Btrfs
Btrfs (pronounced as "better F S",[8] "butter F S",[11][12] "b-tree F S",[12] or B.T.R.F.S.) is a computer storage format that combines a file system based on the copy-on-write (COW) principle with a logical volume manager (not to be confused with Linux's LVM), developed together. It was founded by Chris Mason in 2007[13] for use in Linux, and since November 2013, the file system's on-disk format has been declared stable in the Linux kernel.[14]
| Developer(s) | SUSE, Meta, Western Digital, Oracle Corporation, Fujitsu, Fusion-io, Intel, The Linux Foundation, Red Hat, and Strato AG[1] |
|---|---|
| Full name | B-tree file system |
| Introduced | Linux kernel 2.6.29, March 2009 |
| Structures | |
| Directory contents | B-tree |
| File allocation | Extents |
| Bad blocks | None recorded |
| Limits | |
| Max volume size | 16 EiB[2][lower-alpha 1] |
| Max file size | 16 EiB[2][lower-alpha 1] |
| Max no. of files | 264[lower-alpha 2][3] |
| Max filename length | 255 ASCII characters (fewer for multibyte character encodings such as Unicode) |
| Allowed filename characters | All except '/' and NUL ('\0') |
| Features | |
| Dates recorded | Creation (otime),[4] modification (mtime), attribute modification (ctime), and access (atime) |
| Date range | 64-bit signed int offset from 1970-01-01T00:00:00Z[5] |
| Date resolution | Nanosecond |
| Attributes | POSIX and extended attributes |
| File system permissions | Unix permissions, POSIX ACLs |
| Transparent compression | Yes (zlib, LZO[6] and (since 4.14) ZSTD[7]) |
| Transparent encryption | Planned[8] |
| Data deduplication | Yes[9] |
| Copy-on-write | Yes |
| Other | |
| Supported operating systems | Linux, ReactOS[10] |
| Website | docs |
Btrfs is intended to address the lack of pooling, snapshots, checksums, and integral multi-device spanning in Linux file systems.[8] Chris Mason, the principal Btrfs author, stated that its goal was "to let [Linux] scale for the storage that will be available. Scaling is not just about addressing the storage but also means being able to administer and to manage it with a clean interface that lets people see what's being used and makes it more reliable".[15]
History
The core data structure of Btrfs—the copy-on-write B-tree—was originally proposed by IBM researcher Ohad Rodeh at a presentation at USENIX 2007.[16] Chris Mason, an engineer working on ReiserFS for SUSE at the time, joined Oracle later that year and began work on a new file system based on these B-trees.[17]
In 2008, the principal developer of the ext3 and ext4 file systems, Theodore Ts'o, stated that although ext4 has improved features, it is not a major advance; it uses old technology and is a stop-gap. Ts'o said that Btrfs is the better direction because "it offers improvements in scalability, reliability, and ease of management".[18] Btrfs also has "a number of the same design ideas that reiser3/4 had".[19]
Btrfs 1.0, with finalized on-disk format, was originally slated for a late-2008 release,[20] and was finally accepted into the Linux kernel mainline in 2009.[21] Several Linux distributions began offering Btrfs as an experimental choice of root file system during installation.[22][23][24]
In July 2011, Btrfs automatic defragmentation and scrubbing features were merged into version 3.0 of the Linux kernel mainline.[25] Besides Mason at Oracle, Miao Xie at Fujitsu contributed performance improvements.[26] In June 2012, Chris Mason left Oracle for Fusion-io, which he left a year later with Josef Bacik to join Facebook. While at both companies, Mason continued his work on Btrfs.[27][17]
In 2012, two Linux distributions moved Btrfs from experimental to production or supported status: Oracle Linux in March,[28] followed by SUSE Linux Enterprise in August.[29]
In 2015, Btrfs was adopted as the default filesystem for SUSE Linux Enterprise Server (SLE) 12.[30]
In August 2017, Red Hat announced in the release notes for Red Hat Enterprise Linux (RHEL) 7.4 that it no longer planned to move Btrfs to a fully supported feature (it's been included as a "technology preview" since RHEL 6 beta) noting that it would remain available in the RHEL 7 release series.[31] Btrfs was removed from RHEL 8 in May 2019.[32] RHEL moved from ext4 in RHEL 6 to XFS in RHEL 7.[33]
In 2020, Btrfs was selected as the default file system for Fedora 33 for desktop variants.[34]
Features
Implemented
As of version 5.0 of the Linux kernel, Btrfs implements the following features:[35][36]
- Mostly self-healing in some configurations due to the nature of copy-on-write
- Online defragmentation and an autodefrag mount option[25]
- Online volume growth and shrinking
- Online block device addition and removal
- Online balancing (movement of objects between block devices to balance load)
- Offline filesystem check[37]
- Online data scrubbing for finding errors and automatically fixing them for files with redundant copies
- RAID 0, RAID 1, and RAID 10[38]
- Subvolumes (one or more separately mountable filesystem roots within each disk partition)
- Transparent compression via zlib, LZO[6] and (since 4.14) ZSTD,[7] configurable per file or volume[39][40]
- Atomic writable (via copy-on-write) or read-only[41] snapshots of subvolumes
- File cloning (reflink, copy-on-write) via
cp --reflink <source file> <destination file>[42] - Checksums on data and metadata (CRC-32C[43]). New hash functions are implemented since 5.5:[44] xxHash, SHA256, BLAKE2B.
