Cooley–Tukey FFT algorithm
The Cooley–Tukey algorithm, named after J. W. Cooley and John Tukey, is the most common fast Fourier transform (FFT) algorithm. It re-expresses the discrete Fourier transform (DFT) of an arbitrary composite size in terms of N1 smaller DFTs of sizes N2, recursively, to reduce the computation time to O(N log N) for highly composite N (smooth numbers). Because of the algorithm's importance, specific variants and implementation styles have become known by their own names, as described below.

Because the Cooley–Tukey algorithm breaks the DFT into smaller DFTs, it can be combined arbitrarily with any other algorithm for the DFT. For example, Rader's or Bluestein's algorithm can be used to handle large prime factors that cannot be decomposed by Cooley–Tukey, or the prime-factor algorithm can be exploited for greater efficiency in separating out relatively prime factors.
The algorithm, along with its recursive application, was invented by Carl Friedrich Gauss. Cooley and Tukey independently rediscovered and popularized it 160 years later.
History
This algorithm, including its recursive application, was invented around 1805 by Carl Friedrich Gauss, who used it to interpolate the trajectories of the asteroids Pallas and Juno, but his work was not widely recognized (being published only posthumously and in Neo-Latin).[1][2] Gauss did not analyze the asymptotic computational time, however. Various limited forms were also rediscovered several times throughout the 19th and early 20th centuries.[2] FFTs became popular after James Cooley of IBM and John Tukey of Princeton published a paper in 1965 reinventing the algorithm and describing how to perform it conveniently on a computer.[3]
Tukey reportedly came up with the idea during a meeting of President Kennedy's Science Advisory Committee discussing ways to detect nuclear-weapon tests in the Soviet Union by employing seismometers located outside the country. These sensors would generate seismological time series. However, analysis of this data would require fast algorithms for computing DFTs due to the number of sensors and length of time. This task was critical for the ratification of the proposed nuclear test ban so that any violations could be detected without need to visit Soviet facilities.[4][5] Another participant at that meeting, Richard Garwin of IBM, recognized the potential of the method and put Tukey in touch with Cooley. However, Garwin made sure that Cooley did not know the original purpose. Instead, Cooley was told that this was needed to determine periodicities of the spin orientations in a 3-D crystal of helium-3. Cooley and Tukey subsequently published their joint paper, and wide adoption quickly followed due to the simultaneous development of Analog-to-digital converters capable of sampling at rates up to 300 kHz.
The fact that Gauss had described the same algorithm (albeit without analyzing its asymptotic cost) was not realized until several years after Cooley and Tukey's 1965 paper.[2] Their paper cited as inspiration only the work by I. J. Good on what is now called the prime-factor FFT algorithm (PFA);[3] although Good's algorithm was initially thought to be equivalent to the Cooley–Tukey algorithm, it was quickly realized that PFA is a quite different algorithm (working only for sizes that have relatively prime factors and relying on the Chinese remainder theorem, unlike the support for any composite size in Cooley–Tukey).[6]
The radix-2 DIT case
A radix-2 decimation-in-time (DIT) FFT is the simplest and most common form of the Cooley–Tukey algorithm, although highly optimized Cooley–Tukey implementations typically use other forms of the algorithm as described below. Radix-2 DIT divides a DFT of size N into two interleaved DFTs (hence the name "radix-2") of size N/2 with each recursive stage.
The discrete Fourier transform (DFT) is defined by the formula:

where is an integer ranging from 0 to .


Radix-2 DIT first computes the DFTs of the even-indexed inputs and of the odd-indexed inputs , and then combines those two results to produce the DFT of the whole sequence. This idea can then be performed recursively to reduce the overall runtime to O(N log N). This simplified form assumes that N is a power of two; since the number of sample points N can usually be chosen freely by the application (e.g. by changing the sample rate or window, zero-padding, etcetera), this is often not an important restriction.


