth or metabolism ranging from nearly undetectable to almost normal. Thus, there is gradient from "essential" to completely non-essential, again depending on the condition. Some authors have thus distinguished between genes "essential for survival" and "essential for fitness".[4]
The role of genetic background. Similar to environmental conditions, the genetic background can determine the essentiality of a gene: a gene may be essential in one individual but not another, given his or her genetic background. Gene duplications are one possible explanation (see below).
Metabolic dependency. Genes involved in certain biosynthetic pathways, such as amino acid synthesis, can become non-essential if one or more amino acids are supplied by culture medium[1] or by another organism.[67] This is the main reason why many parasites (e.g. Cryptosporidium hominis)[68] or endosymbiontic bacteria lost many genes (e.g. Chlamydia). Such genes may be essential but only present in the host organism. For instance, Chlamydia trachomatis cannot synthesize purine and pyrimidine nucleotides de novo, so these bacteria are dependent on the nucleotide biosynthetic genes of the host.[69]
Another kind of metabolic dependency, unrelated to cross-species interactions, can be found when bacteria are grown under specific nutrient conditions. For example, more than 100 genes become essential when Escherichia coli is grown on nutrient-limited media. Specifically, isocitrate dehydrogenase (icd) and citrate synthase (gltA) are two enzymes that are part of the tricarboxylic acid (TCA) cycle. Both genes are essential in M9 minimal media (which provides only the most basic nutrients). However, when the media is supplementing with 2-oxoglutarate or glutamate, these genes are not essential any more.[70]
Gene duplications and alternative metabolic pathways
Many genes are duplicated within a genome and many organisms have different metabolic pathways (alternative metabolic pathway[1]) to synthesis same products. Such duplications (paralogs) and alternative metabolic pathways often render essential genes non-essential because the duplicate can replace the original copy. For instance, the gene encoding the enzyme aspartokinase is essential in E. coli. By contrast, the Bacillus subtilis genome contains three copies of this gene, none of which is essential on its own. However, a triple-deletion of all three genes is lethal. In such cases, the essentiality of a gene or a group of paralogs can often be predicted based on the essentiality of an essential single gene in a different species. In yeast, few of the essential genes are duplicated within the genome: 8.5% of the non-essential genes, but only 1% of the essential genes have a homologue in the yeast genome.[59]
In the worm C. elegans, non-essential genes are highly over-represented among duplicates, possibly because duplication of essential genes causes overexpression of these genes. Woods et al. found that non-essential genes are more often successfully duplicated (fixed) and lost compared to essential genes. By contrast, essential genes are less often duplicated but upon successful duplication are maintained over longer periods.[71]
Conservation
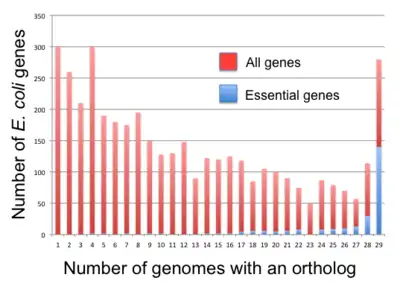
In bacteria, essential genes appear to be more conserved than nonessential genes [73] but the correlation is not very strong. For instance, only 34% of the B. subtilis essential genes have reliable orthologs in all Bacillota and 61% of the E. coli essential genes have reliable orthologs in all Gamma-proteobacteria.[72] Fang et al. (2005) defined persistent genes as the genes present in more than 85% of the genomes of the clade.[72] They found 475 and 611 of such genes for B. subtilis and E. coli, respectively. Furthermore, they classified genes into five classes according to persistence and essentiality: persistent genes, essential genes, persistent nonessential (PNE) genes (276 in B. subtilis, 409 in E. coli), essential nonpersistent (ENP) genes (73 in B. subtilis, 33 in E. coli), and nonpersistent nonessential (NPNE) genes (3,558 in B. subtilis, 3,525 in E. coli). Fang et al. found 257 persistent genes, which exist both in B. subtilis (for the Bacillota) and E. coli (for the Gamma-proteobacteria). Among these, 144 (respectively 139) were previously identified as essential in B. subtilis (respectively E. coli) and 25 (respectively 18) of the 257 genes are not present in the 475 B. subtilis (respectively 611 E. coli) persistent genes. All the other members of the pool are PNE genes.[72]
In eukaryotes, 83% of the one-to-one orthologs between Schizosaccharomyces pombe and Saccharomyces cerevisiae have conserved essentiality, that is, they are nonessential in both species or essential in both species. The remaining 17% of genes are nonessential in one species and essential in the other.[74] This is quite remarkable, given that S. pombe is separated from S. cerevisiae by approximately 400 million years of evolution.[75]
In general, highly conserved and thus older genes (i.e. genes with earlier phylogenetic origin) are more likely to be essential than younger genes - even if they have been duplicated.[76]
Study
The experimental study of essential genes is limited by the fact that, by definition, inactivation of an essential gene is lethal to the organism. Therefore, they cannot be simply deleted or mutated to analyze the resulting phenotypes (a common technique in genetics).
There are, however, some circumstances in which essential genes can be manipulated. In diploid organisms, only a single functional copy of some essential genes may be needed (haplosufficiency), with the heterozygote displaying an instructive phenotype. Some essential genes can tolerate mutations that are deleterious, but not wholly lethal, since they do not completely abolish the gene's function.
Computational analysis can reveal many properties of proteins without analyzing them experimentally, e.g. by looking at homologous proteins, function, structure etc. (see also below, Predicting essential genes). The products of essential genes can also be studied when expressed in other organisms, or when purified and studied in vitro.