- In-place conversion from ext3/4 to Btrfs (with rollback). This feature regressed around btrfs-progs version 4.0, rewritten from scratch in 4.6.[45]
- Union mounting of read-only storage, known as file system seeding (read-only storage used as a copy-on-write backing for a writable Btrfs)[46]
- Block discard (reclaims space on some virtualized setups and improves wear leveling on SSDs with TRIM)
- Send/receive (saving diffs between snapshots to a binary stream)[47]
- Incremental backup[48]
- Out-of-band data deduplication (requires userspace tools)[9]
- Ability to handle swap files and swap partitions
Implemented but not recommended for production use
Cloning
Btrfs provides a clone operation that atomically creates a copy-on-write snapshot of a file. Such cloned files are sometimes referred to as reflinks, in light of the proposed associated Linux kernel system call.[53]
By cloning, the file system does not create a new link pointing to an existing inode; instead, it creates a new inode that initially shares the same disk blocks with the original file. As a result, cloning works only within the boundaries of the same Btrfs file system, but since version 3.6 of the Linux kernel it may cross the boundaries of subvolumes under certain circumstances.[54][55] The actual data blocks are not duplicated; at the same time, due to the copy-on-write (CoW) nature of Btrfs, modifications to any of the cloned files are not visible in the original file and vice versa.[56]
Cloning should not be confused with hard links, which are directory entries that associate multiple file names with a single file. While hard links can be taken as different names for the same file, cloning in Btrfs provides independent files that initially share all their disk blocks.[56][57]
Support for this Btrfs feature was added in version 7.5 of the GNU coreutils, via the --reflink option to the cp command.[58][59]
In addition to data cloning (FICLONE), Btrfs also supports out-of-band deduplication via FIDEDUPERANGE. This functionality allows two files with (even partially) identical data to share storage.[60][9]
Subvolumes and snapshots
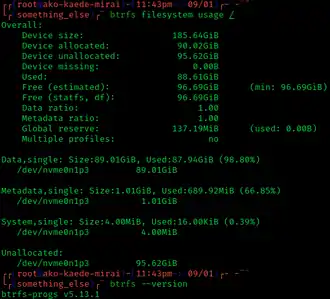
A Btrfs subvolume can be thought of as a separate POSIX file namespace, mountable separately by passing subvol or subvolid options to the utility. It can also be accessed by mounting the top-level subvolume, in which case subvolumes are visible and accessible as its subdirectories.[61]
Subvolumes can be created at any place within the file system hierarchy, and they can also be nested. Nested subvolumes appear as subdirectories within their parent subvolumes, similarly to the way a top-level subvolume presents its subvolumes as subdirectories. Deleting a subvolume is not possible until all subvolumes below it in the nesting hierarchy are deleted; as a result, top-level subvolumes cannot be deleted.[62]
Any Btrfs file system always has a default subvolume, which is initially set to be the top-level subvolume, and is mounted by default if no subvolume selection option is passed to mount. The default subvolume can be changed as required.[62]
A Btrfs snapshot is a subvolume that shares its data (and metadata) with some other subvolume, using Btrfs' copy-on-write capabilities, and modifications to a snapshot are not visible in the original subvolume. Once a writable snapshot is made, it can be treated as an alternate version of the original file system. For example, to roll back to a snapshot, a modified original subvolume needs to be unmounted and the snapshot needs to be mounted in its place. At that point, the original subvolume may also be deleted.[61]
The copy-on-write (CoW) nature of Btrfs means that snapshots are quickly created, while initially consuming very little disk space. Since a snapshot is a subvolume, creating nested snapshots is also possible. Taking snapshots of a subvolume is not a recursive process; thus, if a snapshot of a subvolume is created, every subvolume or snapshot that the subvolume already contains is mapped to an empty directory of the same name inside the snapshot.[61][62]
Taking snapshots of a directory is not possible, as only subvolumes can have snapshots. However, there is a workaround that involves reflinks spread across subvolumes: a new subvolume is created, containing cross-subvolume reflinks to the content of the targeted directory. Having that available, a snapshot of this new volume can be created.[54]
A subvolume in Btrfs is quite different from a traditional Logical Volume Manager (LVM) logical volume. With LVM, a logical volume is a separate block device, while a Btrfs subvolume is not and it cannot be treated or used that way.[61] Making dd or LVM snapshots of btrfs leads to data loss if either the original or the copy is mounted while both are on the same computer.[63]
Send–receive
Given any pair of subvolumes (or snapshots), Btrfs can generate a binary diff between them (by using the btrfs send command) that can be replayed later (by using btrfs receive), possibly on a different Btrfs file system. The send–receive feature effectively creates (and applies) a set of data modifications required for converting one subvolume into another.[47][64]
The send/receive feature can be used with regularly scheduled snapshots for implementing a simple form of file system replication, or for the purpose of performing incremental backups.[47][64]
Quota groups
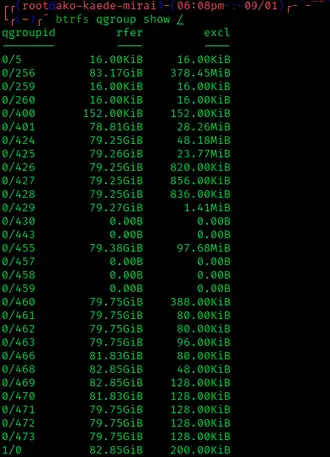
A quota group (or qgroup) imposes an upper limit to the space a subvolume or snapshot may consume. A new snapshot initially consumes no quota because its data is shared with its parent, but thereafter incurs a charge for new files and copy-on-write operations on existing files. When quotas are active, a quota group is automatically created with each new subvolume or snapshot. These initial quota groups are building blocks which can be grouped (with the btrfs qgroup command) into hierarchies to implement quota pools.[49]
Quota groups only apply to subvolumes and snapshots, while having quotas enforced on individual subdirectories, users, or user groups is not possible. However, workarounds are possible by using different subvolumes for all users or user groups that require a quota to be enforced.