The radix-2 DIT algorithm rearranges the DFT of the function into two parts: a sum over the even-numbered indices and a sum over the odd-numbered indices :




One can factor a common multiplier out of the second sum, as shown in the equation below. It is then clear that the two sums are the DFT of the even-indexed part and the DFT of odd-indexed part of the function . Denote the DFT of the Even-indexed inputs by and the DFT of the Odd-indexed inputs by and we obtain:






Note that the equalities hold for but the crux is that and are calculated in this way for only. Thanks to the periodicity of the complex exponential, is also obtained from and :




We can rewrite and as:


This result, expressing the DFT of length N recursively in terms of two DFTs of size N/2, is the core of the radix-2 DIT fast Fourier transform. The algorithm gains its speed by re-using the results of intermediate computations to compute multiple DFT outputs. Note that final outputs are obtained by a +/− combination of and , which is simply a size-2 DFT (sometimes called a butterfly in this context); when this is generalized to larger radices below, the size-2 DFT is replaced by a larger DFT (which itself can be evaluated with an FFT).

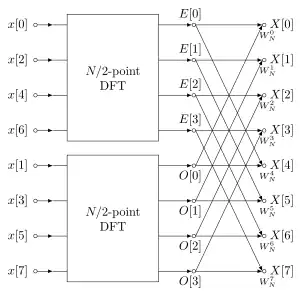
This process is an example of the general technique of divide and conquer algorithms; in many conventional implementations, however, the explicit recursion is avoided, and instead one traverses the computational tree in breadth-first fashion.
The above re-expression of a size-N DFT as two size-N/2 DFTs is sometimes called the Danielson–Lanczos lemma, since the identity was noted by those two authors in 1942[7] (influenced by Runge's 1903 work[2]). They applied their lemma in a "backwards" recursive fashion, repeatedly doubling the DFT size until the transform spectrum converged (although they apparently didn't realize the linearithmic [i.e., order N log N] asymptotic complexity they had achieved). The Danielson–Lanczos work predated widespread availability of mechanical or electronic computers and required manual calculation (possibly with mechanical aids such as adding machines); they reported a computation time of 140 minutes for a size-64 DFT operating on real inputs to 3–5 significant digits. Cooley and Tukey's 1965 paper reported a running time of 0.02 minutes for a size-2048 complex DFT on an IBM 7094 (probably in 36-bit single precision, ~8 digits).[3] Rescaling the time by the number of operations, this corresponds roughly to a speedup factor of around 800,000. (To put the time for the hand calculation in perspective, 140 minutes for size 64 corresponds to an average of at most 16 seconds per floating-point operation, around 20% of which are multiplications.)
Pseudocode
In pseudocode, the below procedure could be written:[8]
X0,...,N−1 ← ditfft2(x, N, s): DFT of (x0, xs, x2s, ..., x(N-1)s):
if N = 1 then
X0 ← x0 trivial size-1 DFT base case
else
X0,...,N/2−1 ← ditfft2(x, N/2, 2s) DFT of (x0, x2s, x4s, ..., x(N-2)s)
XN/2,...,N−1 ← ditfft2(x+s, N/2, 2s) DFT of (xs, xs+2s, xs+4s, ..., x(N-1)s)
for k = 0 to N/2−1 do combine DFTs of two halves into full DFT:
p ← Xk
q ← exp(−2πi/N k) Xk+N/2
Xk ← p + q
Xk+N/2 ← p − q
end for
end if
Here, ditfft2(x,N,1), computes X=DFT(x) out-of-place by a radix-2 DIT FFT, where N is an integer power of 2 and s=1 is the stride of the input x array. x+s denotes the array starting with xs.
(The results are in the correct order in X and no further bit-reversal permutation is required; the often-mentioned necessity of a separate bit-reversal stage only arises for certain in-place algorithms, as described below.)
High-performance FFT implementations make many modifications to the implementation of such an algorithm compared to this simple pseudocode. For example, one can use a larger base case than N=1 to amortize the overhead of recursion, the twiddle factors can be precomputed, and larger radices are often used for cache reasons; these and other optimizations together can improve the performance by an order of magnitude or more.[8] (In many textbook implementations the depth-first recursion is eliminated in favor of a nonrecursive breadth-first approach, although depth-first recursion has been argued to have better memory locality.[8][9]) Several of these ideas are described in further detail below.
![\exp[-2\pi ik/N]](../I/4d3237d9b3ed8e80ddaf135303aba19510130fa8.svg)
Idea
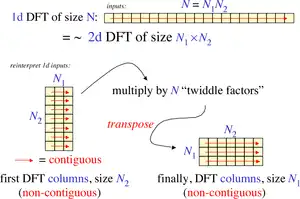
More generally, Cooley–Tukey algorithms recursively re-express a DFT of a composite size N = N1N2 as:[10]
- Perform N1 DFTs of size N2.
- Multiply by complex roots of unity (often called the twiddle factors).
- Perform N2 DFTs of size N1.
Typically, either N1 or N2 is a small factor (not necessarily prime), called the radix (which can differ between stages of the recursion). If N1 is the radix, it is called a decimation in time (DIT) algorithm, whereas if N2 is the radix, it is decimation in frequency (DIF, also called the Sande–Tukey algorithm). The version presented above was a radix-2 DIT algorithm; in the final expression, the phase multiplying the odd transform is the twiddle factor, and the +/- combination (butterfly) of the even and odd transforms is a size-2 DFT. (The radix's small DFT is sometimes known as a butterfly, so-called because of the shape of the dataflow diagram for the radix-2 case.)
Variations
There are many other variations on the Cooley–Tukey algorithm. Mixed-radix implementations handle composite sizes with a variety of (typically small) factors in addition to two, usually (but not always) employing the O(N2) algorithm for the prime base cases of the recursion (it is also possible to employ an N log N algorithm for the prime base cases, such as Rader's or Bluestein's algorithm). Split radix merges radices 2 and 4, exploiting the fact that the first transform of radix 2 requires no twiddle factor, in order to achieve what was long the lowest known arithmetic operation count for power-of-two sizes,[10] although recent variations achieve an even lower count.[11][12] (On present-day computers, performance is determined more by cache and CPU pipeline considerations than by strict operation counts; well-optimized FFT implementations often employ larger radices and/or hard-coded base-case transforms of significant size.[13]).
Another way of looking at the Cooley–Tukey algorithm is that it re-expresses a size N one-dimensional DFT as an N1 by N2 two-dimensional DFT (plus twiddles), where the output matrix is transposed. The net result of all of these transpositions, for a radix-2 algorithm, corresponds to a bit reversal of the input (DIF) or output (DIT) indices. If, instead of using a small radix, one employs a radix of roughly √N and explicit input/output matrix transpositions, it is called a four-step FFT algorithm (or six-step, depending on the number of transpositions), initially proposed to improve memory locality,[14][15] e.g. for cache optimization or out-of-core operation, and was later shown to be an optimal cache-oblivious algorithm.[16]
The general Cooley–Tukey factorization rewrites the indices k and n as and , respectively, where the indices ka and na run from 0..Na-1 (for a of 1 or 2). That is, it re-indexes the input (n) and output (k) as N1 by N2 two-dimensional arrays in column-major and row-major order, respectively; the difference between these indexings is a transposition, as mentioned above. When this re-indexing is substituted into the DFT formula for nk, the cross term vanishes (its exponential is unity), and the remaining terms give