Conditionally essential genes are easier to study. Temperature-sensitive variants of essential genes have been identified which encode products that lose function at high temperatures, and so only show a phenotype at increased temperature.[77]
Reproducibility
If screens for essential genes are repeated in independent laboratories, they often result in different gene lists. For instance, screens in E. coli have yielded from ~300 to ~600 essential genes (see Table 1). Such differences are even more pronounced when different bacterial strains are used (see Figure 2). A common explanation is that the experimental conditions are different or that the nature of the mutation may be different (e.g. a complete gene deletion vs. a transposon mutant).[4] Transposon screens in particular are hard to reproduce, given that a transposon can insert at many positions within a gene. Insertions towards the 3' end of an essential gene may not have a lethal phenotype (or no phenotype at all) and thus may not be recognized as such. This can lead to erroneous annotations (here: false negatives).[78]
Comparison of CRISPR/cas9 and RNAi screens. Screens to identify essential genes in the human chronic myelogenous leukemia cell line K562 with these two methods showed only limited overlap. At a 10% false positive rate there were ~4,500 genes identified in the Cas9 screen versus ~3,100 in the shRNA screen, with only ~1,200 genes identified in both.[79]
Different essential genes in different organisms
Different organisms may have different essential genes. For instance, Bacillus subtilis has 271 essential genes.[21] About one-half (150) of the orthologous genes in E. coli are also essential. Another 67 genes that are essential in E. coli are not essential in B. subtilis, while 86 E. coli essential genes have no B. subtilis ortholog.[25] In Mycoplasma genitalium at least 18 genes are essential that are not essential in M. bovis.[80] Many of these different essential genes are caused by paralogs or alternative metabolic pathways.[1]
Such different essential genes in bacteria can be used to develop targeted antibacterial therapies against certain specific pathogens to reduce antibiotic resistance in the microbiome era.[81] Stone et al (2015) have used the difference in essential genes in bacteria to develop selective drugs against the oral pathogen Porphyromonas gingivalis, rather than the beneficial bacteria Streptococcus sanguis.[82]
Prediction
Essential genes can be predicted computationally. However, most methods use experimental data ("training sets") to some extent. Chen et al.[83] determined four criteria to select training sets for such predictions: (1) essential genes in the selected training set should be reliable; (2) the growth conditions in which essential genes are defined should be consistent in training and prediction sets; (3) species used as training set should be closely related to the target organism; and (4) organisms used as training and prediction sets should exhibit similar phenotypes or lifestyles. They also found that the size of the training set should be at least 10% of the total genes to yield accurate predictions. Some approaches for predicting essential genes are:
Comparative genomics. Shortly after the first genomes (of Haemophilus influenzae and Mycoplasma genitalium) became available, Mushegian et al.[84] tried to predict the number of essential genes based on common genes in these two species. It was surmised that only essential genes should be conserved over the long evolutionary distance that separated the two bacteria. This study identified approximately 250 candidate essential genes.[84] As more genomes became available the number of predicted essential genes kept shrinking because more genomes shared fewer and fewer genes. As a consequence, it was concluded that the universal conserved core consists of less than 40 genes.[85][86] However, this set of conserved genes is not identical to the set of essential genes as different species rely on different essential genes.
A similar approach has been used to infer essential genes from the pan-genome of Brucella species. 42 complete Brucella genomes and a total of 132,143 protein-coding genes were used to predict 1252 potential essential genes, derived from the core genome by comparison with a prokaryote database of essential genes.[87]
Network analysis. After the first protein interaction networks of yeast had been published,[88] it was found that highly connected proteins (e.g. by protein-protein interactions) are more likely to be essential.[89] However, highly connected proteins may be experimental artifacts and high connectivity may rather represent pleiotropy instead of essentiality.[90] Nevertheless, network methods have been improved by adding other criteria and therefore do have some value in predicting essential genes.[91]
Machine Learning. Hua et al. used Machine Learning to predict essential genes in 25 bacterial species.[92]
Hurst index. Liu et al. (2015)[93] used the Hurst exponent, a characteristic parameter to describe long-range correlation in DNA to predict essential genes. In 31 out of 33 bacterial genomes the significance levels of the Hurst exponents of the essential genes were significantly higher than for the corresponding full-gene-set, whereas the significance levels of the Hurst exponents of the nonessential genes remained unchanged or increased only slightly.
Minimal genomes. It was also thought that essential genes could be inferred from minimal genomes which supposedly contain only essential genes. The problem here is that the smallest genomes belong to parasitic (or symbiontic) species which can survive with a reduced gene set as they obtain many nutrients from their hosts. For instance, one of the smallest genomes is that of Hodgkinia cicadicola, a symbiont of cicadas, containing only 144 Kb of DNA encoding only 188 genes.[94] Like other symbionts, Hodgkinia receives many of its nutrients from its host, so its genes do not need to be essential.
Metabolic modelling. Essential genes may be also predicted in completely sequenced genomes by metabolic reconstruction, that is, by reconstructing the complete metabolism from the gene content and then identifying those genes and pathways that have been found to be essential in other species. However, this method can be compromised by proteins of unknown function. In addition, many organisms have backup or alternative pathways which have to be taken into account (see figure 1). Metabolic modeling was also used by Basler (2015) to develop a method to predict essential metabolic genes.[95] Flux balance analysis, a method of metabolic modeling, has recently been used to predict essential genes in clear cell renal cell carcinoma metabolism.[96]
Genes of unknown function. Surprisingly, a significant number of essential genes has no known function. For instance, among the 385 essential candidates in M. genitalium, no function could be ascribed to 95 genes[6] even though this number had been reduced to 75 by 2011.[86] Most of unknown functionally essential genes have potential biological functions related to one of the three fundamental functions.[1]
ZUPLS. Song et al. presented a novel method to predict essential genes that only uses the Z-curve and other sequence-based features.[97] Such features can be calculated readily from the DNA/amino acid sequences. However, the reliability of this method remains a bit obscure.