In-place conversion from ext2/3/4 and ReiserFS
As the result of having very little metadata anchored in fixed locations, Btrfs can warp to fit unusual spatial layouts of the backend storage devices. The btrfs-convert tool exploits this ability to do an in-place conversion of an ext2/3/4 or ReiserFS file system, by nesting the equivalent Btrfs metadata in its unallocated space—while preserving an unmodified copy of the original file system.[65]
The conversion involves creating a copy of the whole ext2/3/4 metadata, while the Btrfs files simply point to the same blocks used by the ext2/3/4 files. This makes the bulk of the blocks shared between the two filesystems before the conversion becomes permanent. Thanks to the copy-on-write nature of Btrfs, the original versions of the file data blocks are preserved during all file modifications. Until the conversion becomes permanent, only the blocks that were marked as free in ext2/3/4 are used to hold new Btrfs modifications, meaning that the conversion can be undone at any time (although doing so will erase any changes made after the conversion to Btrfs).[65]
All converted files are available and writable in the default subvolume of the Btrfs. A sparse file holding all of the references to the original ext2/3/4 filesystem is created in a separate subvolume, which is mountable on its own as a read-only disk image, allowing both original and converted file systems to be accessed at the same time. Deleting this sparse file frees up the space and makes the conversion permanent.[65]
In 4.x versions of the mainline Linux kernel, the in-place ext3/4 conversion was considered untested and rarely used.[65] However, the feature was rewritten from scratch in 2016 for btrfs-progs 4.6.[45] and has been considered stable since then.
In-place conversion from ReiserFS was introduced in September 2017 with kernel 4.13.[66]
Union mounting / seed devices
When creating a new Btrfs, an existing Btrfs can be used as a read-only "seed" file system.[67] The new file system will then act as a copy-on-write overlay on the seed, as a form of union mounting. The seed can be later detached from the Btrfs, at which point the rebalancer will simply copy over any seed data still referenced by the new file system before detaching. Mason has suggested this may be useful for a Live CD installer, which might boot from a read-only Btrfs seed on an optical disc, rebalance itself to the target partition on the install disk in the background while the user continues to work, then eject the disc to complete the installation without rebooting.[68]
Encryption
In his 2009 interview, Chris Mason stated that support for encryption was planned for Btrfs.[69] In the meantime, a workaround for combining encryption with Btrfs is to use a full-disk encryption mechanism such as dm-crypt / LUKS on the underlying devices and to create the Btrfs filesystem on top of that layer.
As of 2020, the developers were working to add keyed hash like HMAC (SHA256).[70]
Checking and recovery
Unix systems traditionally rely on "fsck" programs to check and repair filesystems. This functionality is implemented via the btrfs check program. Since version 4.0 this functionality is deemed relatively stable. However, as of December 2022, the btrfs documentation suggests that its --repair option be used only if you have been advised by "a developer or an experienced user".[71] As of August 2022, the SLE documentation recommends using a Live CD, performing a backup and only using the repair option as a last resort.[72]
There is another tool, named btrfs-restore, that can be used to recover files from an unmountable filesystem, without modifying the broken filesystem itself (i.e., non-destructively).[73][74]
In normal use, Btrfs is mostly self-healing and can recover from broken root trees at mount time, thanks to making periodic data flushes to permanent storage, by default every 30 seconds. Thus, isolated errors will cause a maximum of 30 seconds of filesystem changes to be lost at the next mount.[75] This period can be changed by specifying a desired value (in seconds) with the commit mount option.[76][77]
Design
Ohad Rodeh's original proposal at USENIX 2007 noted that B+ trees, which are widely used as on-disk data structures for databases, could not efficiently allow copy-on-write-based snapshots because its leaf nodes were linked together: if a leaf was copied on write, its siblings and parents would have to be as well, as would their siblings and parents and so on until the entire tree was copied. He suggested instead a modified B-tree (which has no leaf linkage), with a refcount associated to each tree node but stored in an ad hoc free map structure and certain relaxations to the tree's balancing algorithms to make them copy-on-write friendly. The result would be a data structure suitable for a high-performance object store that could perform copy-on-write snapshots, while maintaining good concurrency.[16]
At Oracle later that year, Chris Mason began work on a snapshot-capable file system that would use this data structure almost exclusively—not just for metadata and file data, but also recursively to track space allocation of the trees themselves. This allowed all traversal and modifications to be funneled through a single code path, against which features such as copy on write, checksumming and mirroring needed to be implemented only once to benefit the entire file system.[78]
Btrfs is structured as several layers of such trees, all using the same B-tree implementation. The trees store generic items sorted by a 136-bit key. The most significant 64 bits of the key are a unique object id. The middle eight bits are an item type field: its use is hardwired into code as an item filter in tree lookups. Objects can have multiple items of multiple types. The remaining (least significant) 64 bits are used in type-specific ways. Therefore, items for the same object end up adjacent to each other in the tree, grouped by type. By choosing certain key values, objects can further put items of the same type in a particular order.[78][3]
Interior tree nodes are simply flat lists of key-pointer pairs, where the pointer is the logical block number of a child node. Leaf nodes contain item keys packed into the front of the node and item data packed into the end, with the two growing toward each other as the leaf fills up.[78]
File system tree
Within each directory, directory entries appear as directory items, whose least significant bits of key values are a CRC32C hash of their filename. Their data is a location key, or the key of the inode item it points to. Directory items together can thus act as an index for path-to-inode lookups, but are not used for iteration because they are sorted by their hash, effectively randomly permuting them. This means user applications iterating over and opening files in a large directory would thus generate many more disk seeks between non-adjacent files—a notable performance drain in other file systems with hash-ordered directories such as ReiserFS,[79] ext3 (with Htree-indexes enabled[80]) and ext4, all of which have TEA-hashed filenames. To avoid this, each directory entry has a directory index item, whose key value of the item is set to a per-directory counter that increments with each new directory entry. Iteration over these index items thus returns entries in roughly the same order as stored on disk.
Files with hard links in multiple directories have multiple reference items, one for each parent directory. Files with multiple hard links in the same directory pack all of the links' filenames into the same reference item. This was a design flaw that limited the number of same-directory hard links to however many could fit in a single tree block. (On the default block size of 4 KiB, an average filename length of 8 bytes and a per-filename header of 4 bytes, this would be less than 350.) Applications which made heavy use of multiple same-directory hard links, such as git, GNUS, GMame and BackupPC were observed to fail at this limit.[81] The limit was eventually removed[82] (and as of October 2012 has been merged[83] pending release in Linux 3.7) by introducing spillover extended reference items to hold hard link filenames which do not otherwise fit.
Extents
File data is kept outside the tree in extents, which are contiguous runs of disk data blocks. Extent blocks default to 4 KiB in size, do not have headers and contain only (possibly compressed) file data. In compressed extents, individual blocks are not compressed separately; rather, the compression stream spans the entire extent.
Files have extent data items to track the extents which hold their contents. The item's key value is the starting byte offset of the extent. This makes for efficient seeks in large files with many extents, because the correct extent for any given file offset can be computed with just one tree lookup.
Snapshots and cloned files share extents. When a small part of a large such extent is overwritten, the resulting copy-on-write may create three new extents: a small one containing the overwritten data, and two large ones with unmodified data on either side of the overwrite. To avoid having to re-write unmodified data, the copy-on-write may instead create bookend extents, or extents which are simply slices of existing extents. Extent data items allow for this by including an offset into the extent they are tracking: items for bookends are those with non-zero offsets.[3]
Extent allocation tree
The extent allocation tree acts as an allocation map for the file system. Unlike other trees, items in this tree do not have object ids. They represent regions of space: their key values hold the starting offsets and lengths of the regions they represent.
The file system divides its allocated space into block groups which are variable-sized allocation regions that alternate between preferring metadata extents (tree nodes) and data extents (file contents). The default ratio of data to metadata block groups is 1:2. They are intended to use concepts of the Orlov block allocator to allocate related files together and resist fragmentation by leaving free space between groups. (Ext3 block groups, however, have fixed locations computed from the size of the file system, whereas those in Btrfs are dynamic and created as needed.) Each block group is associated with a block group item. Inode items in the file system tree include a reference to their current block group.[3]
Extent items contain a back-reference to the tree node or file occupying that extent. There may be multiple back-references if the extent is shared between snapshots. If there are too many back-references to fit in the item, they spill out into individual extent data reference items. Tree nodes, in turn, have back-references to their containing trees. This makes it possible to find which extents or tree nodes are in any region of space by doing a B-tree range lookup on a pair of offsets bracketing that region, then following the back-references. For relocating data, this allows an efficient upwards traversal from the relocated blocks to quickly find and fix all downwards references to those blocks, without having to scan the entire file system. This, in turn, allows the file system to efficiently shrink, migrate, and defragment its storage online.
The extent allocation tree, as with all other trees in the file system, is copy-on-write. Writes to the file system may thus cause a cascade whereby changed tree nodes and file data result in new extents being allocated, causing the extent tree itself to change. To avoid creating a feedback loop, extent tree nodes which are still in memory but not yet committed to disk may be updated in place to reflect new copied-on-write extents.
In theory, the extent allocation tree makes a conventional free-space bitmap unnecessary because the extent allocation tree acts as a B-tree version of a BSP tree. In practice, however, an in-memory red–black tree of page-sized bitmaps is used to speed up allocations. These bitmaps are persisted to disk (starting in Linux 2.6.37, via the space_cache mount option[84]) as special extents that are exempt from checksumming and copy-on-write.
Checksum tree and scrubbing
CRC-32C checksums are computed for both data and metadata and stored as checksum items in a checksum tree. There is room for 256 bits of metadata checksums and up to a full node (roughly 4 KB or more) for data checksums. Btrfs has provisions for additional checksum algorithms to be added in future versions of the file system.[35][85]
There is one checksum item per contiguous run of allocated blocks, with per-block checksums packed end-to-end into the item data. If there are more checksums than can fit, they spill into another checksum item in a new leaf. If the file system detects a checksum mismatch while reading a block, it first tries to obtain (or create) a good copy of this block from another device – if internal mirroring or RAID techniques are in use.[86][87]
Btrfs can initiate an online check of the entire file system by triggering a file system scrub job that is performed in the background. The scrub job scans the entire file system for integrity and automatically attempts to report and repair any bad blocks it finds along the way.[86][88]
Log tree
An fsync request commits modified data immediately to stable storage. fsync-heavy workloads (like a database or a virtual machine whose running OS fsyncs frequently) could potentially generate a great deal of redundant write I/O by forcing the file system to repeatedly copy-on-write and flush frequently modified parts of trees to storage. To avoid this, a temporary per-subvolume log tree is created to journal fsync-triggered copies on write. Log trees are self-contained, tracking their own extents and keeping their own checksum items. Their items are replayed and deleted at the next full tree commit or (if there was a system crash) at the next remount.
Chunk and device trees
Block devices are divided into physical chunks of 1 GiB for data and 256 MiB for metadata.[89] Physical chunks across multiple devices can be mirrored or striped together into a single logical chunk. These logical chunks are combined into a single logical address space that the rest of the filesystem uses.
The chunk tree tracks this by storing each device therein as a device item and logical chunks as chunk map items, which provide a forward mapping from logical to physical addresses by storing their offsets in the least significant 64 bits of their key. Chunk map items can be one of several different types:
- single
- 1 logical to 1 physical chunk
- dup
- 1 logical chunk to 2 physical chunks on 1 block device
- raid0
- N logical chunks to N≥2 physical chunks across N≥2 block devices
- raid1
- 1 logical chunk to 2 physical chunks across 2 out of N≥2 block devices,[90] in contrast to conventional RAID 1 which has N physical chunks
- raid1c3
- 1 logical chunk to 3 physical chunks out of N≥3 block devices
- raid1c4
- 1 logical chunk to 4 physical chunks out of N≥4 block devices
- raid5
- N (for N≥2) logical chunks to N+1 physical chunks across N+1 block devices, with 1 physical chunk used as parity
- raid6
- N (for N≥2) logical chunks to N+2 physical chunks across N+2 block devices, with 2 physical chunks used as parity
N is the number of block devices still having free space when the chunk is allocated. If N is not large enough for the chosen mirroring/mapping, then the filesystem is effectively out of space.
Relocation trees
Defragmentation, shrinking, and rebalancing operations require extents to be relocated. However, doing a simple copy-on-write of the relocating extent will break sharing between snapshots and consume disk space. To preserve sharing, an update-and-swap algorithm is used, with a special relocation tree serving as scratch space for affected metadata. The extent to be relocated is first copied to its destination. Then, by following backreferences upward through the affected subvolume's file system tree, metadata pointing to the old extent is progressively updated to point at the new one; any newly updated items are stored in the relocation tree. Once the update is complete, items in the relocation tree are swapped with their counterparts in the affected subvolume, and the relocation tree is discarded.[91]
Superblock
All the file system's trees—including the chunk tree itself—are stored in chunks, creating a potential bootstrapping problem when mounting the file system. To bootstrap into a mount, a list of physical addresses of chunks belonging to the chunk and root trees are stored in the superblock.[92]
Superblock mirrors are kept at fixed locations:[93] 64 KiB into every block device, with additional copies at 64 MiB, 256 GiB and 1 PiB. When a superblock mirror is updated, its generation number is incremented. At mount time, the copy with the highest generation number is used. All superblock mirrors are updated in tandem, except in SSD mode which alternates updates among mirrors to provide some wear levelling.
Commercial support
Supported
- Oracle Linux from version 7[94][95]
- SUSE Linux Enterprise Server from version 12[96][97]
- Synology DiskStation Manager (DSM) from version 6.0[98]
No longer supported
- Btrfs was included as a "technology preview" in Red Hat Enterprise Linux 6 and 7;[22][31] it was removed in RHEL 8 in 2018.[32][99][100]
- Btrfs was layered over mdadm-raid arrays in Netgear ReadyNAS arm-based 1xx and intel-based 3xx around 2013 (probably to exploit btrfs checksums and snapshots while avoiding still unstable btrfs-raid functionalities). Updates to Debian Jessie based OS6 were still offered around 2022 (perhaps considered still supported ?).
See also
- APFS – a copy-on-write file system for macOS, iPadOS, iOS, tvOS and watchOS
- Bcachefs
- Comparison of file systems
- HAMMER – DragonFly BSD's file system that uses B-trees, paired with checksums as a countermeasure for data corruption
- List of file systems
- ReFS – a copy-on-write file system for Windows Server 2012
- ZFS
Notes
- This is the Btrfs' own on-disk size limit. The limit is reduced down to 8 EiB on 64-bit systems and 2 EiB on 32-bit systems due to Linux kernel's internal limits, unless kernel's
CONFIG_LBDconfiguration option (available since the 2.6.x kernel series) is enabled to remove these kernel limits.[lower-alpha 3][lower-alpha 4] - Every item in Btrfs has a 64-bit identifier, which means the most files one can have on a Btrfs filesystem is 264.
- Andreas Jaeger (15 February 2005). "Large File Support in Linux". users.suse.com. Retrieved 12 August 2015.
- "Linux kernel configuration help for CONFIG_LBD in 2.6.29 on x86". kernel.xc.net. Archived from the original on 6 September 2015. Retrieved 12 August 2015.
References
- "Contributors at BTRFS documentation". kernel.org. 15 June 2022. Retrieved 5 December 2022.
- "Suse Documentation: Storage Administration Guide – Large File Support in Linux". SUSE. Retrieved 12 August 2015.
- Mason, Chris. "Btrfs design". Btrfs wiki. Retrieved 8 November 2011.
- Jonathan Corbet (26 July 2010). "File creation times". LWN.net. Retrieved 15 August 2015.
- "On-disk Format - btrfs Wiki". btrfs.wiki.kernel.org.
- "btrfs Wiki". kernel.org. Retrieved 19 April 2015.
- "Linux_4.14 - Linux Kernel Newbies". kernelnewbies.org.
- McPherson, Amanda (22 June 2009). "A Conversation with Chris Mason on BTRfs: the next generation file system for Linux". Linux Foundation. Archived from the original on 27 June 2012. Retrieved 1 September 2009.
- "Deduplication". kernel.org. Retrieved 19 April 2015.
- "ReactOS 0.4.1 Released". reactos.org. Retrieved 11 August 2016.
- "Archived copy". Event occurs at 1m 15s. Archived from the original on 18 August 2016. Retrieved 6 February 2016.
{{cite web}}: CS1 maint: archived copy as title (link) - Henson, Valerie (31 January 2008). Chunkfs: Fast file system check and repair. Melbourne, Australia. Event occurs at 18m 49s. Retrieved 5 February 2008.
It's called Butter FS or B-tree FS, but all the cool kids say Butter FS
- Salter, Jim (24 September 2021). "Examining btrfs, Linux's perpetually half-finished filesystem". Ars Technica. Retrieved 11 June 2023.
Chris Mason is the founding developer of btrfs, which he began working on in 2007 while working at Oracle. This leads many people to believe that btrfs is an Oracle project—it is not. The project belonged to Mason, not to his employer, and it remains a community project unencumbered by corporate ownership to this day.
- "Linux kernel commit changing stability status in fs/btrfs/Kconfig". Retrieved 8 February 2019.
- Kerner, Sean Michael (30 October 2008). "A Better File System for Linux?". InternetNews.com. Archived from the original on 8 April 2011. Retrieved 27 August 2020.
- Rodeh, Ohad (2007). B-trees, shadowing, and clones (PDF). USENIX Linux Storage & Filesystem Workshop. Also Rodeh, Ohad (2008). "B-trees, shadowing, and clones". ACM Transactions on Storage. 3 (4): 1–27. doi:10.1145/1326542.1326544. S2CID 207166167.
- "Lead Btrfs File-System Developers Join Facebook". phoronix.com. Retrieved 19 April 2015.
- Paul, Ryan (13 April 2009). "Panelists ponder the kernel at Linux Collaboration Summit". Ars Technica. Archived from the original on 17 June 2012. Retrieved 22 August 2009.
{{cite journal}}: Cite journal requires|journal=(help) - Ts'o, Theodore (1 August 2008). "Re: reiser4 for 2.6.27-rc1". linux-kernel (Mailing list). Retrieved 31 December 2010.
- "Development timeline". Btrfs wiki. 11 December 2008. Archived from the original on 20 December 2008. Retrieved 5 November 2011.
- Wuelfing, Britta (12 January 2009). "Kernel 2.6.29: Corbet Says Btrfs Next Generation Filesystem". Linux Magazine. Retrieved 5 November 2011.
- "Red Hat Enterprise Linux 6 documentation: Technology Previews". Archived from the original on 28 May 2011. Retrieved 21 January 2011.
- "Fedora Weekly News Issue 276". 25 May 2011.
- "Debian 6.0 "Squeeze" released" (Press release). Debian. 6 February 2011. Retrieved 8 February 2011.
Support has also been added for the ext4 and Btrfs filesystems...
- "Linux kernel 3.0, Section 1.1. Btrfs: Automatic defragmentation, scrubbing, performance improvements". kernelnewbies.org. 21 July 2011. Retrieved 5 April 2016.
- Leemhuis, Thorsten (21 June 2011). "Kernel Log: Coming in 3.0 (Part 2) - Filesystems". The H Open. Retrieved 8 November 2011.
- Varghese, Sam. "iTWire". ITWire.com. Retrieved 19 April 2015.
- "Unbreakable Enterprise Kernel Release 2 has been released". Retrieved 8 May 2019.
- "SLES 11 SP2 Release Notes". 21 August 2012. Retrieved 29 August 2012.
- "SUSE Linux Enterprise Server 12 Release Notes". 5 November 2015. Retrieved 20 January 2016.
- "Red Hat Enterprise Linux 7.4 Release Notes, Chapter 53: Deprecated Functionality". 1 August 2017. Archived from the original on 8 August 2017. Retrieved 15 August 2017.
- "Considerations in adopting RHEL 8". Product Documentation for Red Hat Enterprise Linux 8. Red Hat. Retrieved 9 May 2019.
- "How to Choose Your Red Hat Enterprise Linux File System". 4 September 2020. Retrieved 3 January 2022.
- "Btrfs Coming to Fedora 33". Fedora Magazine. 24 August 2020. Retrieved 25 August 2020.
- "Btrfs Wiki: Features". btrfs.wiki.kernel.org. 27 November 2013. Retrieved 27 November 2013.
- "Btrfs Wiki: Changelog". btrfs.wiki.kernel.org. 29 May 2019. Retrieved 27 November 2013.
- "Manpage btrfs-check".
- "Using Btrfs with Multiple Devices". kernel.org. 7 November 2013. Retrieved 20 November 2013.
- "Compression". kernel.org. 25 June 2013. Retrieved 1 April 2014.
- "Btrfs: add support for inode properties". kernel.org. 28 January 2014. Retrieved 1 April 2014.
- "btrfs: Readonly snapshots". Retrieved 12 December 2011.
- "Save disk space on Linux by cloning files on Btrfs and OCFS2". Retrieved 1 August 2017.
- "Wiki FAQ: What checksum function does Btrfs use?". Btrfs wiki. Retrieved 15 June 2009.
- "Btrfs hilights in 5.5: new hashes". Retrieved 29 August 2020.
- "Btrfs progs release 4.6". Retrieved 1 August 2017.
- Mason, Chris (12 January 2009). "Btrfs changelog". Archived from the original on 29 February 2012. Retrieved 12 February 2012.
- Corbet, Jonathan (11 July 2012), Btrfs send/receive, LWN.net, retrieved 14 November 2012
- "Btrfs Wiki: Incremental Backup". 27 May 2013. Retrieved 27 November 2013.
- Jansen, Arne (2011), Btrfs Subvolume Quota Groups (PDF), Strato AG, retrieved 14 November 2012
- btrfs (16 July 2016). "RAID 5/6". kernel.org. Retrieved 1 October 2016.
- Zygo Blaxell. "How to use btrfs raid5 successfully(ish)". lore.kernel.org. Retrieved 26 June 2022.
- Zygo Blaxell. "Current bugs with operational impact on btrfs raid5". lore.kernel.org. Retrieved 26 June 2022.
- Corbet, Jonathan (5 May 2009). "The two sides of reflink()". LWN.net. Retrieved 17 October 2013.
- "UseCases – btrfs documentation". kernel.org. Retrieved 4 November 2013.
- "btrfs: allow cross-subvolume file clone". github.com. Retrieved 4 November 2013.
- Lenz Grimmer (31 August 2011). "Save disk space on Linux by cloning files on Btrfs and OCFS2". oracle.com. Archived from the original on 18 October 2013. Retrieved 17 October 2013.
- "Symlinks reference names, hardlinks reference meta-data and reflinks reference data". pixelbeat.org. 27 October 2010. Retrieved 17 October 2013.
- Meyering, Jim (20 August 2009). "GNU coreutils NEWS: Noteworthy changes in release 7.5". savannah.gnu.org. Retrieved 30 August 2009.
- Scrivano, Giuseppe (1 August 2009). "cp: accept the --reflink option". savannah.gnu.org. Retrieved 2 November 2009.
- – Linux Programmer's Manual – System Calls
- "SysadminGuide – Btrfs documentation". kernel.org. Retrieved 31 October 2013.
- "5.6 Creating Subvolumes and Snapshots [needs update]". oracle.com. 2013. Retrieved 31 October 2013.
- "Gotchas - btrfs Wiki". btrfs.wiki.kernel.org.
- "5.7 Using the Send/Receive Feature". oracle.com. 2013. Retrieved 31 October 2013.
- Mason, Chris (25 June 2015). "Conversion from Ext3 (Btrfs documentation)". kernel.org. Retrieved 22 April 2016.
- "btrfs-convert(8) — BTRFS Documentation". Retrieved 16 October 2022.
- "Seed device". Archived from the original on 12 June 2017. Retrieved 1 August 2017.
- Mason, Chris (5 April 2012), Btrfs Filesystem: Status and New Features, Linux Foundation, retrieved 16 November 2012
- McPherson, Amanda (22 June 2009). "A Conversation with Chris Mason on BTRfs: the next generation file system for Linux". Linux Foundation. Archived from the original on 27 June 2012. Retrieved 9 October 2014.