-
- .

![{\displaystyle =\sum _{n_{1}=0}^{N_{1}-1}\left[e^{-{\frac {2\pi i}{N_{1}N_{2}}}n_{1}k_{2}}\right]\left(\sum _{n_{2}=0}^{N_{2}-1}x_{N_{1}n_{2}+n_{1}}e^{-{\frac {2\pi i}{N_{2}}}n_{2}k_{2}}\right)e^{-{\frac {2\pi i}{N_{1}}}n_{1}k_{1}}}](../I/a455425257070160181227f7385f8820eb6238d4.svg)

where each inner sum is a DFT of size N2, each outer sum is a DFT of size N1, and the [...] bracketed term is the twiddle factor.
An arbitrary radix r (as well as mixed radices) can be employed, as was shown by both Cooley and Tukey[3] as well as Gauss (who gave examples of radix-3 and radix-6 steps).[2] Cooley and Tukey originally assumed that the radix butterfly required O(r2) work and hence reckoned the complexity for a radix r to be O(r2 N/r logrN) = O(N log2(N) r/log2r); from calculation of values of r/log2r for integer values of r from 2 to 12 the optimal radix is found to be 3 (the closest integer to e, which minimizes r/log2r).[3][17] This analysis was erroneous, however: the radix-butterfly is also a DFT and can be performed via an FFT algorithm in O(r log r) operations, hence the radix r actually cancels in the complexity O(r log(r) N/r logrN), and the optimal r is determined by more complicated considerations. In practice, quite large r (32 or 64) are important in order to effectively exploit e.g. the large number of processor registers on modern processors,[13] and even an unbounded radix r=√N also achieves O(N log N) complexity and has theoretical and practical advantages for large N as mentioned above.[14][15][16]
Data reordering, bit reversal, and in-place algorithms
Although the abstract Cooley–Tukey factorization of the DFT, above, applies in some form to all implementations of the algorithm, much greater diversity exists in the techniques for ordering and accessing the data at each stage of the FFT. Of special interest is the problem of devising an in-place algorithm that overwrites its input with its output data using only O(1) auxiliary storage.
The best-known reordering technique involves explicit bit reversal for in-place radix-2 algorithms. Bit reversal is the permutation where the data at an index n, written in binary with digits b4b3b2b1b0 (e.g. 5 digits for N=32 inputs), is transferred to the index with reversed digits b0b1b2b3b4 . Consider the last stage of a radix-2 DIT algorithm like the one presented above, where the output is written in-place over the input: when and are combined with a size-2 DFT, those two values are overwritten by the outputs. However, the two output values should go in the first and second halves of the output array, corresponding to the most significant bit b4 (for N=32); whereas the two inputs and are interleaved in the even and odd elements, corresponding to the least significant bit b0. Thus, in order to get the output in the correct place, b0 should take the place of b4 and the index becomes b0b4b3b2b1. And for next recursive stage, those 4 least significant bits will become b1b4b3b2, If you include all of the recursive stages of a radix-2 DIT algorithm, all the bits must be reversed and thus one must pre-process the input (or post-process the output) with a bit reversal to get in-order output. (If each size-N/2 subtransform is to operate on contiguous data, the DIT input is pre-processed by bit-reversal.) Correspondingly, if you perform all of the steps in reverse order, you obtain a radix-2 DIF algorithm with bit reversal in post-processing (or pre-processing, respectively).
The logarithm (log) used in this algorithm is a base 2 logarithm.
The following is pseudocode for iterative radix-2 FFT algorithm implemented using bit-reversal permutation.[18]
algorithm iterative-fft is
input: Array a of n complex values where n is a power of 2.
output: Array A the DFT of a.
bit-reverse-copy(a, A)
n ← a.length
for s = 1 to log(n) do
m ← 2s
ωm ← exp(−2πi/m)
for k = 0 to n-1 by m do
ω ← 1
for j = 0 to m/2 – 1 do
t ← ω A[k + j + m/2]
u ← A[k + j]
A[k + j] ← u + t
A[k + j + m/2] ← u – t
ω ← ω ωm
return A
The bit-reverse-copy procedure can be implemented as follows.
algorithm bit-reverse-copy(a,A) is
input: Array a of n complex values where n is a power of 2.
output: Array A of size n.
n ← a.length
for k = 0 to n – 1 do
A[rev(k)] := a[k]
Alternatively, some applications (such as convolution) work equally well on bit-reversed data, so one can perform forward transforms, processing, and then inverse transforms all without bit reversal to produce final results in the natural order.
Many FFT users, however, prefer natural-order outputs, and a separate, explicit bit-reversal stage can have a non-negligible impact on the computation time,[13] even though bit reversal can be done in O(N) time and has been the subject of much research.[19][20][21] Also, while the permutation is a bit reversal in the radix-2 case, it is more generally an arbitrary (mixed-base) digit reversal for the mixed-radix case, and the permutation algorithms become more complicated to implement. Moreover, it is desirable on many hardware architectures to re-order intermediate stages of the FFT algorithm so that they operate on consecutive (or at least more localized) data elements. To these ends, a number of alternative implementation schemes have been devised for the Cooley–Tukey algorithm that do not require separate bit reversal and/or involve additional permutations at intermediate stages.
The problem is greatly simplified if it is out-of-place: the output array is distinct from the input array or, equivalently, an equal-size auxiliary array is available. The Stockham auto-sort algorithm[22][23] performs every stage of the FFT out-of-place, typically writing back and forth between two arrays, transposing one "digit" of the indices with each stage, and has been especially popular on SIMD architectures.[23][24] Even greater potential SIMD advantages (more consecutive accesses) have been proposed for the Pease algorithm,[25] which also reorders out-of-place with each stage, but this method requires separate bit/digit reversal and O(N log N) storage. One can also directly apply the Cooley–Tukey factorization definition with explicit (depth-first) recursion and small radices, which produces natural-order out-of-place output with no separate permutation step (as in the pseudocode above) and can be argued to have cache-oblivious locality benefits on systems with hierarchical memory.[9][13][26]
A typical strategy for in-place algorithms without auxiliary storage and without separate digit-reversal passes involves small matrix transpositions (which swap individual pairs of digits) at intermediate stages, which can be combined with the radix butterflies to reduce the number of passes over the data.[13][27][28][29][30]
References
- Gauss, Carl Friedrich (1876) [n.d.]. Theoria Interpolationis Methodo Nova Tractata. pp. 265–327.
{{cite book}}:|work=ignored (help) - Heideman, M. T., D. H. Johnson, and C. S. Burrus, "Gauss and the history of the fast Fourier transform," IEEE ASSP Magazine, 1, (4), 14–21 (1984)
- Cooley, James W.; Tukey, John W. (1965). "An algorithm for the machine calculation of complex Fourier series". Math. Comput. 19 (90): 297–301. doi:10.2307/2003354. JSTOR 2003354.
- Cooley, James W.; Lewis, Peter A. W.; Welch, Peter D. (1967). "Historical notes on the fast Fourier transform" (PDF). IEEE Transactions on Audio and Electroacoustics. 15 (2): 76–79. CiteSeerX 10.1.1.467.7209. doi:10.1109/tau.1967.1161903.
- Rockmore, Daniel N. , Comput. Sci. Eng. 2 (1), 60 (2000). The FFT — an algorithm the whole family can use Special issue on "top ten algorithms of the century "Barry A. Cipra. "The Best of the 20th Century: Editors Name Top 10 Algorithms" (PDF). SIAM News. 33 (4). Archived from the original (PDF) on 2009-04-07. Retrieved 2009-03-31.
- James W. Cooley, Peter A. W. Lewis, and Peter W. Welch, "Historical notes on the fast Fourier transform," Proc. IEEE, vol. 55 (no. 10), p. 1675–1677 (1967).
- Danielson, G. C., and C. Lanczos, "Some improvements in practical Fourier analysis and their application to X-ray scattering from liquids," J. Franklin Inst. 233, 365–380 and 435–452 (1942).
- S. G. Johnson and M. Frigo, "Implementing FFTs in practice," in Fast Fourier Transforms (C. S. Burrus, ed.), ch. 11, Rice University, Houston TX: Connexions, September 2008.
- Singleton, Richard C. (1967). "On computing the fast Fourier transform". Commun. ACM. 10 (10): 647–654. doi:10.1145/363717.363771. S2CID 6287781.
- Duhamel, P., and M. Vetterli, "Fast Fourier transforms: a tutorial review and a state of the art," Signal Processing 19, 259–299 (1990)
- Lundy, T., and J. Van Buskirk, "A new matrix approach to real FFTs and convolutions of length 2k," Computing 80, 23–45 (2007).
- Johnson, S. G., and M. Frigo, "A modified split-radix FFT with fewer arithmetic operations," IEEE Trans. Signal Process. 55 (1), 111–119 (2007).
- Frigo, M.; Johnson, S. G. (2005). "The Design and Implementation of FFTW3" (PDF). Proceedings of the IEEE. 93 (2): 216–231. CiteSeerX 10.1.1.66.3097. doi:10.1109/JPROC.2004.840301. S2CID 6644892.
- Gentleman W. M., and G. Sande, "Fast Fourier transforms—for fun and profit," Proc. AFIPS 29, 563–578 (1966).
- Bailey, David H., "FFTs in external or hierarchical memory," J. Supercomputing 4 (1), 23–35 (1990)
- M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran. Cache-oblivious algorithms. In Proceedings of the 40th IEEE Symposium on Foundations of Computer Science (FOCS 99), p.285-297. 1999. Extended abstract at IEEE, at Citeseer.
- Cooley, J. W., P. Lewis and P. Welch, "The Fast Fourier Transform and its Applications", IEEE Trans on Education 12, 1, 28–34 (1969)
- al.], Thomas H. Cormen ... [et; Leiserson, Charles; Rivest, Ronald; Stein, Clifford (2009). Introduction to algorithms (3rd ed.). Cambridge, Mass.: MIT Press. pp. 915–918. ISBN 978-0-262-03384-8.
- Karp, Alan H. (1996). "Bit reversal on uniprocessors". SIAM Review. 38 (1): 1–26. CiteSeerX 10.1.1.24.2913. doi:10.1137/1038001. JSTOR 2132972.
- Carter, Larry; Gatlin, Kang Su (1998). "Towards an optimal bit-reversal permutation program". Proceedings 39th Annual Symposium on Foundations of Computer Science (Cat. No.98CB36280). pp. 544–553. CiteSeerX 10.1.1.46.9319. doi:10.1109/SFCS.1998.743505. ISBN 978-0-8186-9172-0. S2CID 14307262.
- Rubio, M.; Gómez, P.; Drouiche, K. (2002). "A new superfast bit reversal algorithm". International Journal of Adaptive Control and Signal Processing. 16 (10): 703–707. doi:10.1002/acs.718. S2CID 62201722.
- Originally attributed to Stockham in W. T. Cochran et al., What is the fast Fourier transform?, Proc. IEEE vol. 55, 1664–1674 (1967).
- P. N. Swarztrauber, FFT algorithms for vector computers, Parallel Computing vol. 1, 45–63 (1984).
- Swarztrauber, P. N. (1982). "Vectorizing the FFTs". In Rodrigue, G. (ed.). Parallel Computations. New York: Academic Press. pp. 51–83. ISBN 978-0-12-592101-5.
- Pease, M. C. (1968). "An adaptation of the fast Fourier transform for parallel processing". J. ACM. 15 (2): 252–264. doi:10.1145/321450.321457. S2CID 14610645.
- Frigo, Matteo; Johnson, Steven G. "FFTW". A free (GPL) C library for computing discrete Fourier transforms in one or more dimensions, of arbitrary size, using the Cooley–Tukey algorithm
- Johnson, H. W.; Burrus, C. S. (1984). "An in-place in-order radix-2 FFT". Proc. ICASSP: 28A.2.1–28A.2.4.
- Temperton, C. (1991). "Self-sorting in-place fast Fourier transform". SIAM Journal on Scientific and Statistical Computing. 12 (4): 808–823. doi:10.1137/0912043.
- Qian, Z.; Lu, C.; An, M.; Tolimieri, R. (1994). "Self-sorting in-place FFT algorithm with minimum working space". IEEE Trans. ASSP. 52 (10): 2835–2836. Bibcode:1994ITSP...42.2835Q. doi:10.1109/78.324749.
- Hegland, M. (1994). "A self-sorting in-place fast Fourier transform algorithm suitable for vector and parallel processing". Numerische Mathematik. 68 (4): 507–547. CiteSeerX 10.1.1.54.5659. doi:10.1007/s002110050074. S2CID 121258187.
External links
- "Fast Fourier transform - FFT". Cooley-Tukey technique. Article. 10.
A simple, pedagogical radix-2 algorithm in C++
- "KISSFFT". GitHub. 11 February 2022.
A simple mixed-radix Cooley–Tukey implementation in C
- Dsplib on GitHub
- "Radix-2 Decimation in Time FFT Algorithm". Archived from the original on October 31, 2017. "Алгоритм БПФ по основанию два с прореживанием по времени" (in Russian).
- "Radix-2 Decimation in Frequency FFT Algorithm". Archived from the original on November 14, 2017. "Алгоритм БПФ по основанию два с прореживанием по частоте" (in Russian).