Essential gene prediction servers. Guo et al. (2015) have developed three online services to predict essential genes in bacterial genomes. These freely available tools are applicable for single gene sequences without annotated functions, single genes with definite names, and complete genomes of bacterial strains.[98] Kong et al. (2019) have developed the ePath database, which can be used to search > 4000 bacterial species for predicting essential genes.[42]
Essential protein domains
Although most essential genes encode proteins, many essential proteins consist of a single domain. This fact has been used to identify essential protein domains. Goodacre et al. have identified hundreds of essential domains of unknown function (eDUFs).[99] Lu et al.[100] presented a similar approach and identified 3,450 domains that are essential in at least one microbial species.
See also
References
- Xu, Ping; Ge, Xiuchun; Chen, Lei; Wang, Xiaojing; Dou, Yuetan; Xu, Jerry Z.; Patel, Jenishkumar R.; Stone, Victoria; Trinh, My; Evans, Karra; Kitten, Todd (December 2011). "Genome-wide essential gene identification in Streptococcus sanguinis". Scientific Reports. 1 (1): 125. Bibcode:2011NatSR...1E.125X. doi:10.1038/srep00125. ISSN 2045-2322. PMC 3216606. PMID 22355642.
- Zhang R, Lin Y (January 2009). "DEG 5.0, a database of essential genes in both prokaryotes and eukaryotes". Nucleic Acids Research. 37 (Database issue): D455-8. doi:10.1093/nar/gkn858. PMC 2686491. PMID 18974178.
- Sassetti CM, Boyd DH, Rubin EJ (2003). "Genes required for mycobacterial growth defined by high density mutagenesis". Mol Microbiol. 48 (1): 77–84. doi:10.1046/j.1365-2958.2003.03425.x. PMID 12657046.
- Gerdes S, Edwards R, Kubal M, Fonstein M, Stevens R, Osterman A (October 2006). "Essential genes on metabolic maps". Current Opinion in Biotechnology. 17 (5): 448–56. doi:10.1016/j.copbio.2006.08.006. PMID 16978855.
- Hutchison CA, Peterson SN, Gill SR, Cline RT, White O, Fraser CM, Smith HO, Venter JC (December 1999). "Global transposon mutagenesis and a minimal Mycoplasma genome". Science. 286 (5447): 2165–9. doi:10.1126/science.286.5447.2165. PMID 10591650. S2CID 235447.
- Glass JI, Assad-Garcia N, Alperovich N, Yooseph S, Lewis MR, Maruf M, Hutchison CA, Smith HO, Venter JC (January 2006). "Essential genes of a minimal bacterium". Proceedings of the National Academy of Sciences of the United States of America. 103 (2): 425–30. Bibcode:2006PNAS..103..425G. doi:10.1073/pnas.0510013103. PMC 1324956. PMID 16407165.
- Ji Y, Zhang B, Van SF, Warren P, Woodnutt G, Burnham MK, Rosenberg M (September 2001). "Identification of critical staphylococcal genes using conditional phenotypes generated by antisense RNA". Science. 293 (5538): 2266–9. Bibcode:2001Sci...293.2266J. doi:10.1126/science.1063566. PMID 11567142. S2CID 24126939.
- Forsyth RA, Haselbeck RJ, Ohlsen KL, Yamamoto RT, Xu H, Trawick JD, Wall D, Wang L, Brown-Driver V, Froelich JM, C KG, King P, McCarthy M, Malone C, Misiner B, Robbins D, Tan Z, Zhu Zy ZY, Carr G, Mosca DA, Zamudio C, Foulkes JG, Zyskind JW (March 2002). "A genome-wide strategy for the identification of essential genes in Staphylococcus aureus". Molecular Microbiology. 43 (6): 1387–400. doi:10.1046/j.1365-2958.2002.02832.x. PMID 11952893.
- Akerley BJ, Rubin EJ, Novick VL, Amaya K, Judson N, Mekalanos JJ (January 2002). "A genome-scale analysis for identification of genes required for growth or survival of Haemophilus influenzae". Proceedings of the National Academy of Sciences of the United States of America. 99 (2): 966–71. Bibcode:2002PNAS...99..966A. doi:10.1073/pnas.012602299. PMC 117414. PMID 11805338.
- Thanassi JA, Hartman-Neumann SL, Dougherty TJ, Dougherty BA, Pucci MJ (July 2002). "Identification of 113 conserved essential genes using a high-throughput gene disruption system in Streptococcus pneumoniae". Nucleic Acids Research. 30 (14): 3152–62. doi:10.1093/nar/gkf418. PMC 135739. PMID 12136097.
- Song JH, Ko KS, Lee JY, Baek JY, Oh WS, Yoon HS, Jeong JY, Chun J (June 2005). "Identification of essential genes in Streptococcus pneumoniae by allelic replacement mutagenesis". Molecules and Cells. 19 (3): 365–74. PMID 15995353.
- Le Breton Y, Belew AT, Valdes KM, Islam E, Curry P, Tettelin H, Shirtliff ME, El-Sayed NM, McIver KS (May 2015). "Essential Genes in the Core Genome of the Human Pathogen Streptococcus pyogenes". Scientific Reports. 5: 9838. Bibcode:2015NatSR...5E9838L. doi:10.1038/srep09838. PMC 4440532. PMID 25996237.
- Chen L, Ge X, Xu P (2015). "Identifying essential Streptococcus sanguinis genes using genome-wide deletion mutation". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 15–23. doi:10.1007/978-1-4939-2398-4_2. ISBN 978-1-4939-2397-7. PMC 4819415. PMID 25636610.
- Sassetti CM, Boyd DH, Rubin EJ (October 2001). "Comprehensive identification of conditionally essential genes in mycobacteria". Proceedings of the National Academy of Sciences of the United States of America. 98 (22): 12712–7. Bibcode:2001PNAS...9812712S. doi:10.1073/pnas.231275498. PMC 60119. PMID 11606763.
- Lamichhane G, Freundlich JS, Ekins S, Wickramaratne N, Nolan ST, Bishai WR (February 2011). "Essential metabolites of Mycobacterium tuberculosis and their mimics". mBio. 2 (1): e00301-10. doi:10.1128/mBio.00301-10. PMC 3031304. PMID 21285434.
- Griffin JE, Gawronski JD, Dejesus MA, Ioerger TR, Akerley BJ, Sassetti CM (September 2011). "High-resolution phenotypic profiling defines genes essential for mycobacterial growth and cholesterol catabolism". PLOS Pathogens. 7 (9): e1002251. doi:10.1371/journal.ppat.1002251. PMC 3182942. PMID 21980284.
- Long JE, DeJesus M, Ward D, Baker RE, Ioerger T, Sassetti CM (2015). "Identifying essential genes in Mycobacterium tuberculosis by global phenotypic profiling". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 79–95. doi:10.1007/978-1-4939-2398-4_6. ISBN 978-1-4939-2397-7. PMID 25636614.
- DeJesus MA, Gerrick ER, Xu W, Park SW, Long JE, Boutte CC, Rubin EJ, Schnappinger D, Ehrt S, Fortune SM, Sassetti CM, Ioerger TR (January 2017). "Comprehensive Essentiality Analysis of the Mycobacterium tuberculosis Genome via Saturating Transposon Mutagenesis". mBio. 8 (1): e02133–16. doi:10.1128/mBio.02133-16. PMC 5241402. PMID 28096490.
- Ghosh S, Baloni P, Mukherjee S, Anand P, Chandra N (December 2013). "A multi-level multi-scale approach to study essential genes in Mycobacterium tuberculosis". BMC Systems Biology. 7: 132. doi:10.1186/1752-0509-7-132. PMC 4234997. PMID 24308365.
- Bosch, B, DeJesus, MA, Poulton, NC, Zhang, W, Engelhart, CA, Zaveri, A, Lavalette, S, Ruecker, N, Trujillo, C, Wallach, JB, Li, S, Ehrt, S, Chait, BT, Schnappinger, S, Rock, JM (July 2021). "Genome-wide gene expression tuning reveals diverse vulnerabilities of M. tuberculosis". Cell. 184 (17): 4579–4592.e24. doi:10.1016/j.cell.2021.06.033. PMC 8382161. PMID 34297925.
- Kobayashi K, Ehrlich SD, Albertini A, Amati G, Andersen KK, Arnaud M, et al. (April 2003). "Essential Bacillus subtilis genes". Proceedings of the National Academy of Sciences of the United States of America. 100 (8): 4678–83. Bibcode:2003PNAS..100.4678K. doi:10.1073/pnas.0730515100. PMC 153615. PMID 12682299.
- Commichau FM, Pietack N, Stülke J (June 2013). "Essential genes in Bacillus subtilis: a re-evaluation after ten years". Molecular BioSystems. 9 (6): 1068–75. doi:10.1039/c3mb25595f. PMID 23420519. S2CID 23769853.
- Gerdes SY, Scholle MD, Campbell JW, Balázsi G, Ravasz E, Daugherty MD, et al. (October 2003). "Experimental determination and system level analysis of essential genes in Escherichia coli MG1655". Journal of Bacteriology. 185 (19): 5673–84. doi:10.1128/JB.185.19.5673-5684.2003. PMC 193955. PMID 13129938.
- Kang Y, Durfee T, Glasner JD, Qiu Y, Frisch D, Winterberg KM, et al. (August 2004). "Systematic mutagenesis of the Escherichia coli genome". Journal of Bacteriology. 186 (15): 4921–30. doi:10.1128/JB.186.15.4921-4930.2004. PMC 451658. PMID 15262929.
- Baba T, Ara T, Hasegawa M, Takai Y, Okumura Y, Baba M, et al. (2006). "Construction of Escherichia coli K-12 in-frame, single-gene knockout mutants: the Keio collection". Molecular Systems Biology. 2: 2006.0008. doi:10.1038/msb4100050. PMC 1681482. PMID 16738554.
- Jacobs MA, Alwood A, Thaipisuttikul I, Spencer D, Haugen E, Ernst S, et al. (November 2003). "Comprehensive transposon mutant library of Pseudomonas aeruginosa". Proceedings of the National Academy of Sciences of the United States of America. 100 (24): 14339–44. Bibcode:2003PNAS..10014339J. doi:10.1073/pnas.2036282100. PMC 283593. PMID 14617778.
- Hutcherson JA, Gogeneni H, Yoder-Himes D, Hendrickson EL, Hackett M, Whiteley M, et al. (August 2016). "Comparison of inherently essential genes of Porphyromonas gingivalis identified in two transposon-sequencing libraries". Molecular Oral Microbiology. 31 (4): 354–64. doi:10.1111/omi.12135. PMC 4788587. PMID 26358096.
- Liberati NT, Urbach JM, Miyata S, Lee DG, Drenkard E, Wu G, et al. (February 2006). "An ordered, nonredundant library of Pseudomonas aeruginosa strain PA14 transposon insertion mutants". Proceedings of the National Academy of Sciences of the United States of America. 103 (8): 2833–8. Bibcode:2006PNAS..103.2833L. doi:10.1073/pnas.0511100103. PMC 1413827. PMID 16477005.
- Knuth K, Niesalla H, Hueck CJ, Fuchs TM (March 2004). "Large-scale identification of essential Salmonella genes by trapping lethal insertions". Molecular Microbiology. 51 (6): 1729–44. doi:10.1046/j.1365-2958.2003.03944.x. PMID 15009898. S2CID 45267476.
- Salama NR, Shepherd B, Falkow S (December 2004). "Global transposon mutagenesis and essential gene analysis of Helicobacter pylori". Journal of Bacteriology. 186 (23): 7926–35. doi:10.1128/JB.186.23.7926-7935.2004. PMC 529078. PMID 15547264.
- Suzuki N, Inui M, Yukawa H (2011). "High-Throughput Transposon Mutagenesis of Corynebacterium glutamicum". Strain Engineering. Methods in Molecular Biology. Vol. 765. pp. 409–17. doi:10.1007/978-1-61779-197-0_24. ISBN 978-1-61779-196-3. PMID 21815106.
- Gallagher LA, Ramage E, Jacobs MA, Kaul R, Brittnacher M, Manoil C (January 2007). "A comprehensive transposon mutant library of Francisella novicida, a bioweapon surrogate". Proceedings of the National Academy of Sciences of the United States of America. 104 (3): 1009–14. Bibcode:2007PNAS..104.1009G. doi:10.1073/pnas.0606713104. PMC 1783355. PMID 17215359.
- Stahl M, Stintzi A (June 2011). "Identification of essential genes in C. jejuni genome highlights hyper-variable plasticity regions". Functional & Integrative Genomics. 11 (2): 241–57. doi:10.1007/s10142-011-0214-7. PMID 21344305. S2CID 24054117.
- Stahl M, Stintzi A (2015). "Microarray transposon tracking for the mapping of conditionally essential genes in Campylobacter jejuni". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 1–14. doi:10.1007/978-1-4939-2398-4_1. ISBN 978-1-4939-2397-7. PMID 25636609.
- French CT, Lao P, Loraine AE, Matthews BT, Yu H, Dybvig K (July 2008). "Large-scale transposon mutagenesis of Mycoplasma pulmonis". Molecular Microbiology. 69 (1): 67–76. doi:10.1111/j.1365-2958.2008.06262.x. PMC 2453687. PMID 18452587.
- Cameron DE, Urbach JM, Mekalanos JJ (June 2008). "A defined transposon mutant library and its use in identifying motility genes in Vibrio cholerae". Proceedings of the National Academy of Sciences of the United States of America. 105 (25): 8736–41. Bibcode:2008PNAS..105.8736C. doi:10.1073/pnas.0803281105. PMC 2438431. PMID 18574146.
- Langridge GC, Phan MD, Turner DJ, Perkins TT, Parts L, Haase J, et al. (December 2009). "Simultaneous assay of every Salmonella Typhi gene using one million transposon mutants". Genome Research. 19 (12): 2308–16. doi:10.1101/gr.097097.109. PMC 2792183. PMID 19826075.
- Chaudhuri RR, Allen AG, Owen PJ, Shalom G, Stone K, Harrison M, et al. (July 2009). "Comprehensive identification of essential Staphylococcus aureus genes using Transposon-Mediated Differential Hybridisation (TMDH)". BMC Genomics. 10: 291. doi:10.1186/1471-2164-10-291. PMC 2721850. PMID 19570206.
- Christen B, Abeliuk E, Collier JM, Kalogeraki VS, Passarelli B, Coller JA, Fero MJ, McAdams HH, Shapiro L (August 2011). "The essential genome of a bacterium". Molecular Systems Biology. 7: 528. doi:10.1038/msb.2011.58. PMC 3202797. PMID 21878915.
- Mendum TA, Newcombe J, Mannan AA, Kierzek AM, McFadden J (December 2011). "Interrogation of global mutagenesis data with a genome scale model of Neisseria meningitidis to assess gene fitness in vitro and in sera". Genome Biology. 12 (12): R127. doi:10.1186/gb-2011-12-12-r127. PMC 3334622. PMID 22208880.
- Kuehl JV, Price MN, Ray J, Wetmore KM, Esquivel Z, Kazakov AE, et al. (May 2014). "Functional genomics with a comprehensive library of transposon mutants for the sulfate-reducing bacterium Desulfovibrio alaskensis G20". mBio. 5 (3): e01041-14. doi:10.1128/mBio.01041-14. PMC 4045070. PMID 24865553.
- Kong, Xiangzhen; Zhu, Bin; Stone, Victoria N.; Ge, Xiuchun; El-Rami, Fadi E.; Donghai, Huangfu; Xu, Ping (December 2019). "ePath: an online database towards comprehensive essential gene annotation for prokaryotes". Scientific Reports. 9 (1): 12949. Bibcode:2019NatSR...912949K. doi:10.1038/s41598-019-49098-w. ISSN 2045-2322. PMC 6737131. PMID 31506471.
- Kim DU, Hayles J, Kim D, Wood V, Park HO, Won M, et al. (June 2010). "Analysis of a genome-wide set of gene deletions in the fission yeast Schizosaccharomyces pombe". Nature Biotechnology. 28 (6): 617–623. doi:10.1038/nbt.1628. PMC 3962850. PMID 20473289.
- Kamath RS, Fraser AG, Dong Y, Poulin G, Durbin R, Gotta M, et al. (January 2003). "Systematic functional analysis of the Caenorhabditis elegans genome using RNAi". Nature. 421 (6920): 231–7. Bibcode:2003Natur.421..231K. doi:10.1038/nature01278. hdl:10261/63159. PMID 12529635. S2CID 15745225.
- Spradling AC, Stern D, Beaton A, Rhem EJ, Laverty T, Mozden N, et al. (September 1999). "The Berkeley Drosophila Genome Project gene disruption project: Single P-element insertions mutating 25% of vital Drosophila genes". Genetics. 153 (1): 135–77. doi:10.1093/genetics/153.1.135. PMC 1460730. PMID 10471706.
- Amsterdam A, Nissen RM, Sun Z, Swindell EC, Farrington S, Hopkins N (August 2004). "Identification of 315 genes essential for early zebrafish development". Proceedings of the National Academy of Sciences of the United States of America. 101 (35): 12792–7. Bibcode:2004PNAS..10112792A. doi:10.1073/pnas.0403929101. PMC 516474. PMID 15256591.
- White JK, Gerdin AK, Karp NA, Ryder E, Buljan M, Bussell JN, et al. (July 2013). "Genome-wide generation and systematic phenotyping of knockout mice reveals new roles for many genes". Cell. 154 (2): 452–64. doi:10.1016/j.cell.2013.06.022. PMC 3717207. PMID 23870131.