In future releases we plan to add online fsck, deduplication, encryption and other features that have been on admin wish lists for a long time.
- Sterba, David. "authenticated file systems using HMAC(SHA256)". Lore.Kernel.org. Retrieved 25 April 2020.
- "btrfs-check(8)". btrfs.readthedocs.io.
- "How to recover from BTRFS errors | Support | SUSE". www.suse.com. Retrieved 28 January 2023.
- "Restore - btrfs Wiki". btrfs.wiki.kernel.org.
- "btrfs-restore(8) - Linux manual page". man7.org. Retrieved 28 January 2023.
- "Problem FAQ - btrfs Wiki". kernel.org. 31 July 2013. Retrieved 16 January 2014.
- "kernel/git/torvalds/linux.git: Documentation: filesystems: add new btrfs mount options (Linux kernel source tree)". kernel.org. 21 November 2013. Retrieved 6 February 2014.
- "Mount options - btrfs Wiki". kernel.org. 12 November 2013. Retrieved 16 January 2014.
- Aurora, Valerie (22 July 2009). "A short history of btrfs". LWN.net. Retrieved 5 November 2011.
- Reiser, Hans (7 December 2001). "Re: Ext2 directory index: ALS paper and benchmarks". ReiserFS developers mailing list. Retrieved 28 August 2009.
- Mason, Chris. "Acp". Oracle personal web page. Retrieved 5 November 2011.
- "Hard Link Limitation". kerneltrap.org. 8 August 2010. Retrieved 14 November 2011.
- Fasheh, Mark (9 October 2012). "btrfs: extended inode refs". Archived from the original on 15 April 2013. Retrieved 7 November 2012.
- Torvalds, Linus (10 October 2012). "Pull btrfs update from Chris Mason". git.kernel.org. Archived from the original on 15 April 2013. Retrieved 7 November 2012.
- Larabel, Michael (24 December 2010). "Benchmarks of the Btrfs Space Cache Option". Phoronix. Retrieved 16 November 2012.
- "FAQ - btrfs Wiki: What checksum function does Btrfs use?". The btrfs Project. Retrieved 22 November 2020.
- Bierman, Margaret; Grimmer, Lenz (August 2012). "How I Use the Advanced Capabilities of Btrfs". Retrieved 20 September 2013.
- Salter, Jim (15 January 2014). "Bitrot and Atomic COWs: Inside "Next-Gen" Filesystems". Ars Technica. Retrieved 15 January 2014.
- Coekaerts, Wim (28 September 2011). "Btrfs Scrub – Go Fix Corruptions with Mirror Copies Please!". Retrieved 20 September 2013.
- "Glossary". Btrfs Wiki. Retrieved 31 July 2021.
- "Manpage/mkfs.btrfs". Btrfs Wiki. Profiles. Retrieved 31 July 2021.
- Mason, Chris; Rodeh, Ohad; Bacik, Josef (9 July 2012), BTRFS: The Linux B-tree Filesystem (PDF), IBM Research, retrieved 12 November 2012
- Mason, Chris (30 April 2008). "Multiple device support". Btrfs wiki. Archived from the original on 20 July 2011. Retrieved 5 November 2011.
- Bartell, Sean (20 April 2010). "Re: Restoring BTRFS partition". linux-btrfs (Mailing list).
- "Oracle Now Supports Btrfs RAID5/6 on Their Unbreakable Enterprise Kernel - Phoronix". Phoronix.com.
- "Managing Btrfs in Oracle Linux 8". docs.oracle.com. Retrieved 6 June 2020.
- "SUSE Reaffirms Support for Btrfs". LWN.net.
- "SUSE Linux Enterprise Server 12 Release Notes". SUSE.com. Retrieved 28 February 2021.
- "Cloud Station White Paper" (PDF). Synology.com. Synology. p. 11. Archived from the original (PDF) on 11 November 2020. Retrieved 2 April 2021.
Starting from DSM 6.0, data volumes can be formatted as Btrfs
- "Btrfs has been deprecated in RHEL | Hacker News". News.YCombinator.com.
- "Red Hat Appears to Be Abandoning Their Btrfs Hopes - Phoronix". Phoronix.com.
External links
- Official website

- I Can't Believe This is Butter! A tour of btrfs on YouTube – a conference presentation by Avi Miller, an Oracle engineer
- Btrfs: Working with multiple devices – LWN.net, December 2013, by Jonathan Corbet
- Marc's Linux Btrfs posts – detailed insights into various Btrfs features
- Btrfs overview, LinuxCon 2014, by Marc Merlin
- File System Evangelist and Thought Leader: An Interview with Valerie Aurora[Usurped!], Linux Magazine, 14 July 2009, by Jeffrey B. Layton
- WinBtrfs Btrfs Driver For Windows
| Organization |
| ||||
|---|---|---|---|---|---|
| Technical | |||||
| Adoption |
| ||||
| Linux kernel | |
|---|---|
| Controversies | |
| Distributions | |
| Organizations | |
| Adoption | |
| Media | |
| Professional related certifications | |