Code page 932 (Microsoft Windows)
Microsoft Windows code page 932 (abbreviated MS932,[1][2] Windows-932[2] or ambiguously CP932[3]), also called Windows-31J amongst other names (see § Terminology below), is the Microsoft Windows code page for the Japanese language, which is an extended variant of the Shift JIS Japanese character encoding. It contains standard 7-bit ASCII codes, and Japanese characters are indicated by the high bit of the first byte being set to 1. Some code points in this page require a second byte, so characters use either 8 or 16 bits for encoding.
| MIME / IANA | Windows-31J |
|---|---|
| Alias(es) | CP943C |
| Language(s) | Japanese |
| Standard | WHATWG Encoding Standard (as "Shift_JIS") |
| Classification | Extended ASCII,[lower-alpha 1] variable-width encoding, CJK encoding |
| Extends | Shift_JIS |
| |
IBM offer the same extended double-byte codes in their code page 943 (IBM-943 or CP943),[4] which is a combination of the single-byte Code page 897 and the double-byte Code page 941.[5]
Windows-31J is the most used non-UTF-8/Unicode Japanese encoding on the web. However, many people and software packages, including Microsoft libraries,[6] declare the Shift JIS encoding for Windows-31J data, although it includes some additional characters, and some of the existing characters are mapped to Unicode differently. This has led the WHATWG HTML standard to treat the encoding labels shift_jis and windows-31j interchangeably, and use the Windows variant for its "Shift_JIS" encoder and decoder.
Terminology
Microsoft's Shift JIS variant is known simply as "Code page 932" on Microsoft Windows, however this is ambiguous as IBM's code page 932, while also a Shift JIS variant, lacks the NEC and NEC-selected double-byte vendor extensions which are present in Microsoft's variant (although both include the IBM extensions) and preserves the 1978 ordering of JIS X 0208.[4]
IBM's code page 943 (or "IBM-943") includes the same double byte codes as Windows code page 932.[4] Microsoft's version corresponds closely to the encoding referred to as ibm-943_P15A-2003 (with aliases including CP943C and Windows-932)[2] in International Components for Unicode (ICU). There is also a second ICU encoding named ibm-943_P130-1999,[7] which uses different single-byte mappings which more closely match IBM's code page definitions. (See § Single-byte character differences below for details.)
Windows code page 932 is registered with the IANA as Windows-31J.[8] The "Windows-31J" label is IANA's and not recognized by Microsoft, which has historically used "shift_jis" instead.[6] The W3C/WHATWG encoding standard used by HTML5 treats the label "shift_jis" interchangeably with "windows-31j" with the intent of being "compatible with deployed content"[9] and matches Windows code page 932 (including the "formerly proprietary extensions from IBM and NEC").[10]
Windows code page 932 is also called MS_Kanji,[2][11] although IANA treat MS_Kanji as an alias for standard Shift JIS.[8] Python, for example, uses the label MS-Kanji (or cp932) for Windows-932 and the label Shift_JIS (or sjis) for JIS X 0208-defined Shift JIS, without recognising the Windows-31J label.[11]
In Japanese editions of Windows, this code page is referred to as "ANSI", since it is the operating system's default 8-bit encoding, even though ANSI was not involved in its definition.
Differences from standard Shift JIS
Windows-31J is often mistaken for standard Shift JIS (as defined in JIS X 0208:1997 Appendix 1): while similar, the distinction is significant for computer programmers wishing to avoid mojibake.
Double-byte character differences
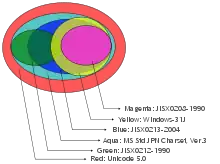
In addition to the standard JIS X 0201:1997 and JIS X 0208:1997 characters, Windows-31J includes several JIS X 0208 extensions, namely "NEC special characters (Row 13), NEC selection of IBM extensions (Rows 89 to 92), and IBM extensions (Rows 115 to 119)",[8] in addition to setting some encoding space aside for end user definition.[12] This also differs from IBM-932, which does not include the NEC extensions or NEC selection.[4]
The IBM extensions were designed to encode characters from the IBM Japanese DBCS-Host repertoire which were initially absent in JIS X 0208; the 'because' sign ∵ and 'not' sign ¬ were later added to JIS X 0208 itself in 1983, and Microsoft includes them at extension locations as well as their 1983 locations.[13] The NEC extensions also encode the entirety of the IBM repertoire, but in a separate extension within the 94×94 JIS X 0208 grid (in rows 89–92, besides the characters already included in NEC row 13), rather than using Shift JIS codes beyond the JIS X 0208 range; Windows code page 932 includes these 388 characters in both locations.[13] As a result, the because and not signs are encoded three times.
Some of these representations were subsequently used for different characters by JIS X 0213 and Shift JIS-2004. For example, compare row 89 in JIS X 0213 (beginning 硃, 硎, 硏…)[14] to row 89 as used by JIS X 0208 with IBM/NEC extensions (beginning 纊, 褜, 鍈…).[15] Consequently, Shift JIS-2004 is not compatible with Windows-31J.