- Liao BY, Zhang J (May 2008). "Null mutations in human and mouse orthologs frequently result in different phenotypes". Proceedings of the National Academy of Sciences of the United States of America. 105 (19): 6987–92. Bibcode:2008PNAS..105.6987L. doi:10.1073/pnas.0800387105. PMC 2383943. PMID 18458337.
- Georgi B, Voight BF, Bućan M (May 2013). Flint J (ed.). "From mouse to human: evolutionary genomics analysis of human orthologs of essential genes". PLOS Genetics. 9 (5): e1003484. doi:10.1371/journal.pgen.1003484. PMC 3649967. PMID 23675308.
- Sulem P, Helgason H, Oddson A, Stefansson H, Gudjonsson SA, Zink F, et al. (May 2015). "Identification of a large set of rare complete human knockouts". Nature Genetics. 47 (5): 448–52. doi:10.1038/ng.3243. PMID 25807282. S2CID 205349719.
- Narasimhan VM, Hunt KA, Mason D, Baker CL, Karczewski KJ, Barnes MR, et al. (April 2016). "Health and population effects of rare gene knockouts in adult humans with related parents". Science. 352 (6284): 474–7. Bibcode:2016Sci...352..474N. doi:10.1126/science.aac8624. PMC 4985238. PMID 26940866.
- Luo H, Lin Y, Gao F, Zhang CT, Zhang R (January 2014). "DEG 10, an update of the database of essential genes that includes both protein-coding genes and noncoding genomic elements". Nucleic Acids Research. 42 (Database issue): D574-80. doi:10.1093/nar/gkt1131. PMC 3965060. PMID 24243843.
- Tzafrir I, Pena-Muralla R, Dickerman A, Berg M, Rogers R, Hutchens S, et al. (July 2004). "Identification of genes required for embryo development in Arabidopsis". Plant Physiology. 135 (3): 1206–20. doi:10.1104/pp.104.045179. PMC 519041. PMID 15266054.
- Wang T, Birsoy K, Hughes NW, Krupczak KM, Post Y, Wei JJ, et al. (November 2015). "Identification and characterization of essential genes in the human genome". Science. 350 (6264): 1096–101. Bibcode:2015Sci...350.1096W. doi:10.1126/science.aac7041. PMC 4662922. PMID 26472758.
- Blomen VA, Májek P, Jae LT, Bigenzahn JW, Nieuwenhuis J, Staring J, et al. (November 2015). "Gene essentiality and synthetic lethality in haploid human cells". Science. 350 (6264): 1092–6. Bibcode:2015Sci...350.1092B. doi:10.1126/science.aac7557. PMID 26472760. S2CID 26529733.
- Georgi B, Voight BF, Bućan M (May 2013). "From mouse to human: evolutionary genomics analysis of human orthologs of essential genes". PLOS Genetics. 9 (5): e1003484. doi:10.1371/journal.pgen.1003484. PMC 3649967. PMID 23675308.
- Liao BY, Zhang J (August 2007). "Mouse duplicate genes are as essential as singletons". Trends in Genetics. 23 (8): 378–81. doi:10.1016/j.tig.2007.05.006. PMID 17559966.
- Mewes HW, Frishman D, Güldener U, Mannhaupt G, Mayer K, Mokrejs M, et al. (January 2002). "MIPS: a database for genomes and protein sequences". Nucleic Acids Research. 30 (1): 31–4. doi:10.1093/nar/30.1.31. PMC 99165. PMID 11752246.
- Giaever G, Chu AM, Ni L, Connelly C, Riles L, Véronneau S, et al. (July 2002). "Functional profiling of the Saccharomyces cerevisiae genome". Nature. 418 (6896): 387–91. Bibcode:2002Natur.418..387G. doi:10.1038/nature00935. PMID 12140549. S2CID 4400400.
- Yu D, Silva MC, Shenk T (October 2003). "Functional map of human cytomegalovirus AD169 defined by global mutational analysis". Proceedings of the National Academy of Sciences of the United States of America. 100 (21): 12396–401. Bibcode:2003PNAS..10012396Y. doi:10.1073/pnas.1635160100. PMC 218769. PMID 14519856.
- Dobson BM, Tscharke DC (November 2015). "Redundancy complicates the definition of essential genes for vaccinia virus". The Journal of General Virology. 96 (11): 3326–37. doi:10.1099/jgv.0.000266. PMC 5972330. PMID 26290187.
- Dedrick RM, Marinelli LJ, Newton GL, Pogliano K, Pogliano J, Hatfull GF (May 2013). "Functional requirements for bacteriophage growth: gene essentiality and expression in mycobacteriophage Giles". Molecular Microbiology. 88 (3): 577–89. doi:10.1111/mmi.12210. PMC 3641587. PMID 23560716.
- Thomas JA, Benítez Quintana AD, Bosch MA, Coll De Peña A, Aguilera E, Coulibaly A, et al. (November 2016). "Identification of Essential Genes in the Salmonella Phage SPN3US Reveals Novel Insights into Giant Phage Head Structure and Assembly". Journal of Virology. 90 (22): 10284–10298. doi:10.1128/JVI.01492-16. PMC 5105663. PMID 27605673.
- Pál C, Papp B, Lercher MJ, Csermely P, Oliver SG, Hurst LD (March 2006). "Chance and necessity in the evolution of minimal metabolic networks". Nature. 440 (7084): 667–70. Bibcode:2006Natur.440..667P. doi:10.1038/nature04568. PMID 16572170. S2CID 4424895.
- Mori H, Baba T, Yokoyama K, Takeuchi R, Nomura W, Makishi K, Otsuka Y, Dose H, Wanner BL (2015). "Identification of essential genes and synthetic lethal gene combinations in Escherichia coli K-12". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 45–65. doi:10.1007/978-1-4939-2398-4_4. ISBN 978-1-4939-2397-7. PMID 25636612.
- Verhagen LM, de Jonge MI, Burghout P, Schraa K, Spagnuolo L, Mennens S, Eleveld MJ, van der Gaast-de Jongh CE, Zomer A, Hermans PW, Bootsma HJ (2014). "Genome-wide identification of genes essential for the survival of Streptococcus pneumoniae in human saliva". PLOS ONE. 9 (2): e89541. Bibcode:2014PLoSO...989541V. doi:10.1371/journal.pone.0089541. PMC 3934895. PMID 24586856.
- D'Souza G, Kost C (November 2016). "Experimental Evolution of Metabolic Dependency in Bacteria". PLOS Genetics. 12 (11): e1006364. doi:10.1371/journal.pgen.1006364. PMC 5096674. PMID 27814362.
- Xu, Ping; Widmer, Giovanni; Wang, Yingping; Ozaki, Luiz S.; Alves, Joao M.; Serrano, Myrna G.; Puiu, Daniela; Manque, Patricio; Akiyoshi, Donna; Mackey, Aaron J.; Pearson, William R. (October 2004). "The genome of Cryptosporidium hominis". Nature. 431 (7012): 1107–1112. Bibcode:2004Natur.431.1107X. doi:10.1038/nature02977. ISSN 0028-0836. PMID 15510150. S2CID 4394344.
- Tipples G, McClarty G (June 1993). "The obligate intracellular bacterium Chlamydia trachomatis is auxotrophic for three of the four ribonucleoside triphosphates". Molecular Microbiology. 8 (6): 1105–14. doi:10.1111/j.1365-2958.1993.tb01655.x. PMID 8361355. S2CID 46389854.
- Côté, Jean-Philippe; French, Shawn; Gehrke, Sebastian S.; MacNair, Craig R.; Mangat, Chand S.; Bharat, Amrita; Brown, Eric D. (2016-11-22). "The Genome-Wide Interaction Network of Nutrient Stress Genes in Escherichia coli". mBio. 7 (6). doi:10.1128/mBio.01714-16. ISSN 2150-7511. PMC 5120140. PMID 27879333.
- Woods S, Coghlan A, Rivers D, Warnecke T, Jeffries SJ, Kwon T, et al. (May 2013). Sternberg PW (ed.). "Duplication and retention biases of essential and non-essential genes revealed by systematic knockdown analyses". PLOS Genetics. 9 (5): e1003330. doi:10.1371/journal.pgen.1003330. PMC 3649981. PMID 23675306.
- Fang G, Rocha E, Danchin A (November 2005). "How essential are nonessential genes?". Molecular Biology and Evolution. 22 (11): 2147–56. doi:10.1093/molbev/msi211. PMID 16014871.
- Jordan IK, Rogozin IB, Wolf YI, Koonin EV (June 2002). "Essential genes are more evolutionarily conserved than are nonessential genes in bacteria". Genome Research. 12 (6): 962–8. doi:10.1101/gr.87702. PMC 1383730. PMID 12045149.
- Ryan CJ, Krogan NJ, Cunningham P, Cagney G (2013). "All or nothing: protein complexes flip essentiality between distantly related eukaryotes". Genome Biology and Evolution. 5 (6): 1049–59. doi:10.1093/gbe/evt074. PMC 3698920. PMID 23661563.
- Sipiczki M (2000). "Where does fission yeast sit on the tree of life?". Genome Biology. 1 (2): REVIEWS1011. doi:10.1186/gb-2000-1-2-reviews1011. PMC 138848. PMID 11178233.
- Chen WH, Trachana K, Lercher MJ, Bork P (July 2012). "Younger genes are less likely to be essential than older genes, and duplicates are less likely to be essential than singletons of the same age". Molecular Biology and Evolution. 29 (7): 1703–6. doi:10.1093/molbev/mss014. PMC 3375470. PMID 22319151.
- Kofoed M, Milbury KL, Chiang JH, Sinha S, Ben-Aroya S, Giaever G, et al. (July 2015). "An Updated Collection of Sequence Barcoded Temperature-Sensitive Alleles of Yeast Essential Genes". G3. 5 (9): 1879–87. doi:10.1534/g3.115.019174. PMC 4555224. PMID 26175450.
- Deng J, Su S, Lin X, Hassett DJ, Lu LJ (2013). Kim PM (ed.). "A statistical framework for improving genomic annotations of prokaryotic essential genes". PLOS ONE. 8 (3): e58178. Bibcode:2013PLoSO...858178D. doi:10.1371/journal.pone.0058178. PMC 3592911. PMID 23520492.
- Morgens DW, Deans RM, Li A, Bassik MC (June 2016). "Systematic comparison of CRISPR/Cas9 and RNAi screens for essential genes". Nature Biotechnology. 34 (6): 634–6. doi:10.1038/nbt.3567. PMC 4900911. PMID 27159373.
- Sharma S, Markham PF, Browning GF (2014). "Genes found essential in other mycoplasmas are dispensable in Mycoplasma bovis". PLOS ONE. 9 (6): e97100. Bibcode:2014PLoSO...997100S. doi:10.1371/journal.pone.0097100. PMC 4045577. PMID 24897538.
- Stone VN, Xu P (December 2017). "Targeted antimicrobial therapy in the microbiome era". Molecular Oral Microbiology. 32 (6): 446–454. doi:10.1111/omi.12190. PMC 5697594. PMID 28609586.
- Stone VN, Parikh HI, El-rami F, Ge X, Chen W, Zhang Y, et al. (2015-11-06). Merritt J (ed.). "Identification of Small-Molecule Inhibitors against Meso-2, 6-Diaminopimelate Dehydrogenase from Porphyromonas gingivalis". PLOS ONE. 10 (11): e0141126. Bibcode:2015PLoSO..1041126S. doi:10.1371/journal.pone.0141126. PMC 4636305. PMID 26544875.
- Cheng J, Xu Z, Wu W, Zhao L, Li X, Liu Y, Tao S (2014). "Training set selection for the prediction of essential genes". PLOS ONE. 9 (1): e86805. Bibcode:2014PLoSO...986805C. doi:10.1371/journal.pone.0086805. PMC 3899339. PMID 24466248.
- Mushegian AR, Koonin EV (September 1996). "A minimal gene set for cellular life derived by comparison of complete bacterial genomes". Proceedings of the National Academy of Sciences of the United States of America. 93 (19): 10268–73. Bibcode:1996PNAS...9310268M. doi:10.1073/pnas.93.19.10268. PMC 38373. PMID 8816789.
- Charlebois RL, Doolittle WF (December 2004). "Computing prokaryotic gene ubiquity: rescuing the core from extinction". Genome Research. 14 (12): 2469–77. doi:10.1101/gr.3024704. PMC 534671. PMID 15574825.
- Juhas M, Eberl L, Glass JI (October 2011). "Essence of life: essential genes of minimal genomes". Trends in Cell Biology. 21 (10): 562–8. doi:10.1016/j.tcb.2011.07.005. PMID 21889892.
- Yang X, Li Y, Zang J, Li Y, Bie P, Lu Y, Wu Q (April 2016). "Analysis of pan-genome to identify the core genes and essential genes of Brucella spp". Molecular Genetics and Genomics. 291 (2): 905–12. doi:10.1007/s00438-015-1154-z. PMID 26724943. S2CID 14565579.
- Schwikowski B, Uetz P, Fields S (December 2000). "A network of protein-protein interactions in yeast". Nature Biotechnology. 18 (12): 1257–61. doi:10.1038/82360. PMID 11101803. S2CID 3009359.
- Jeong H, Mason SP, Barabási AL, Oltvai ZN (May 2001). "Lethality and centrality in protein networks". Nature. 411 (6833): 41–2. arXiv:cond-mat/0105306. Bibcode:2001Natur.411...41J. doi:10.1038/35075138. PMID 11333967. S2CID 258942.
- Yu H, Braun P, Yildirim MA, Lemmens I, Venkatesan K, Sahalie J, et al. (October 2008). "High-quality binary protein interaction map of the yeast interactome network". Science. 322 (5898): 104–10. Bibcode:2008Sci...322..104Y. doi:10.1126/science.1158684. PMC 2746753. PMID 18719252.
- Li X, Li W, Zeng M, Zheng R, Li M (February 2019). "Network-based methods for predicting essential genes or proteins: a survey". Briefings in Bioinformatics. 21 (2): 566–583. doi:10.1093/bib/bbz017. PMID 30776072.
- Hua HL, Zhang FZ, Labena AA, Dong C, Jin YT, Guo FB (2016-01-01). "An Approach for Predicting Essential Genes Using Multiple Homology Mapping and Machine Learning Algorithms". BioMed Research International. 2016: 7639397. doi:10.1155/2016/7639397. PMC 5021884. PMID 27660763.
- Liu X, Wang B, Xu L (2015). "Statistical Analysis of Hurst Exponents of Essential/Nonessential Genes in 33 Bacterial Genomes". PLOS ONE. 10 (6): e0129716. Bibcode:2015PLoSO..1029716L. doi:10.1371/journal.pone.0129716. PMC 4466317. PMID 26067107.
- McCutcheon JP, McDonald BR, Moran NA (July 2009). Matic I (ed.). "Origin of an alternative genetic code in the extremely small and GC-rich genome of a bacterial symbiont". PLOS Genetics. 5 (7): e1000565. doi:10.1371/journal.pgen.1000565. PMC 2704378. PMID 19609354.
- Basler G (2015). "Computational prediction of essential metabolic genes using constraint-based approaches". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 183–204. doi:10.1007/978-1-4939-2398-4_12. ISBN 978-1-4939-2397-7. PMID 25636620.
- Gatto F, Miess H, Schulze A, Nielsen J (June 2015). "Flux balance analysis predicts essential genes in clear cell renal cell carcinoma metabolism". Scientific Reports. 5: 10738. Bibcode:2015NatSR...5E0738G. doi:10.1038/srep10738. PMC 4603759. PMID 26040780.
- Song K, Tong T, Wu F (April 2014). "Predicting essential genes in prokaryotic genomes using a linear method: ZUPLS". Integrative Biology. 6 (4): 460–9. doi:10.1039/c3ib40241j. PMID 24603751.
- Guo FB, Ye YN, Ning LW, Wei W (2015). "Three computational tools for predicting bacterial essential genes". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 205–17. doi:10.1007/978-1-4939-2398-4_13. ISBN 978-1-4939-2397-7. PMID 25636621.
- Goodacre NF, Gerloff DL, Uetz P (December 2013). "Protein domains of unknown function are essential in bacteria". mBio. 5 (1): e00744-13. doi:10.1128/mBio.00744-13. PMC 3884060. PMID 24381303.
- Lu Y, Lu Y, Deng J, Lu H, Lu LJ (2015). "Discovering essential domains in essential genes". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 235–45. doi:10.1007/978-1-4939-2398-4_15. ISBN 978-1-4939-2397-7. PMID 25636623.
Further reading
- Gao F, Luo H, Zhang CT, Zhang R (2015). "Gene essentiality analysis based on DEG 10, an updated database of essential genes". Gene Essentiality. Methods in Molecular Biology. Vol. 1279. pp. 219–33. doi:10.1007/978-1-4939-2398-4_14. ISBN 978-1-4939-2397-7. PMID 25636622.
- Long JL, ed. (2015). Gene Essentiality - Springer Methods and Protocols. Methods in Molecular Biology. Vol. 1279. Humana Press. p. 248. doi:10.1007/978-1-4939-2398-4. ISBN 978-1-4939-2397-7. S2CID 27547825.
- Zhang R, ed. (2022). Essential Genes and Genomes. Methods in Molecular Biology. Vol. 2377. Humana Press. p. 434. doi:10.1007/978-1-0716-1720-5. ISBN 978-1-0716-1719-9. S2CID 240006552.