In addition to the above, Microsoft uses different (but visually similar) Unicode mapping for several double-byte punctuation characters compared to standard Shift JIS, such as the wave dash being mapped to U+FF5E rather than U+301C,[16] which is followed by ibm-943_P15A-2003[17] but not ibm-943_P130-1999,[18] and using different mapping for the double byte backslash.[16]
Single-byte character differences
Windows-932 includes standard 7-bit ASCII mappings for single-byte sequences with the high bit set to 0. Hence, codes 0x5C and 0x7E are mapped to Unicode as U+005C REVERSE SOLIDUS (\, the backslash) and U+007E TILDE (~) respectively,[19][20][16] as they are in ASCII (ISO-646-US). This is likewise done by the W3C/WHATWG encoding standard.[21] By contrast, 0x5C is mapped to U+00A5 YEN SIGN (¥) in ISO-646-JP and consequently JIS X 0201, of which standard Shift JIS is an extension. Correspondingly, Windows-31J avoids duplicate encoding of the backslash by mapping the double byte 0x815F to U+FF3C FULLWIDTH REVERSE SOLIDUS, whereas standard Shift JIS maps it to U+005C.[16]
However, 0x5C in Windows-932 is nonetheless considered a Yen sign in certain contexts.[22] For this reason, in many Japanese fonts, U+005C is displayed as a Yen symbol, which would normally be represented as U+00A5, rather than as a backslash per Unicode's suggested rendering. U+00A5 is one-way best-fit mapped onto 0x5C in Windows-932. However, code 0x5C in Windows-932 behaves as a reverse solidus (backslash) in all respects (e.g. in file paths on Windows systems) other than how it is displayed by some fonts,[22] and Microsoft's documentation for Windows-932 displays 0x5C as a backslash.[20] This mapping[19] corresponds to the encoding named "ibm-943_P15A-2003" in International Components for Unicode (ICU),[2] except for minor reordering of a few C0 control characters.
IBM-943, like IBM-932,[4] is a superset of the single-byte Code page 897,[5] which maps 0x5C to the Yen symbol (¥) and 0x7E to the overline (‾),[23] this is followed by the encoding named "ibm-943_P130-1999" in ICU.[7] Code page 897 (and therefore also IBM-943 and IBM-932) also adds single-byte box-drawing characters replacing certain C0 control characters,[23] however these may still be treated as control characters depending on the context,[24] and are mapped to control characters in ICU.[7]
Layout
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
See also
References
- Sivonen, Henri. "Bug 27851 - Add MS932 as a label of Shift_JIS". w3.org Bug Tracker.
- "Converter Explorer: ibm-943_P15A-2003 (alias windows-31j)". International Components for Unicode: ICU Demonstration.
- Aoki, Osamu. "Chapter 11. Data conversion". Debian Reference. Debian.
- "IBM-943 and IBM-932". IBM Knowledge Center. IBM.
- "Coded character set identifiers - CCSID 943". IBM Globalization. IBM. Archived from the original on 2016-03-15.
- "Encoding.WindowsCodePage Property - .NET Framework (current version)". MSDN. Microsoft.
- "Converter Explorer: ibm-943_P130-1999". International Components for Unicode: ICU Demonstration.
- "Character Sets". IANA.
- van Kesteren, Anne. "4.2. Names and labels". Encoding Standard. WHATWG.
- van Kesteren, Anne. "5. Indexes (§ Index jis0208)". Encoding Standard. WHATWG.
- "7.2.3. Standard Encodings". Python 3.6 Documentation. Python Software Foundation. Retrieved 19 September 2017.
- Kaplan, Michael S (2007-05-26). "The PUA outside of Unicode". Sorting it all out.
- Lunde, Ken (2009). "Appendix E: Vendor Character Set Standards" (PDF). CJKV Information Processing: Chinese, Japanese, Korean & Vietnamese Computing (2nd ed.). Sebastopol, CA: O'Reilly. ISBN 978-0-596-51447-1.
- Japanese Industrial Standards Committee (2004-04-13). Japanese Graphic Character Set for Information Interchange, Plane 1 (PDF). ITSCJ/IPSJ. ISO-IR-233.
- van Kesteren, Anne. "Index jis0208 visualization". Encoding Standard. WHATWG.
- "Ambiguities in conversion from Shift-JIS to Unicode (Non-Normative)". XML Japanese Profile. W3C.
- "Converter Explorer: ibm-943_P15A-2003: start byte 0x81". ICU Demonstration. International Components for Unicode.
- "Converter Explorer: ibm-943_P130-1999: start byte 0x81". ICU Demonstration. International Components for Unicode.
- "CP932.TXT". Unicode Consortium.
- "Lead byte NULL — Code page 932". Microsoft.
- van Kesteren, Anne. "12.3.1. Shift_JIS decoder". Encoding Standard. WHATWG.
If byte is an ASCII byte or 0x80, return a code point whose value is byte.
- Kaplan, Michael S. (2005-09-17). "When is a backslash not a backslash?". Sorting it all out.
- "CP00897.txt". IBM. Archived from the original on 2019-01-12. Retrieved 2017-09-24.
- "Code page identifiers - CP 00897". IBM Globalization. IBM. Archived from the original on 2016-03-17.
External links
Microsoft related
IBM related
- IBM's documentation of Code Page 943
- ICU Code Page 943 (ibm-943_P130-1999) demonstration
- ICU mapping for ibm-943_P130-1999 to Unicode
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |